After install Redis you don’t have any settings configured to control memory consumption. In Production this brings OOM to the arena which leads into a broken applications.
First thingy what users do is to configure MaxMemory config setting (like me of course ;-)). In combination with a noeviction policy (which is also the default) the documentation says:
[…] return errors when the memory limit was reached and the client is trying to execute commands that could result in more memory to be used (most write commands, but DEL and a few more exceptions).
The bad news is, you’ll have a broken application again. Most web apps just use Redis as an uncontrolled cache data sink and left over to you how to handle it. For 99.9% of the use-cases you just need to configure a cache policy, or in Redis-speech, an Eviction Policy, which means:
maxmemory 128mb maxmemory-policy allkeys-lru maxmemory-samples 10
1. You allow roughly 128MB of memory for Redis
2. Redis tries to remove the less recently used (LRU) keys first
3. Because LRU is not a exact LRU algo, you use 10 samples to help the algorithm to find the items
Try to explain by counters:
Icinga Redis Plugin Output:

Above is a icinga redis check plugin output. Which shows a roundabout memory use of 108% – which is more than the configured 128M 100% base.
Grafana Graph (Telegraf Redis Input Plugin)
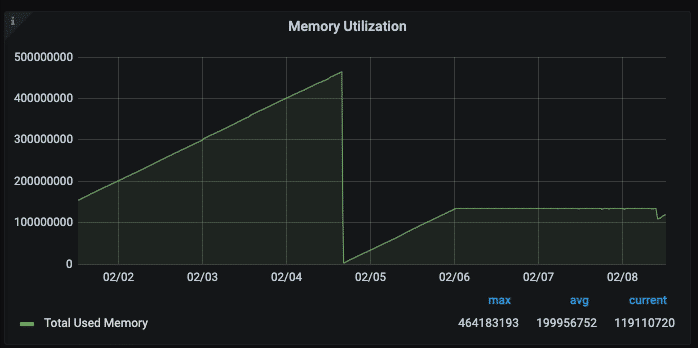
Here is the config change made on the 02/04 down to 128M MaxMemory and the LRU Eviction Policy. The memory footprint stays the same. The change is more granular if you zoom in:
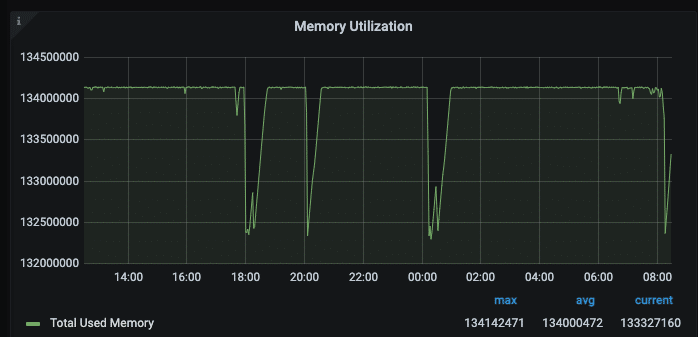
If the allkeys-lru does not work for you, give the documentation a try. There is a lot you can do to keep your applications up and running and make Redis a fluently easy dependency.





















