Seit einiger Zeit bin ich großer Fan von Wireguard als VPN Lösung um meine Server und Notebooks zu verbinden. Auch Patrick hatte schon mal über DNS Privacy mit Wireguard geschrieben. Dabei ist mir ein kleines Problem begegnet, Wireguard hat kein automatisches Handling...
NETWAYS Blog
Hier erfährst Du alles was uns bewegt. Technology, Hardware, das Leben bei NETWAYS, Events, Schulungen und vieles mehr.
Wireguard mit dynamischen DNS Namen
Seit einiger Zeit bin ich großer Fan von Wireguard als VPN Lösung um meine Server und Notebooks zu verbinden. Auch Patrick hatte schon mal über DNS Privacy mit Wireguard geschrieben. Dabei ist mir ein kleines Problem begegnet, Wireguard hat kein automatisches Handling...

Wireguard mit dynamischen DNS Namen
Seit einiger Zeit bin ich großer Fan von Wireguard als VPN Lösung um meine Server und Notebooks zu verbinden. Auch Patrick hatte schon mal über DNS Privacy mit Wireguard geschrieben. Dabei ist mir ein kleines Problem begegnet, Wireguard hat kein automatisches Handling...
Monthly Snap January > OSDC 2018, MySQL Cluster Configuration, Firmware version 1.07, Icinga Camp 2018, OSBConf 2018
Hello Two Thousand Eighteen!! It‘s been one month already and lot had happened. Michael shared some information on Modern open source community platforms with Discourse, Thomas took us security tour of Generational change for GnuPG/ PGP keys, Keya discussed 5 reasons...
Obstacles when setting up Mesos/Marathon
Sebastian has already mentioned Mesos some time ago, now it's time to have a more practical look into this framework. We're currently running our NWS Platform under Mesos/Marathon and are quite happy with it. Sebastians talk at last years OSDC can give you a deeper...
The first speakers of Open Source Data Center Conference 2018 are fixed!!
We have already received multiple super proposals from various countries. There are excellent talks with the topics Modern data center, Data Science toolkit, Distributed monitoring, Hitchhiker’s Guide and more. We are super excited to present: Ander Juaristi Alamos |...
Lösungen & Technology
Konfiguration mit Lsyncd synchronisieren
Hallo! Heute möchte ich euch ein Tool vorstellen mit dem man relativ einfach, sicher und in nahezu realzeit Konfiguration auf andere Systeme und umgekehrt synchronisieren kann. Das Tool hoert auf den Namen Live Syncing (Mirror) Daemon, oder kurz gefasst Lsyncd. Als...
Konfiguration mit Lsyncd synchronisieren
Hallo! Heute möchte ich euch ein Tool vorstellen mit dem man relativ einfach, sicher und in nahezu realzeit Konfiguration auf andere Systeme und umgekehrt synchronisieren kann. Das Tool hoert auf den Namen Live Syncing (Mirror) Daemon, oder kurz gefasst Lsyncd. Als...
Konfiguration mit Lsyncd synchronisieren
Hallo! Heute möchte ich euch ein Tool vorstellen mit dem man relativ einfach, sicher und in nahezu realzeit Konfiguration auf andere Systeme und umgekehrt synchronisieren kann. Das Tool hoert auf den Namen Live Syncing (Mirror) Daemon, oder kurz gefasst Lsyncd. Als...
Team CeBIT auf Reisen.
Fast ganz pünktlich um 10:30 ging es für den ersten Teil des CeBIT-Teams heute gen Hannover los. Während Markus mir noch im Gang in den Aufzug in Richtung CeBIT-Mobil entgegenrief: „Und schreib noch nen Blogpost zur Messe!“, lauerte einige Bürotüren weiter schon das...
Memory footprint von Scripts
Hin und wieder stellt sich die Frage in welcher Sprache man ein Programm eigentlich schreiben sollte. Neben persönliche Vorlieben, Features und Modellen welche die Sprache unterstützen soll, gilt es aber auch ein Auge auf der Performance zu haben. Bevor es nun...
Puppet, Puppet, Puppet und noch mehr Puppet
Puppet, Puppet, Puppet…. in den letzten Wochen drehte sich hier alles um Puppet. Es drehte sich sogar alles soooo sehr um Puppet, dass ich zwischenzeitlich sogar beinahe vergessen hätte, dass wir in Kürze zur CeBIT fahren und ich langsam anfangen müsste panisch zu...
Events & Trainings
Fundamentals for Puppet Goes Public
Heute geben wir bekannt, dass nach Veröffentlichung der Schulungsunterlagen unserer Foreman Schulung, auch die Unterlagen zum Kurs Fundamentals for Puppet als Github Pages und im Source-Code zum nicht kommerziellen Gebrauch bereit stehen. In den kommenden Wochen und...
Fundamentals for Puppet Goes Public
Heute geben wir bekannt, dass nach Veröffentlichung der Schulungsunterlagen unserer Foreman Schulung, auch die Unterlagen zum Kurs Fundamentals for Puppet als Github Pages und im Source-Code zum nicht kommerziellen Gebrauch bereit stehen. In den kommenden Wochen und...
Fundamentals for Puppet Goes Public
Heute geben wir bekannt, dass nach Veröffentlichung der Schulungsunterlagen unserer Foreman Schulung, auch die Unterlagen zum Kurs Fundamentals for Puppet als Github Pages und im Source-Code zum nicht kommerziellen Gebrauch bereit stehen. In den kommenden Wochen und...
Keine Ergebnisse gefunden
Die angefragte Seite konnte nicht gefunden werden. Verfeinern Sie Ihre Suche oder verwenden Sie die Navigation oben, um den Beitrag zu finden.
Web Services
Keine Ergebnisse gefunden
Die angefragte Seite konnte nicht gefunden werden. Verfeinern Sie Ihre Suche oder verwenden Sie die Navigation oben, um den Beitrag zu finden.
Keine Ergebnisse gefunden
Die angefragte Seite konnte nicht gefunden werden. Verfeinern Sie Ihre Suche oder verwenden Sie die Navigation oben, um den Beitrag zu finden.
Keine Ergebnisse gefunden
Die angefragte Seite konnte nicht gefunden werden. Verfeinern Sie Ihre Suche oder verwenden Sie die Navigation oben, um den Beitrag zu finden.
Keine Ergebnisse gefunden
Die angefragte Seite konnte nicht gefunden werden. Verfeinern Sie Ihre Suche oder verwenden Sie die Navigation oben, um den Beitrag zu finden.
Unternehmen
NETWAYS Web Services Raffle
We wanted to do a big raffle. A very special one. You can win 3 amazing prices and how this works will be described below. But first of all, what are the prices? First place: Our incredible @gethash for one day at your office* Second place: One NWS app for free. A...
NETWAYS Web Services Raffle
We wanted to do a big raffle. A very special one. You can win 3 amazing prices and how this works will be described below. But first of all, what are the prices? First place: Our incredible @gethash for one day at your office* Second place: One NWS app for free. A...

NETWAYS Web Services Raffle
We wanted to do a big raffle. A very special one. You can win 3 amazing prices and how this works will be described below. But first of all, what are the prices? First place: Our incredible @gethash for one day at your office* Second place: One NWS app for free. A...
Project of the month: Automated Nagios configuration the LDAP way
August 2009: In a mammoth migration from Tivoli, our client (anonymous) needed to integrate hundreds of servers with up to a million checks in over 6 locations across Europe into a new Nagios system. In such a massive and complex environment, the manual configuration...
Weekly snap: SecurityProbe to FrOSCon, Twitter to OSMC
August 24–28 took us from one conference to another, over Twitter and to hardware. Backtracking to the weekend before, Christian D and Eric reported from FrOSCon in St Augustin, presenting NETWAYSGrapherV2 in amongst open source heavyweights the likes of MySQL,...
Twitter Development – Zusammenfassung
In den letzten Wochen, haben wir den Großteil der vorhandene API-Funktion, welche durch Twitter bereitgestellt werden, angeschnitten. Was mich persönlich begeistert ist die Möglichkeit, sämtliche Objekte des Twitterverse im Gesamtkontext mit Suchen, Replies und...
Blogroll
Da hast Du einiges zu lesen …
PHP SPL: Verkettete Listen
Eine nützliche Klasse die durch SPL ihren Einzug in PHP gefunden hat, ist die SplDoublyLinkedList, die Implementierung einer doppelt verketteten Liste.
Eine verkettete Liste ist eine dynamisch erweiterbare Datenstruktur, die beliebig viele Elemente speichern und enumerieren kann. In vielen Sprachen, in denen die Größe von Arrays bereits statisch beim Erstellen festgelegt wird, sind Listen deshalb ein wichtiger Grundbaustein um wachsende Datenstrukturen zu Implementieren. Da Arrays in PHP diese Einschränkungen nicht haben und damit generell bereits alle Möglichkeiten einer Liste bieten, gab es lange Zeit keine Implementierung in der PHP-Standardbibliothek.
Das verwenden einer SplDoubleLinkedList macht aber in vielen Bereich dennoch Sinn, da diese das Einfügen von Elementen an bestimmten Positionen einfacher und performanter macht. Wenn wir in einem normalen Array ein Element an einem bestimmten Index einfügen wollen ohne ein Element zu überschreiben, können wir array_splice verwenden.
$N = 10000;
$arr = array('foo', 'bar', 'baz');
for ($i = 0; $i < $N; $i++) {
array_splice($arr, 1, 0, $item);
}
Wie wir feststellen ist diese Implementierung nicht sonderlich performant und das Einfügen von 10000 Elementen dauert bereits fast 10 Sekunden.
time php -f ./insert_at_array.php real 0m10.116s user 0m10.077s sys 0m0.024s
Die SplDoublyLinkedList beherrscht seit Version 5.5 die Funktion SplDoublyLinkedList::add, die ein Element an eine bestimmte Position in die Liste einfügen kann.
$N = 10000;
$list = new SplDoublyLinkedList();
$list->push('foo');
$list->push('bar');
$list->push('baz');
for ($i = 0; $i < $N; $i++) {
$list->add(1, $i);
}
Time verrät uns, dass diese Implementierung mit 47ms mehr als 200 mal schneller durchläuft als die mit regulären Arrays.
time php -f ./insert_at_list.php real 0m0.047s user 0m0.036s sys 0m0.008s
Erklären lässt sich dieser Unterschied mit der internen Implementierung von Arrays in PHP. Diese sind in PHP eigentlich Hash-Tabellen, weshalb beim Aufruf von array_splice, alle nachfolgenden Elemente mit einem neuen Index versehen werden müssen. In einer verketteten Liste wird der Index eines Elements nicht gespeichert, sondern nur anhand der Position in der Kette aus Elementen definiert. Hier genügt es die Referenzen des Vorgängers und des Nachfolgers zu ändern um alle Nachfolger einen Index nach hinten zu verschieben.
Elasticsearch Gadgets
Neue Tools auszuprobieren bedeutet auch, erst mal viel Dokumentation zu lesen. Im Falle von Elasticsearch ist das nicht viel anders. So liest man über Indizes und Shards, über Replika und Cluster. Die Installation ist relativ straight-forward, denn es stehen für alle großen Distributionen fertige Pakete zur Verfügung, die nur darauf warten genutzt zu werden. Doch eines fällt nach der Installation sofort auf: Man ist blind. Von den ganzen tollen Features die in der Dokumentation versprochen wurden, ist erst mal nichts zu sehen. Ich möchte heute ein paar Methoden und Plugins vorstellen, die das gesamte Konstrukt Elasticsearch durch Visualisierung etwas durchsichtiger und greifbarer machen.
API
Die API ist eine der mit am wichtigsten Bestandteile von Elasticsearch. Ohne sie würden viele Plugins wohl nicht existieren. Ich erwähne die API hier aber mit unter deswegen, um zu vermitteln was diese Plugins im Hintergrund eigentlich machen. So viel Magie steckt nämlich gar nicht dahinter. Bei dieser API handelt es sich nicht, wie oft fälschlicherweise behauptet, um eine REST API, sondern um eine CRUD API. Der kleine aber feine Unterschied besteht darin, dass die CRUD API direkt auf die Datenobjekte zugreift und nicht großartig abstrahiert. Man kann sie aber genauso über verschiedene URLs ansprechen. Ein Aufruf, um einen allgemeinen Status über einen Elasticsearch Server zu erhalten, würde zum Beispiel lauten curl localhost:9200/_status. Als Ergebnis erhält man einen guten Überblick über den aktuellen Stand, die Anzahl der Indizes und nähere Infos zu diesen. Die Ausgabe ist sogar im JSON Format, lässt sich also sehr gut verarbeiten. Solche Statusberichte gibt es auch für Cluster einen einzelnen Index.
[...]
"_shards" : {
"total" : 622,
"successful" : 462,
"failed" : 0
},
"indices" : {
"logstash-2014.06.27" : {
"index" : {
"primary_size_in_bytes" : 435,
"size_in_bytes" : 435
}
[...]
ElasticHQ
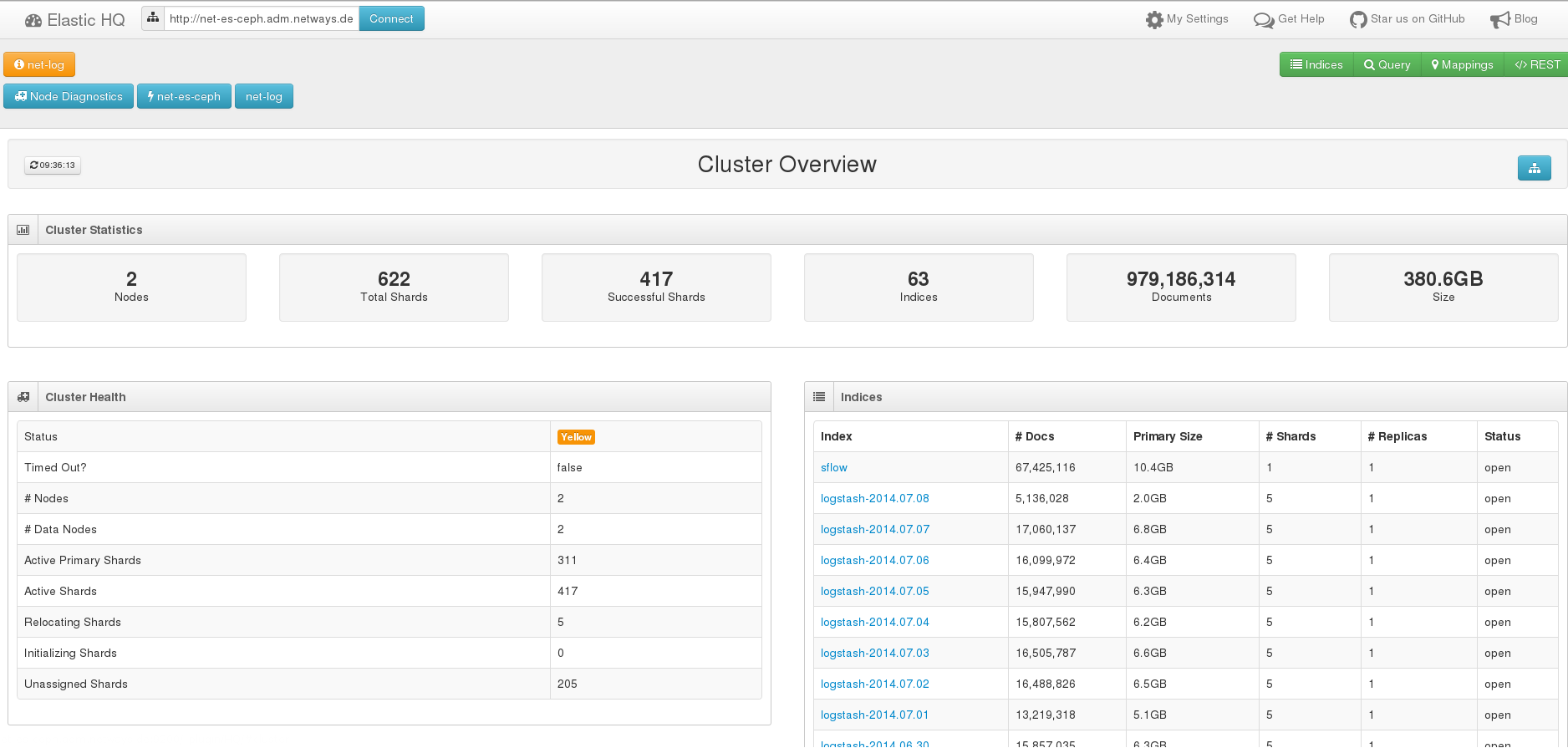
ElasticHQ Plugin – Index Übersicht
Das ElasticHQ Plugin hilft dabei, den Einstieg zu finden. In einem aufgeräumten Webinterface erhält man Informationen über die Last und den Ressourcenverbrauch der einzelnen Server. Indexe werden aufgelistet und Operationen wie „Optimize“, „Refresh“ und „Delete“ können auf sie angewendet werden.
Mit einem Interface für Queries kann man seine Daten durchsuchen und dabei gezielt einzelne Indexe ausschließen. Die Übersicht über Mappings hilft vor allem, wenn man für einzelne Felder das Mapping ändern muss, wie zum Beispiel im Zusammenhang mit Kibana, wo manche Operationen nur durchgeführt werden können, wenn sie numerische Felder erhalten.
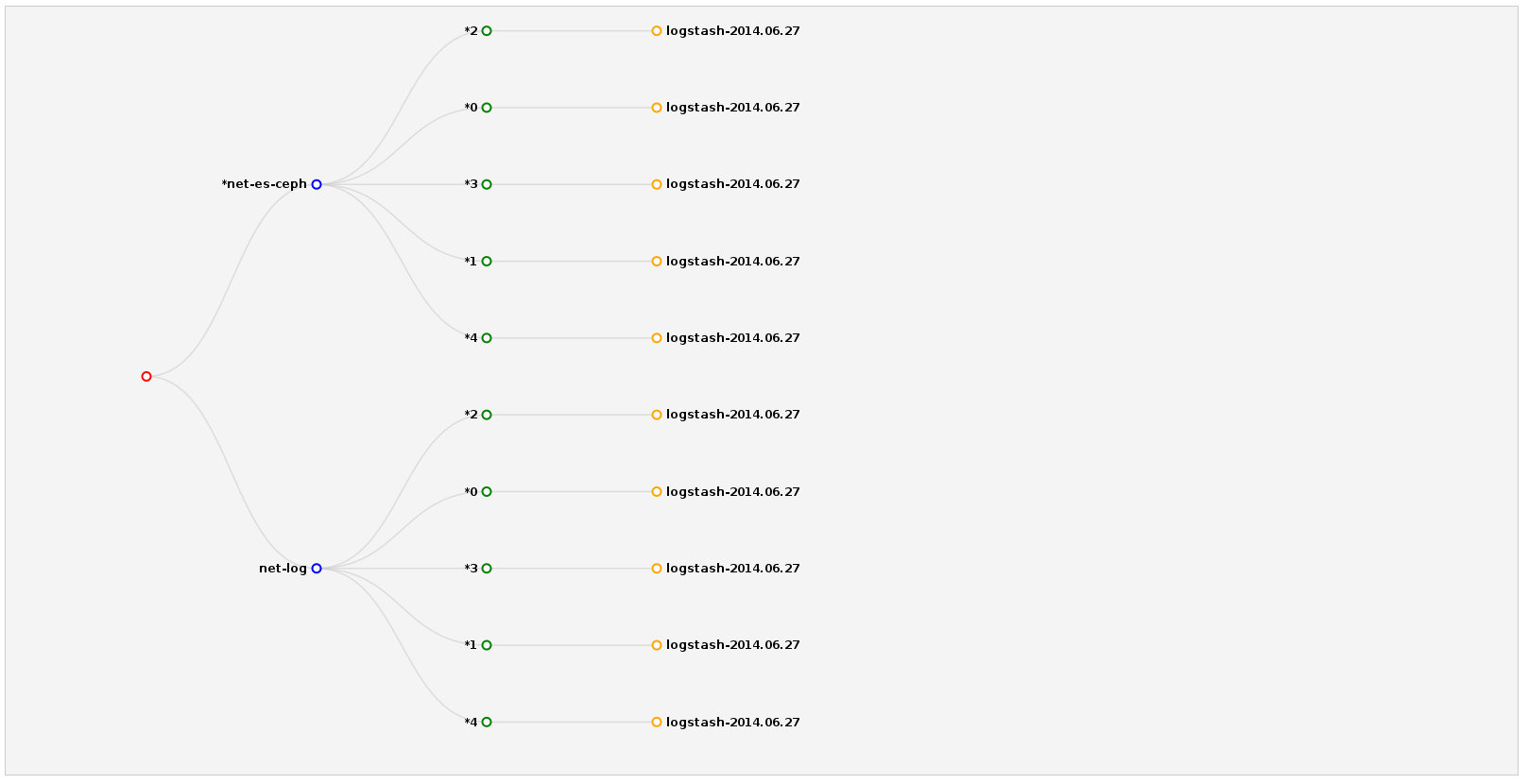
ElasticHQ Plugin – Cluster
Ein besonderes Augenmerk gilt der Cluster Ansicht. Mit vielen Indizes wird es zwar schnell unübersichtlich, einen guten Überblick bekommt man aber dennoch, wenn man sich einen Einzelnen ansieht. Die Verteilung der Shards wird schnell klar und ob wirklich Replika existieren, lässt sich auch nachvollziehen.
Head

Head Plugin
Wobei ElasticHQ seine Schwierigkeiten hat, das macht das Head Plugin umso besser. Eine Übersicht aufgeteilt auf Nodes die darstellt, wieviele Shards es pro Index gibt und wie diese aktuell verteilt sind. Die Master Node wird klar markiert und Operationen kann man auch durchführen. So lassen sich ganze Server ausschalten oder Indexe löschen, flushen, refreshen etc. Wie in ElasticHQ auch, gibt es Bereiche in denen man Queries durchführen kann und noch mal alle Indizes aufgelistet bekommt.
Bei den beiden Plugins handelt es sich um so genannte ’site-plugins‘. Das bedeutet, dass sie lediglich einen statischen Inhalt ausliefern und Elasticsearch nach der Installation nicht neu gestartet werden muss. Möglich macht das die Kommunikation über die API, die für die Plugins alle nötigen Informationen abliefert.

Blerim Sheqa
COO
Blerim ist seit 2013 bei NETWAYS und seitdem schon viel in der Firma rum gekommen. Neben dem Support und diversen internen Projekten hat er auch im Team Infrastruktur tatkräftig mitgewirkt. Hin und wieder lässt er sich auch den ein oder anderen Consulting Termin nicht entgehen. Inzwischen ist Blerim als COO für Icinga tätig und kümmert sich dort um die organisatorische Leitung.
OSMC 2014: Der Countdown läuft – nur noch 141 Tage
Starreferent Michael Medin ist wie immer mit in unserem Countdown vertreten. Diesmal gibt’s was zum Thema NSClient++ um die Ohren!
OSMC? Was soll das denn sein und wer sind die netten Menschen in diesen Videos? Die Open Source Monitoring Conference (kurz: OSMC) ist die internationale Plattform für alle an Open Source Monitoring Lösungen Interessierten, speziell Nagios und Icinga. Jedes Jahr gibt es hier die Möglichkeit sein Wissen über freie Monitoringsysteme zu erweitern und sich mit anderen Anwendern auszutauschen. Die Konferenz richtet sich besonders an IT-Verantwortliche aus den Bereichen System- und Netzwerkadministration, Entwicklung und IT-Management. Und die netten Menschen, die Ihr in unseren Videos zur OSMC seht, gehören dazu. 2014 wird die OSMC zum 9. Mal in Nürnberg stattfinden.
Weekly Snap: PHP SPL Heaps, OpenNebula Fog Provider & RPM Packaging
 30 June – 4 July offered tips for the PHP developer, cloud operator and sys admin.
30 June – 4 July offered tips for the PHP developer, cloud operator and sys admin.
Eva started the week by counting 148 days down to OSMC, with Oliver Tatzmann’s talk on “Target Group Oriented IT Service Monitoring”.
Meanwhile, Marius showed how to sort heaps of data with PHP SPL and Dirk started a new blog series on RPM packaging, beginning with the source code.
Lastly, Georg added new Argon 100 bundles to our hardware store range as Achim added our Fog provider for OpenNebula to the upstream master.
RPM-Packaging: Der Quelltext

Nachdem es mich in letzter Zeit immer öfter trifft, dass ein Kunde die Installation aus Paketen bevorzugt und es eigentlich auch mein bevorzugter Weg der Installation ist, wollte ich eine lockere Serien anfangen rund um das Thema.
Starten möchte ich mit dem Thema mit dem auch ein Paket startet und dass oftmals schon die ersten Hindernisse bereithält, dem Quelltext.
Ein RPM-Paket besteht prinzipiell aus zwei Dingen: dem Quelltext (wenn nötig mit Patches) und einer Bauanleitung, dem Spec-File. Im Spec-File wird angegeben von wo der Quelltext bezogen wird, wie dieser vorzubereiten, zu übersetzen und zu installieren ist, aber auch solche Themen wie die Lizenz unter der er veröffentlicht ist spielen eine Rolle.
Der Quelltext bleibt hierbei unverändert außer es müssen Dateien entfernt werden,die es lizenzrechtlich nicht erlauben sie zu verteilen. Daher muss alles was an Änderungen notfalls wichtig ist in Form eines Patches eingebracht werden. Warum dies leider oft notwendig ist, möchte ich im folgenden erläutern.
Mein Hauptgrund einen Patch hinzuzufügen ist die vorgesehene Installationsroutine. Diese besteht meist aus dem üblichen ./configure, make, make install, welche sich auch zum Paketieren eignet. Andere Optionen sind natürlich auch möglich, aber nur solang sie keine Interaktion erfordern. Wenn dies der Fall ist, schreibe ich diese üblicherweise gleich auf den Standard um.
Aber auch die übliche Make-Routine muss nicht immer eine gute Ausgangsbasis sein. Viele Entwickler sehen leider nur eine Installation in die von ihnen gewählten Standard-Pfade vor, meist /usr/local/bin oder ähnliches. Hierbei werden zur Sicherheit diese Verzeichnisse auch üblicherweise noch mittels install erstellt. Leider führt beides zu Problemen, denn bei der Erstellung eines RPM wird der Installationsvorgang von einem unpriviligierten Benutzer unterhalb eines speziellen Verzeichnisses durchgeführt, dem sogenannten Buildroot. Pfade außerhalb können also nicht angelegt werden und Dateien auch nicht anderen Benutzern übereignet werden.
Die Lösung hierfür sind mit configure konfigurierbare Pfade, da diese aber auch so in Konfigurationsdateien oder ähnlichem referenziert werden, muss noch ein weiterer Mechanismus genutzt werden um in die Buildroot zu installieren. Hierfür wird eine Variable DESTDIR genutzt, diese wird in den Makefiles dem eigentliche Zielpfad vorangestellt. Somit stehen in Konfigurationsdateien die echten Pfade wie beim Konfigurieren angegeben und die Installation erfolgt in diese Pfade relativ zur Buildroot.
Nun haben wir nach das Problem der Dateirechte. Werden diese beim install festangegeben, muss gepatcht werden. Guter Stil ist es diese als Variable INSTALL_OPTS zu hinterlegen, so dass diese auch in unserer Bauanleitung einfach überschrieben werden können.
Dies sind die üblichen Probleme. Patches um eine Hotfix einzupflegen solang noch kein Release erfolgt ist, sind dank git überhaupt kein Problem mehr. Fehlende Lizenzangaben finden sich ebenso immer seltener wie schlecht gepackter Quelltext, also ohne übergeordnetes Verzeichnis oder mit falscher Dateiendung.
Wenn sich nun Entwickler angesprochen fühlen und ihre Installationsroutine umschreiben wollen, habe ich ein paar Beispiele hierfür:
– EDBC (Make-Routine für Systempfade umgebaut
– Icinga-Cronk BP-Addon (phing durch make ersetzt)
– Interfacetable_v3t (Make-Routine um DESTDIR ergänzt)
Und wenn nun jemand nach unseren Paketen fragt, kann ich leider nur weiter um Geduld bitten, aber wir arbeiten daran. Versprochen!

Dirk Götz
Principal Consultant
Dirk ist Red Hat Spezialist und arbeitet bei NETWAYS im Bereich Consulting für Icinga, Puppet, Ansible, Foreman und andere Systems-Management-Lösungen. Früher war er bei einem Träger der gesetzlichen Rentenversicherung als Senior Administrator beschäftigt und auch für die Ausbildung der Azubis verantwortlich wie nun bei NETWAYS.
















