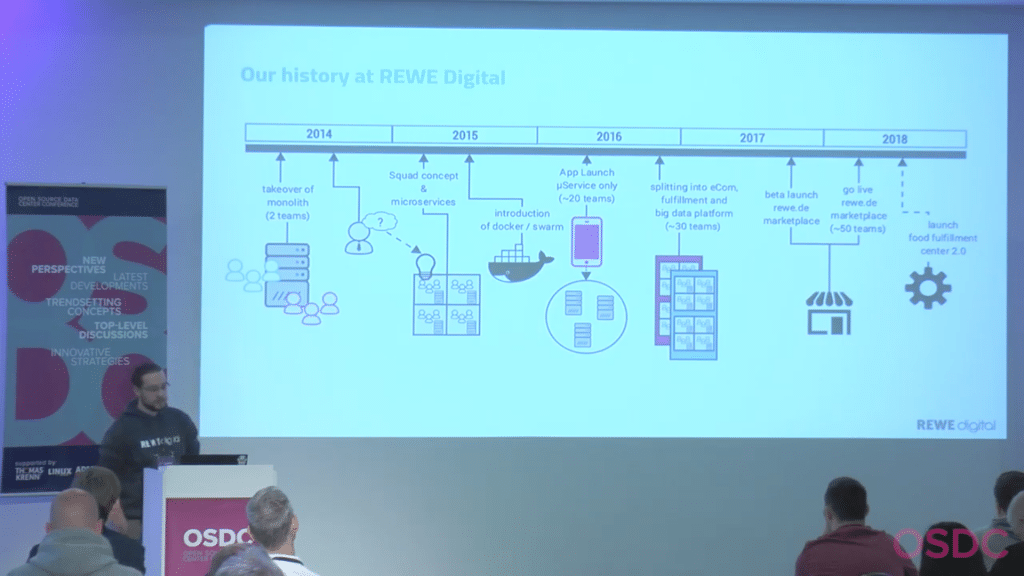
This talk is about our journey from Nginx & Docker Swarm to Traefik & Nomad. At the Open Source Data Center Conference (OSDC) 2019 in Berlin, Jan Martens invited to audience to travel with him in his talk „Evolution of a Microservice-Infrastructure”. You have missed him speaking? We got something for you: See the video of Michael’s presentation and read a summary (below).
The former OSDC will be held for the first time in 2020 under the new name stackconf. With the changes in modern IT in recent years, the focus of the conference has increasingly shifted from a mainly static infrastructure approach to a broader spectrum that includes agile methods, continuous integration, container, hybrid and cloud solutions. This development is taken into account by changing the name of the conference and opening the topic area for further innovations.
Due to concerns around the coronavirus (COVID-19), the decision was made to hold stackconf 2020 as an online conference. The online event will now take place from 16 to 18 June 2020. Join us, live online! Save your ticket now at: stackconf.eu/ticket/
Kubernetes Custom Resources with Kubeless and Metacontroller
Mostly Michael is working with all the Kubernetes stuff in his company (also with Foreman). Developing additional tools e.g. scripts and tools for deploy applications. Custom Resources from Kubernetes and how to use them.
The goal of Michael‘s talk: Create your own Kubernetes resources that look like, behave like and can be used like every other Kubernetes resource. For example, if you want to let your users manage helm for Kubernetes, you have to give them access to your instance, what means, they can control the hole cluster. That’s not what you want.
The recipe:
- A resource definition
- Some logic to make it do something
- Some API magic to make it all stick together
1) Resource definition
CustomResourceDefinition = It is used to tell Kubernetes about your new resource.
It consists of three parts:
- API group
- some metadata
- the kind (the name of your resource)
2) Some logic to make it to something
For this, Michael uses a tool called Kubeless. It is a so called function as a service framework. It is basically a framework where you can say ‘Here is my code, make it work as a webservice’. (That’s a very oversimplified description of what it is, but for the use case in this presentation it is enough.)
Use Kubeless to create our actual resource logic in form of a web service. How do we do that? As everytime in Kubernetes we use a Kubernetes resource (in this case it is a function).
Example:
- API
- kind (function)
- metadata (name, namespace, etc.)
- spec (runtime, handler, checksum, function-content-type, the actual function)
The function (logic) can now be found at .
3) Some API magic to make it all stick together
How to connect your custom resource with your logic? As always, we use a Kubernetes resource. The special feature here is to give the resource the parentResource, that means, the apiVersion of the custom resource. We also have to tell, what childResource it has to create. In our case just “pods”.
Furthermore, we have to define what to do if the resource changes. For example, what should happen if we change the parent resource or add some configuration? At the end of the configuration we have to tell where to find the logic we built. In our example it is .
And this ties our two pieces together. It connects our custom resource definition with our logic. Now we have on the right our logic, on the left our resource definition and meta controller for the communication in the middle.
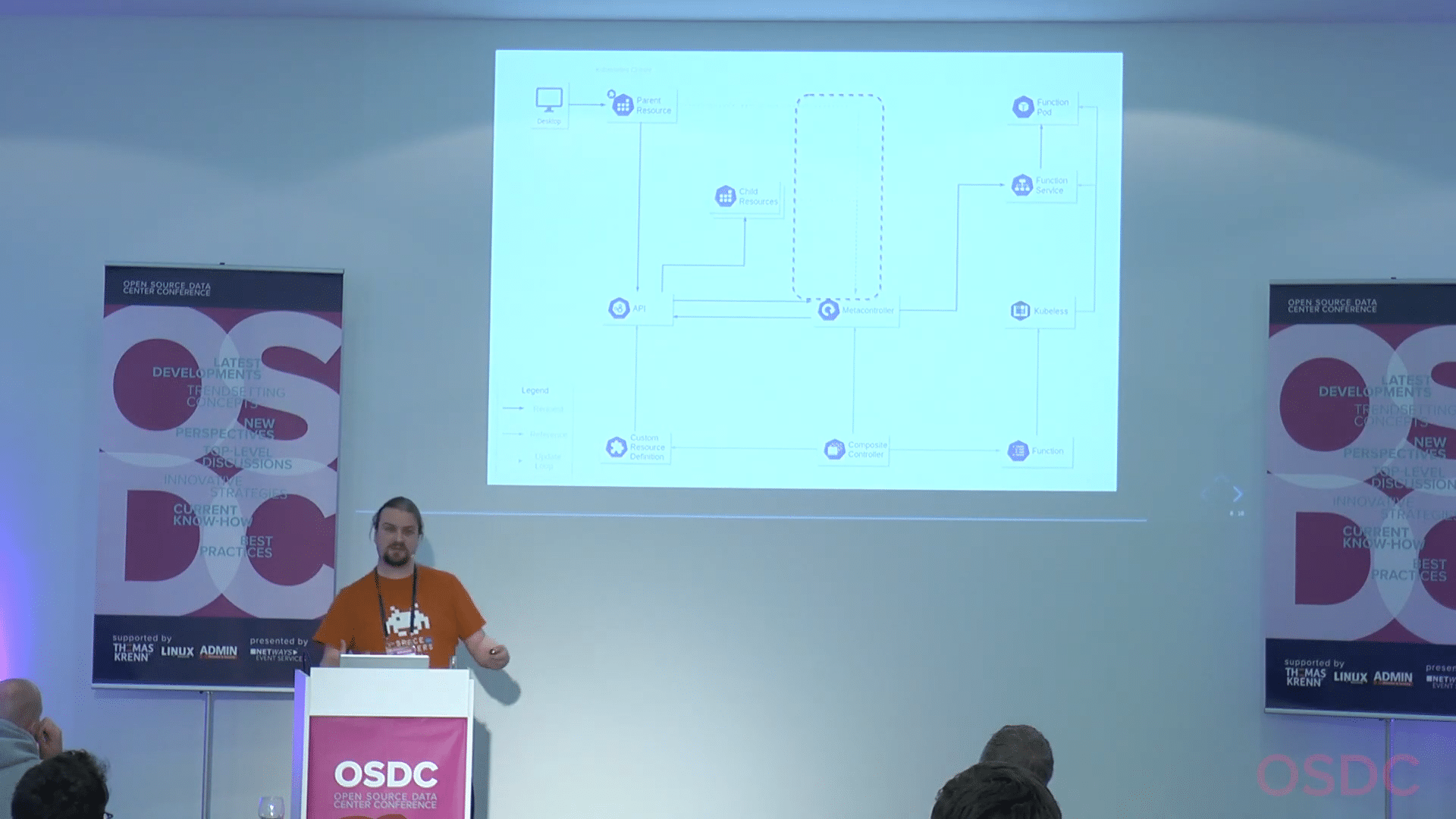
If the user now creates a new instance of our custom resource, the logic gets notified by the API, that ensures the meta controller gets notified. After this, the meta controller calls our function and returns a JSON structure containing the status and the list of children. Meta Controller then uses these information to do whatever API requests are necessary to create these children.
If you are interested now, watch the full video to have a look at a live demo how this works!