Beim Betrieb von Computerinfrastrukturen treten früher oder später Probleme auf. Typischerweise schon bei der Einrichtung und später bei Änderungen, aber auch im “Normalbetrieb”. Die Ursachen dafür sind entweder extern, intern oder eine Mischung aus beidem. Zu regelmäßig auftretenden externen Ursachen zählen zum Beispiel eine Änderung des Kontextes der Maschinen, wie etwa ein Strom- und/oder Netzwerkausfall oder Updates, die etwas am äußeren Verhalten eines Programmes ändern.
Aber auch schlicht der Fortlauf der Zeit muss hier erwähnt werden. Eine tragische und unaufhaltsame Gewissheit, die durchaus technische Bedeutung hat, etwa in der Gültigkeit von Zertifikaten oder Problemen mit der Zeitsynchronisation.
Intern können Probleme durch eine bestehende Fehlkonfiguration entstehen. Dieser Begriff ist jedoch etwas Vorsicht zu genießen, da es durchaus Szenarien gibt, in denen eine bestimmte Konfiguration zum Zeitpunkt der Entstehung durchaus richtig und angemessen war. Oftmals zeigt sich erst im Verlauf von Monaten oder Jahren oder durch Änderung des Kontextes, dass die damals “richtigen” Einstellungen problematisch sind.
An dieser Stelle tritt Monitoring auf den Plan und nimmt seinen Platz in einer gut geplanten IT-Infrastruktur ein. Enterprise-Monitoringlösungen wie Icinga versuchen bei der Voraussage, Entdeckung und Behebung von Problemen zu helfen. Um dir einen guten und vielfältigen Eindruck von den Möglichkeiten eines gut eingerichteten Monitoringtools zu geben, gehe ich in diesem Blogpost auf einige klassische und häufige Probleme, speziell im Kontext von Linux (und damit häufig auch anderen unixoiden Betriebssystemen) ein.
Im Laufe meines Beitrags werde ich regelmäßig auf die Monitoring Plugins eingehen, da diese beim Erkennen von Problemen eine wichtige Rolle spielen. Diese Zusammenstellung an Plugins ist neben Icinga auch für den Einsatz mit anderen Monitoring-Systemen geeignet, solange diese die Monitoring Plugins unterstützen.
Gängige Probleme auf Linux-Maschinen und Monitoringlösungen mit Icinga
Dateisysteme erreichen die Kapazitätsgrenzen
Ein nicht sehr häufiges (bezogen auf die Auftretenswahrscheinlichkeit), aber fatales Problem ist ganz klassisch, dass im Betrieb ein Dateisystem bis an die Kapazitätsgrenzen vollläuft. Dies führt üblicherweise dazu, dass das System seinen Betrieb ganz oder teilweise einstellt, jedoch ist das Fehlerbild potenziell auf den ersten Blick nicht offensichtlich. Beispielsweise können Programme keine großen Dateien mehr anlegen, beziehungsweise wird das Schreiben derselben abgebrochen, aber kleine, temporäre Dateien sind vielleicht (für den Moment) noch möglich.
Das führt je nach betrachteter Software und deren Fehlerbehandlung dazu, dass erst mal noch alles in Ordnung erscheint. Ein Webdienst wird weiterhin ansprechbar sein und kleine Abfragen durchaus beantworten, dann aber bei anderen (bei denen dann versucht wird größere Dateien zu schreiben) die Bearbeitung abbrechen und nur noch Fehler ausgeben, aber nicht vollständig abstürzen.
Ein anderes Beispiel ist eine Datenbank, die zwar noch lesende Zugriffe durchführen kann, aber eben keine Schreibenden. In diesen Fällen wird ein einfacher Test auf die Funktionalität des Dienstes (das init-System des Systems bescheinigt, dass der Dienst läuft; entsprechende Anfragen auf bestimmten Ports werden noch angenommen) ein positives Ergebnis bescheinigen. Trotzdem ist die eigentliche Hauptfunktionalität nicht mehr gegeben.
In einem typischen Szenario, in dem die Checks für das System lokal (oder aus der Ferne über gängige Transportwege wie SSH) ausgeführt werden, ist die klassische und gängigste Wahl beim Monitoring mit Icinga check_disk ( aus den Monitoring Plugins (Debian- und Suse-artige Distributionen) bzw. nagios-plugins (RedHat-Familie)). Zwar ist die Benutzung teilweise etwas ungewöhnlich (Stichwort Gruppierung), aber für unkomplizierte Dateisystem-Setups (und damit die häufigsten) durchaus noch ausreichend.
Ein typischer Aufruf könnte etwa so aussehen:
# ./plugins/check_disk -w 2% -c 1% \
-X none -X tmpfs -X fuse.portal -X fuse.gvfsd-fuse \
-X sysfs -X proc -X squashfs -X devtmpfs
DISK OK - free space: / 32892MiB (58% inode=83%); /boot 257MiB (57% inode=99%); /var 147782MiB (65% inode=92%); /home 154929MiB (34% inode=96%); /boot/efi 503MiB (98% inode=-);| /=24961351680B;61414781747;62041463193;0;62668144640 /boot=197132288B;482974105;487902412;0;492830720 /var=83065044992B;245826626519;248335061483;0;250843496448 /home=314740572160B;492755872645;497783993794;0;502812114944 /boot/efi=7340032B;524078284;529426022;0;534773760
# ./plugins/check_disk -w 2% -c 1% -N ext2 -N ext4
DISK OK - free space: / 32892MiB (58% inode=83%); /boot 257MiB (57% inode=99%); /var 147782MiB (65% inode=92%); /home 154935MiB (34% inode=96%);| /=24961351680B;61414781747;62041463193;0;62668144640 /boot=197132288B;482974105;487902412;0;492830720 /var=83065044992B;245826626519;248335061483;0;250843496448 /home=314734280704B;492755872645;497783993794;0;502812114944In diesem Beispiel werden die Grenzwerte für Dateisysteme so gesetzt, dass der Warnzustand bei weniger als zwei Prozent freiem Speicherplatz und der Kritische bei weniger als einem Prozent auftritt. Die Sammlung an -X-Parametern (beziehungsweise das komplementäre -N) schließt diverse Dateisystemtypen aus, die nicht geprüft werden sollen. Die von mir in diesem Beispiel ausgeschlossenen Dateisystemtypen fallen nicht unter die Kategorie, die man hier im Auge hat. Hierbei handelt es sich um Dateisysteme die meine Dateien persistent auf magnetische Platten oder Halbleiterspeicher fixieren.
Alternativ können check_disk gezielt ein oder mehrere Befestigungspunkte übergeben werden:
./plugins/check_disk -w 2% -c 1% -p /home -p /boot
DISK OK - free space: /home 154935MiB (34% inode=96%); /boot 257MiB (57% inode=99%);| /home=314733232128B;492755872645;497783993794;0;502812114944 /boot=197132288B;482974105;487902412;0;492830720Zur Feinjustierung existieren noch mehr Optionen, ein check_disk --help kann sehr hilfreich sein. Das Setzen von Grenzwerten für die Benutzung von Inodes mittels -W und -K ist leider ein viel zu häufig vergessenes Problem. Ein Mangel an freien Inodes bietet ein sehr ähnliches Bild wie eine Mangel an freiem Platz, jedoch ist es weniger offensichtlich (und tritt auch deutlich seltener auf).
Alternativen zu check_disk sind diverse andere Monitoring Plugins, wie etwa disk_usage der Linuxfabrik. Damit wird zu großen Teilen dieselbe Problematik abgedeckt. Weiterhin gibt es Plugins, die Rand- oder Sonderfälle behandeln, die außerhalb des Funktionsumfangs der klassischen Plugins liegen.
Sonderfälle dieser Art wären etwa kompliziertere Setups mit Dateisystemen mit einer größeren Menge an Funktionen wie etwas btrfs, xfs oder zfs. Hier ist eine einfache Aussage, wie die von mir bereits betrachtete “Wie viel Platz ist frei/belegt?” nicht so einfach zu treffen. Als wäre das noch nicht genug, gibt es hierbei noch die Problematik von Netzwerk- und verteilten Dateisystemen, die auch etwas komplexer ist.
TLDR
Mindestens das root-Dateisystemen sollte mit check_disk oder etwas Ähnlichem überwacht werden, als Checkintervall reichen fünf Minuten locker aus. Zusätzliche Dateisysteme für das Persistieren von Daten sollten äquivalent überwacht werden. Auch sollte überwacht werden, ob noch genügend Inodes frei sind.
Swapping
Swap-Speicher ist ein Bereich im Langzeitspeicher, der zur Auslagerung von Arbeitsspeicherinhalten dienen kann (Stichwort “Auslagerungsdatei” unter Windows). In Zeiten von sehr limitierter Arbeitsspeicherkapazität eine nützliche Funktion, um kurzfristige Kapazitätsengpässe handhaben zu können, ohne Nutzerprogrammen den angeforderten Speicher zu verweigern. Zusätzlich dient der Swap-Bereich heutzutage oft als Speicherort für Arbeitsspeicherinhalte, wenn eine Maschine in einen Ruhezustand versetzt und der (physikalische) Arbeitsspeicher ebenfalls außer Betrieb geht (Stichwort: “Hibernation”).
Diese Möglichkeiten kommen natürlich mit einem Preis. Festspeicher (“long term storage”) ist immer noch um Größenordnungen langsamer als Arbeitsspeicher (der wiederum deutlich langsamer als die
Speicher (“L*-Caches”) in der CPU ist). Die Auslagerung von aktiv genutzten Arbeitsspeicherinhalten kann dazu führen, dass ein System langsam bis an die Grenze der Benutzbarkeit gebracht wird. Das ist bei einem PC störend und frustrierend, kann jedoch bei Produktivmaschinen teilweise noch schlimmere Konsequenzen haben.
Eine Maschine, die ohnehin gerade unter Last steht, weil sie zum Beispiel sehr viele Abfragen erhält, wird, wenn das Swapping beginnt, sehr viel langsamer werden, was dann die Belastung typischerweise nicht senkt. Es sollte deshalb sichergestellt sein, dass die Nutzung von Swapspeicher (im Normalbetrieb) sowohl in Hinsicht der Quantität (Prozent an freiem/benutzten Speicher) als auch im zeitlichen Rahmen begrenzt ist.
Klassisch bietet sich hier check_swap (wiederum Monitoring Plugins|nagios-plugins) an, beispielsweise:
# ./plugins/check_swap -w 60% -c 20%
SWAP OK - 100% free (36863MB out of 36863MB) |swap=38653657088B;23192194200;7730731400;0;38653657088In diesem Beispiel wird getestet, ob weniger als 60 Prozent des Swapspeichers frei ist (Grenzwert für WARNING) bzw. 20 Prozent (Grenzwert für CRITICAL). Eine temporär hohe Nutzung mag (je nach Szenario) durchaus erlaubt sein, aber längerfristig dürfte dies ein Problem darstellen.
Als groben Richtwert könnte man vielleicht fünfzehn Minuten anlegen, nach denen jemand alarmiert werden sollte. Das Checkintervall dürfte mit ein, zwei oder drei Minuten ausreichend bedient sein.
Wie hoch ist die Systemlast?
Ganz generell sind Systemressourcen limitiert, seien es CPU-Zeit, Speicher, andere Prozessoren und natürlich die ganzen Schnittstellen dazwischen. Manchmal lässt sich nicht oder nur schlecht an einzelnen kleinen Metriken ablesen, wenn ein Engpass besteht, zumindest wenn die Werte nur eine Teilmenge aller Werte darstellen und die wichtigen Metriken nicht enthalten sind. In unixoiden Systemen gibt es aus diesen und anderen Gründen die load-Metrik, die zwar die Details vermissen lässt, aber zuverlässig einen Indikator für ein Problem liefert.
Händisch kann die load mit dem Programm uptime (beispielsweise) abgerufen werden:
# uptime
12:21:58 up 1:25, 1 user, load average: 0.40, 0.38, 0.23Die load besteht hier aus den drei Zahlenwerten 0.40,0.38 und 0.23, mit einem Aggregatswert über eine Minute, fünf Minuten und fünfzehn Minuten.
Alternativ direkt aus dem Proc-Dateisystem:
# cat /proc/loadavg
0.00 0.06 0.12 1/1316 27272Und in “proc (5)” findet sich dann auch eine Erklärung der Zahlen.
Wer sich jetzt nicht jedes Mal die Arbeit machen will, diese Werte mit einem händisch eingegebenen Befehl aufzurufen und auszulesen, kann auf eine automatisierte Überwachung durch Check-Plugins, in diesem Fall check_load (Monitoring Plugins|nagios-plugins) setzen. Die Grenzwerte sind in diesem Fall etwas schwierig zu bestimmen, da die “zu hohe Last” stark vom Kontext abhängt.
Generell lässt sich sagen, dass eine load von eins fast der Idealwert ist, da sich damit (im Durchschnitt) immer ein Prozess in der Warteschlange befindet.
Für Werte größer als eins wird die Beurteilung schwieriger. Die Zahlenwerte aus meinem Beispiel stammen von einem Laptop ohne größere Aktivitäten (nur zwei Webbrowser). Für eine größere Maschine, etwa einen Datenbankserver mit 16 (oder mehr) CPU-Kernen, kann ein Wert von 40 auch normal sein und durchaus noch einen akzeptablen Betriebszustand darstellen. Die Option -r für check_load dividiert die load-Werte durch die Anzahl der CPU-Kerne, um eine gewisse “Normalisierung” der Werte zu erreichen, die meistens angemessen ist.
Ein angemessenes Monitoring wäre ein Checkintervall von einer bis drei Minuten mit Benachrichtigung nach fünfzehn Minuten. Als Grenzwerte wären 3,3,3 für WARNING und 5,5,5 für CRITICAL als einigermaßen konservative Einschätzung angemessen.
Ausfälle von Services (systemd) und Prozessen
In den meisten Fällen stellen Maschinen Dienste für Menschen oder andere Maschinen bereit und es ist normalerweise von gesteigertem Interesse, ob dieser Dienst auch läuft. In den meisten Linux-Distributionen ist systemd als Event- und Servicemanager im Einsatz und sollte dazu benutzt werden, durchgängig laufende Programme zu verwalten.
Mittels check_systemd lässt sich ermitteln, ob Dienste (bzw. generalisiert, systemd-units) in einem fehlerhaften Zustand sind oder nicht.
Dazu ein Beispiel mit dem SSH-Serverdienst (openssh):
# ./check_systemd.py -u ssh
SYSTEMD OK - ssh.service: active | count_units=490 data_source=cli startup_time=6.193;60;120 units_activating=8 units_active=332 units_failed=2 units_inactive=148Im Hintergrund sind Dienste am Ende aber auch “nur” Prozesse und du möchtest potenziell diverse Eigenschaften von Prozessen überprüfen (etwa CPU-Nutzungszeit (in Prozent), oder die Größe des benutzten Speicherbereichs). Erste Anlaufstelle ist für mich check_procs.
Beispielsweise kannst du damit überprüfen, ob Zombieprozesse vorhanden sind:
# ./plugins/check_procs -s Z -w 1
PROCS OK: 0 processes with STATE = Z | procs=0;1;;0;Ein weiterer Anwendungsfall ist die Überprüfung aller Prozesse, die mehr als zwei Prozent der CPU-Zeit verschlingen:
# ./plugins/check_procs --metric CPU -w 2
CPU WARNING: 1 warn out of 310 processes | procs=310;;;0; procs_warn=1;;;0; procs_crit=0;;;0;Dateieigenschaften – warum Probleme auftreten können
An vielen Stellen muss überprüft werden, ob eine oder mehrere Dateien vorhanden sind und/oder bestimmte Eigenschaften aufweisen, beispielsweise ob sie älter oder jünger als ein gewisses (relatives) Datum sind, größer oder kleiner als ein Grenzwert sind oder bestimmte Berechtigungen haben. Die Ergebnisse einer solchen Überprüfung können als Indikator für ein Problem in einem Programm dienen, etwa, dass Dateien in einem Spooler-Verzeichnis nicht schnell genug abgeholt werden.
Glücklicherweise ist das ein Bereich, der sich relativ einfach durch selbstgeschriebene, auf den Nutzungsfall abgestimmte Skripte abdecken lässt. Wenn man den passenden find Befehl zusammengebaut hat, kann man nach den Monitoring Plugins Guidelines dann ein Monitoring Plugin bauen, dass den eigenen Spezialfall abdeckt.
Für etwas generellere Fälle gibt es mit check_file_age aber bereits eine Option, die zumindest das Überprüfen auf Alter und Größe erlaubt.
# ./plugins-scripts/check_file_age -f plugins-scripts/check_file_age -w 300:30000000 -c 1: -W 1:300
FILE_AGE WARNING: plugins-scripts/check_file_age is 516096 seconds old and 5193 bytes | age=516096s;300:30000000;1: size=5193B;1:300;0:;0In diesem Beispiel sollte die Datei plugin-scripts/check_file_age älter als eine Sekunde sein (kritische Bedingung), zwischen 300 und 30000000 Sekunden alt (Bedingung für den WARNING-Zustand) und zwischen einem und 300 Bytes gross (zweite Bedingung für WARNING).
Für alle die es etwas vielfältiger mögen, wären die Monitoring Plugins der Linuxfabrik, die mit file beginnen, eine Option.
Schlusswort
Die angesprochenen Probleme sind natürlich nur ein kleiner Teil der möglichen Problemstellungen, mit denen man als Systemadministrator konfrontiert wird. Zudem habe ich mich für diesen Beitrag auch ausschließlich auf Themen innerhalb einer Maschine limitiert. Die Thematik der Netzwerkproblembehandlung hätte den Rahmen mehr als gesprengt, bietet aber ein gutes Thema für weitere Blogposts.
Ich hoffe, ich konnte anhand meiner gewählten Beispiele verdeutlichen, welche Möglichkeiten der Einsatz von Monitoringlösungen wie Icinga bietet, besonders dann, wenn du ein Unix-basiertes Rechner- oder Servernetz betreibst. Und auch wenn ich mich im Rahmen dieses Posts auf die Ausführung der Checks über die Konsole beschränkt habe, lass dich davon bitte nicht abschrecken. Natürlich können all diese Eingaben auch (bis zu einem gewissen Punkt) mit der grafischen Lösung Icinga Director und die Weboberfläche Icinga Web durchgeführt werden.
Falls du und dein Unternehmen jetzt noch Hilfe bei der Einrichtung und Konfiguration von Icinga benötigt, lass es uns einfach wissen!
In der Zwischenzeit, bleibt zu hoffen dass diese Lektüre jemandem geholfen hat und wenn (aber auch wenn nicht), dann würde sich der Autor über Kommentare freuen.


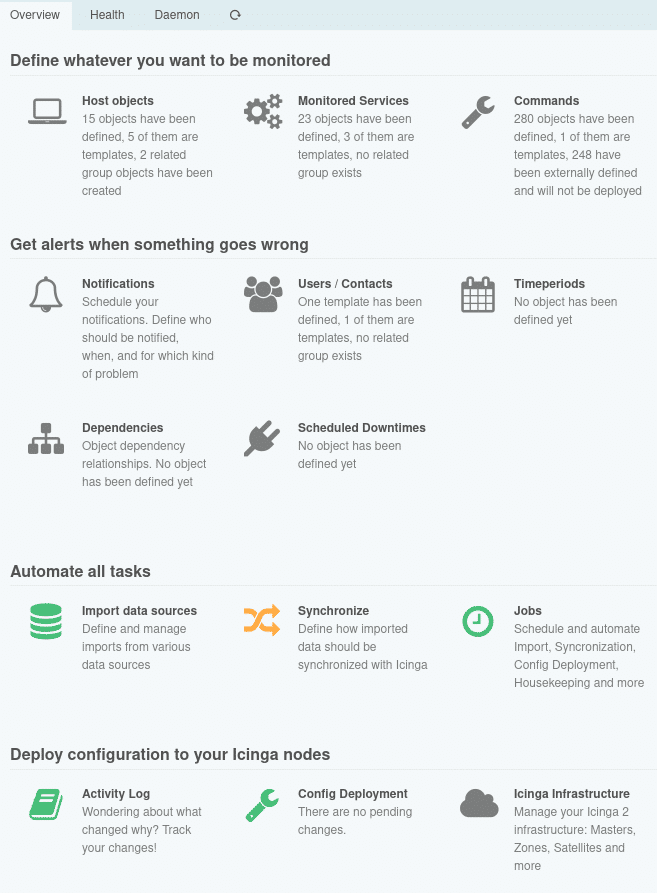 Der Icinga Director als grafisches Frontend zur Konfiguration stellt eine Abstraktion der Icinga DSL dar, denn es müssen natürlich für alle Objekte mit allen Attributen Eingabemasken existieren. Um das noch etwas klarer zu machen, gebe ich Dir einen kurzen Einblick in die Funktionsweise des Icinga Directors. Der Director importiert von einer Icinga-Instanz grundlegende Objekte wie Check-Kommandos, Endpunkte und Zonen. Nach diesem Kickstart musst Du für die allermeisten Objekte zunächst Templates anlegen, wobei direkt Felder für zusätzliche Eigenschaften zu erstellen und anzuhängen sind. Sobald Du auch konkrete Objekte angelegt hast, kannst Du die Konfiguration für Icinga rendern und über den entsprechenden API-Endpunkt produktiv nehmen.
Der Icinga Director als grafisches Frontend zur Konfiguration stellt eine Abstraktion der Icinga DSL dar, denn es müssen natürlich für alle Objekte mit allen Attributen Eingabemasken existieren. Um das noch etwas klarer zu machen, gebe ich Dir einen kurzen Einblick in die Funktionsweise des Icinga Directors. Der Director importiert von einer Icinga-Instanz grundlegende Objekte wie Check-Kommandos, Endpunkte und Zonen. Nach diesem Kickstart musst Du für die allermeisten Objekte zunächst Templates anlegen, wobei direkt Felder für zusätzliche Eigenschaften zu erstellen und anzuhängen sind. Sobald Du auch konkrete Objekte angelegt hast, kannst Du die Konfiguration für Icinga rendern und über den entsprechenden API-Endpunkt produktiv nehmen.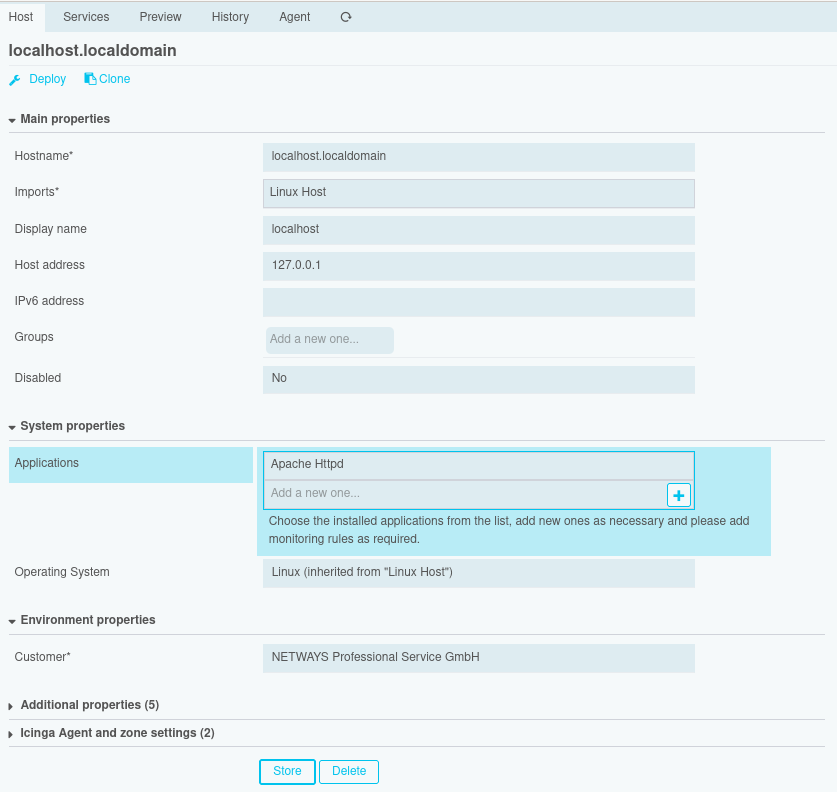 Auf der Trennung von Templates und Objekten baut auch das Rechtesystem des Directors auf, denn der Zwang zur Erstellung von Templates bereitet auch eine entsprechende Rollentrennung vor. So soll gewährleistet werden, dass ein Monitoring-Administrator ganz leicht Vorgaben machen kann und beispielsweise der Linux-Administrator anschließend einfach seine Hosts einpflegen braucht. Wer darauf geachtet hat, dem ist hier mein zögerliches Zugestehen aufgefallen. Denn ein Nachteil, den ich nicht verschweigen möchte, ist leider die Dokumentation des Directors. Alles Grundsätzliche ist in der Dokumentation durchaus enthalten. Manche Details jedoch werden erst durch Ausprobieren klar und Best Practices kristallisieren sich erst mit einiger Erfahrung heraus.
Auf der Trennung von Templates und Objekten baut auch das Rechtesystem des Directors auf, denn der Zwang zur Erstellung von Templates bereitet auch eine entsprechende Rollentrennung vor. So soll gewährleistet werden, dass ein Monitoring-Administrator ganz leicht Vorgaben machen kann und beispielsweise der Linux-Administrator anschließend einfach seine Hosts einpflegen braucht. Wer darauf geachtet hat, dem ist hier mein zögerliches Zugestehen aufgefallen. Denn ein Nachteil, den ich nicht verschweigen möchte, ist leider die Dokumentation des Directors. Alles Grundsätzliche ist in der Dokumentation durchaus enthalten. Manche Details jedoch werden erst durch Ausprobieren klar und Best Practices kristallisieren sich erst mit einiger Erfahrung heraus. Für mich ist schlussendlich meistens nicht entscheidend, wie einzelne Objekte konfiguriert werden können, da ich im Idealfall das Monitoring gar nicht manuell pflegen möchte. Und hier kommt eine der größten Stärken des Directors zum tragen: Der Director bietet die Möglichkeit, Daten aus einer Datenquelle zu importieren und aus diesen Daten dann Monitoring-Objekte zu erzeugen. Dabei können sogar noch Modifikatoren genutzt werden, um die Daten für den Verwendungszweck anzupassen.
Für mich ist schlussendlich meistens nicht entscheidend, wie einzelne Objekte konfiguriert werden können, da ich im Idealfall das Monitoring gar nicht manuell pflegen möchte. Und hier kommt eine der größten Stärken des Directors zum tragen: Der Director bietet die Möglichkeit, Daten aus einer Datenquelle zu importieren und aus diesen Daten dann Monitoring-Objekte zu erzeugen. Dabei können sogar noch Modifikatoren genutzt werden, um die Daten für den Verwendungszweck anzupassen.
















