OpenSearch: Ordnung muss sein! III
In der letzten Runde haben wir uns mit der Einlieferung der Daten und der ersten Schritte im OpenSearch Dashboards gewidmet. Heute wollen wir uns einmal mit der Haushaltung der Informationen befassen. Der erste wichtigste Unterschied ist die Bezeichnung. Im Elasticsearch sprechen wir vom ILM (Index Lifecycle Management), wohin gegen wir im OpenSearch Plugin von ISM (Index State Management) sprechen. Beide behandeln aber den selben Nenner “Policies” für die Verwaltung der Vorhaltung der Daten.
ISM erklärt
Leider ist die Dokumentation zur ISM nach wie vor sehr Schlank. Alle Teile sind sehr knapp beschrieben.
Eine ISM Policy gliedert sich wie folgt auf:
- Policy Info: ID und Beschreibung
- Error Notification: Benachrichtigungen bei Fehlschlag
- ISM Templates: Hier werden die Index-Pattern definiert, auf die die ISM Policy angewendet werden soll
- Hierbei ist wichtig, dass der Index initial mit einem Hyphen Suffix angelegt wird z.B./e.g.: “myindex-00001” (Regex-Muster: `^.*-\\d+$`)
- States: Mit States werden die einzelnen Phasen eines Index definiert. In den States werden “Actions” und “Transitions” gesetzt. Die Transition kann zum Beispiel einer Action Rollover folgen, um den Index in den nächsten State zu setzen. In dem neuen State wird der Index dann zum Beispiel auf “Read Only” gesetzt oder der “Replica Count=0” gesetzt.
Ring frei
Wir wollen uns das ganze mal an einem Beispielablauf anschauen. Leider war es für mich mit den bisher genutzten Mitteln nicht 100% automatisierbar, auch die Hilfen im Forum und dem restlichen Web waren nicht sehr aufschlussreich. Folgend setzten wir uns mit dem erstellen eines ISM mit entsprechenden Rollover, dass was wir in der Produktion immer wollen.
Bedingungen für die Runde
Einlieferung
Zur Einlieferung nutzen wir den Fluent Bit wie folgt Konfiguriert:
[code lang=”plain”]
[INPUT]
name cpu
tag cpu.local
# Read interval (sec) Default: 1
interval_sec 1
[INPUT]
name tail
path /tmp/json-output
parser json
[OUTPUT]
name opensearch
match *
host 192.168.2.42
port 9200
index fluentbit-000001
type _doc
http_user admin
http_passwd admin
tls On
tls.verify Off
[/code]
Wichtig ist hier beim Output, dass wir entsprechend Initial einen Hyphen am Ende mit einem Pattern haben welches sich hochzählen lässt.
Index Template für den Rollover
Für das Rollover handling setzen wir einen Rollover-alias. Dieser muss gesetzt sein. Dies regeln wir über ein Template
[code lang=”plain”]
PUT _index_template/ism_rollover
{
"index_patterns": ["fluentbit-*"],
"template": {
"settings": {
plugins.index_state_management.rollover_alias": "fluentbit"
}
}
}
[/code]
Hier ist es wichtig keinen Index-Alias zu setzen dieser wird nach dem des Start des ISM-Init auf den index manuell gesetzt. Das ist sehr wichtig. Denn wenn wir den alias im template definieren, dann bekommen wir keinen rollover. Der folgende Fehler wäre dann der Fall:
[code lang=”plain”]
Rollover alias [fluentbit] can point to multiple indices, found duplicated alias [[fluentbit]] in index template [ism_rollover]
[/code]
Anlegen der Policy
Nun können wir unsere Policy anlegen.
Aufgrund der Übersichtlichkeit erkläre ich hier das ganz im JSON:
[code lang=”plain”]
{
"id": "test_flow",
"seqNo": 603481,
"primaryTerm": 10,
"policy": {
"policy_id": "test_flow",
"description": "A sample description of the policy",
"last_updated_time": 1653467076033,
"schema_version": 13,
"error_notification": null,
"default_state": "Hot",
"states": [
{
"name": "Hot",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"rollover": {
"min_doc_count": 50,
"min_index_age": "4m"
}
}
],
"transitions": [
{
"state_name": "Warm",
"conditions": {
"min_rollover_age": "5m"
}
}
]
},
{
"name": "Warm",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"read_only": {}
}
],
"transitions": [
{
"state_name": "Cold",
"conditions": {
"min_rollover_age": "10m"
}
}
]
},
{
"name": "Cold",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"force_merge": {
"max_num_segments": 1
}
},
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"replica_count": {
"number_of_replicas": 0
}
}
],
"transitions": [
{
"state_name": "DELETE",
"conditions": {
"min_rollover_age": "1h"
}
}
]
},
{
"name": "DELETE",
"actions": [
{
"retry": {
"count": 1,
"backoff": "exponential",
"delay": "1m"
},
"delete": {}
}
],
"transitions": []
}
],
"ism_template": [
{
"index_patterns": [
"fluentbit-*"
],
"priority": 1,
"last_updated_time": 1652268548245
}
]
}
}
[/code]
Ich habe hier unterschiedlich States, eine Transition erfolgt immer in den darauf folgenden State, könnte aber auch umgekehrt werden. Bei der Berechnung der Zeitlichen Spanne ab wann eine Aktion oder Transition ausgeführt werden soll ist folgend immer auf den Rollover-Age zu setzen.
Weiter gehts…
Nach dem anlegen des Templates und der ISM Policy, starten wir den Fluent-bit. Danach sehen wir ziemlich zeitnah den INIT. Leider habe ich nur ein Bild wo den INIT des zweiten Index zeigt. Sorry.
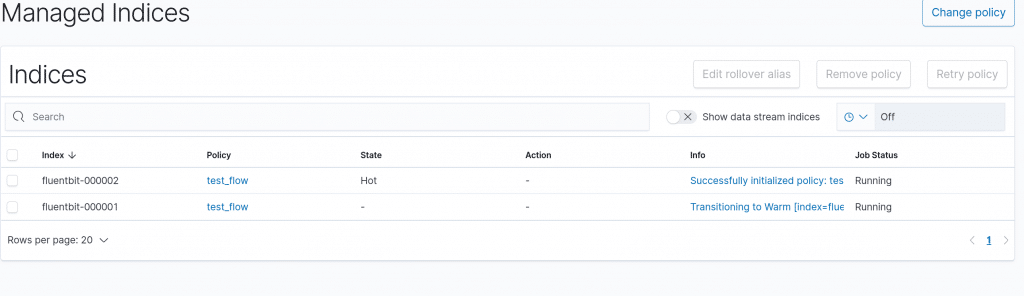
Danach müssen wir den Index-Alias manuell setzen:
[code lang=”plain”]
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "fluentbit-000001", "alias" : "fluentbit" } }
]
}
[/code]
Dann stoppen wir den Fluent-bit-Daemon und ändern den Index-Namen auf den Alias ab:
[code lang=”plain”]
[OUTPUT]
name opensearch
match *
host 192.168.2.42
port 9200
index fluentbit
type _doc
http_user admin
http_passwd admin
tls On
tls.verify Off
[/code]
Danach wird der Dienst wieder gestartet.
Diese Abfolge ist wichtig wird der Alias nicht gesetzt, schlägt uns der folgende Fehler auf:
[code lang=”plain”]
Missing alias or not the write index when rollover [index=fluent-bit-000001]
[/code]
Nun können wir die Runde entspannt laufen lassen. Die ISM Policy wird erfolgreich angewendet und wir sehen die einzelnen Transistions.
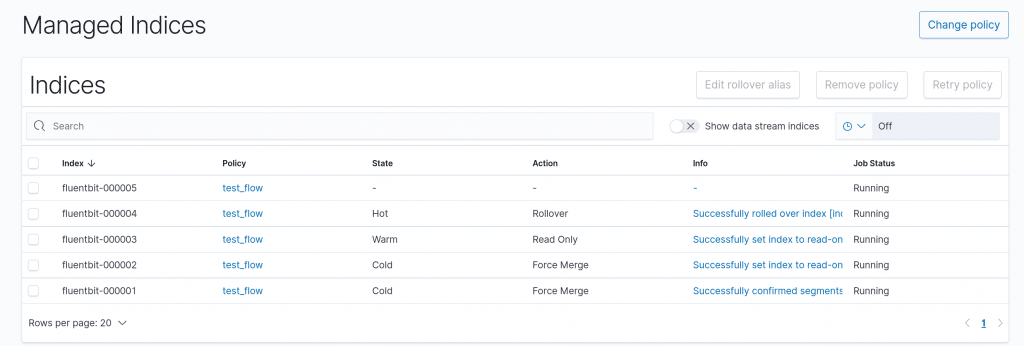
Hilfen zur Analyse bei Fehlern
Folgend möchte ich euch noch ein paar hilfreiche API-Abfragen für die DEV-Tools liefern.
Prüfen der Aliases
Damit solletst du sehen ob dein Alias gesetzt ist.
[code lang=”plain”]
GET _cat/aliases
[/code]
ISM Erklärung
Dieser API-Punkt erklärt dir genau wie der ISM State für ein Index aussieht
[code lang=”plain”]
GET _plugins/_ism/explain/fluentbit-000001
[/code]
Abfrage ISM Policy
Dieser API-Punkt gibt dir deine Policy so zurück wie diese im Cluster gespeichert ist.
[code lang=”plain”] GET _plugins/_ism/policies/test_flow [/code]
Der Gong ertönt!
Und wieder ist eine Runde rum. Diese Runde war nicht leicht, denn es galt verständlich sehr komplexes und dünn dokumentiertes Wissen zu transportieren. Auch die Tatsache, dass hier das verhalten im Vergleich zur Verwandschaft gänzlich anders ist.
Aber auch die Runde konnten wir mit ordentlich Punkten meistern. Auf die nächste Runde dürft Ihr gespannt sein, ich weis selbst noch nicht genau was uns erwartet. Weil es denke ich hilft gibt es auch noch ein Video.
Wenn Euch das, was ihr jetzt schon gelesen habt noch mehr reizt und ihr schneller zum Sieg über ein KO in der nächsten Runde erringen wollt, dann meldet Euch doch einfach bei unserem Sales Team sales[at]netways.de. Wir helfen Euch in einem PoC (Proof of Concept) gleich von Runde I an mit zu kämpfen! Nach den letzten Monaten intensiver OpenSearch Evaluierung bin ich der Trainer der euch “State of the Art” Euren “Kampf gegen die Informationsflut” gewinnen lässt. Ihr dürft gespannt sein auf Runde IV.