Elastic Stack
Verwandle deine Daten in Lösungen
Entdecke Elastic Stack: Die ultimative Open Source Lösung für die Sammlung, Verarbeitung, Analye und Speicherung von Informationen und Ereignissen.
Elasticsearch
Der Open Source Enterprise Suchserver
Elasticsearch ist ein verteilter Such- und Analytikserver, welcher als zentraler Speicherort das Herzstück des Elastic Stacks darstellt. Die Kommunikation zwischen Elasticsearch und dem Service-Konsumenten erfolgt nahezu ausschließlich über JSON via REST-Interface. Dies hat den Vorteil, dass auch kleinere Schreib- und Lesevorgänge mit Hilfe von CURL getestet und entwickelt werden können, ohne auf eine schwergewichtige API zurückgreifen zu müssen. Hierbei kann Elasticsearch für beliebige Anwendungen als Such- und Analytikserver betrieben werden oder im Elastic Stack kontext.
Elasticsearch bietet auch die Möglichkeit, Daten vor dem Speichern beim Ingest in sogenannten Pipelines mittels eigener Skripting Language in Filtern aufzubereiten und dadurch einen Mehrwert am gespeicherten Datensatz zu generieren.
Die Stärken von Elasticsearch sind Geschwindigkeit, Skalierbarkeit, Relevanz und Resilienz, vor allem wenn es darum geht, deine Datenmengen unterschiedlicher Typen zu Speichern und zu Verwenden.
Suchen. Beobachten. Beschützen.
Skalierung
Besonders sticht Elasticsearch dadurch hervor, dass es alles was für Skalierung und Verteilung der Installation benötigt wird einfach mitbringt. Ist aufgrund steigender Last eine Erweiterung notwendig, so muss Elasticsearch lediglich ein neuer Server mitgeteilt werden.
Es kümmert sich anschließend selbständig um die Umverteilung der Daten und Anfragen.
Performance
Alle eingehenden Daten werden von Elasticsearch umgehend indexiert. Ob Loginformationen, numerische oder geographische Daten.
Da alles indiziert ist, kommt niemals Langeweile auf. So können alle Daten mit enorm hoher Geschwindigkeit abgerufen und verarbeitet werden. Und das ganze kommt natürlich mit einer rasend schnellen Volltextsuche im Gepäck.
Logstash
Flexibles Log- und Eventmanagement
Logstash ist eine Open Source Logmanagement Lösung, die sich auf die Kanalisierung, Filterung und Verteilung von Log- und Eventinformationen spezialisiert hat. Dabei unterstützt es eine Vielzahl von Ein- und Ausgangsformaten und integriert sich so in nahezu jede IT-Umgebung.
Kurzum ist Logstash die Open Source Lösung zur Verwaltung und Analyse von Loginformationen und das Tool der Wahl, um der steigenden Anzahl an Informationen revisionssicher zu begegnen. Logstash verfügt über eine Vielzahl an Input-, Filter- und Output-Plugins. Somit können alle in Ihrem Netzwerk verfügbaren Events und Logmeldungen empfangen, verarbeitet und weitergeleitet werden.
Integration
Um die verschiedenen Informationen aus unterschiedlichsten Quellen zu verarbeiten und weiterzuleiten unterstützt Logstash eine Vielzahl an In- und Outputs. Neben Standards wie Syslog, Pipe und SNMPTraps werden auch diverse Message-Broker unterstützt.
Die Integration von Applikationslogs ist somit ohne weitere Umwege möglich und erfordert keine Installation von zusätzlicher Third Party Software.
input { stdin { } }
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
Kibana
Dein Blick in den Elastic Stack
Mit Kibana erfolgt die Visualisierung und Analyse der in Elasticsearch gespeicherten Daten. Ausgefeilte Filteroption ermöglichen den Bau von Dashboards gespickt mit präzisen Visualsierungen für eine feine Analyse.
Die Arbeit mit Kibana ist der eigentliche Lohn für die Mühe, welche im Vorfeld zur Sammlung der Log- und Eventinformationen investiert wurde. Der Zugriff auf alle gespeicherten Informationen geht rasend schnell und ist mit der Kibana-Query Language inklusive autovervollständigung ein Kinderspiel.
Natürlich ist das Verständnis für zugrunde liegende Schnittmengen der abgefragten Daten von Vorteil, um schnell zum Ziel zu kommen, aber auch ohne macht die visuelle Betrachtung der Daten einfach Spaß.
Kibana ist jedoch viel mehr als nur ein Werkzeug zur Analyse. Kibana stellt den Dreh und Angelpunkt im Elastic Stack dar und bietet eine Vielzahl von Integrationen zur Datenauswertung und Nutzung in den Bereichen Log-Managment bis hin zur Security-Auswertung. In Kombination mit den Alarmierungs- und Anomalie-Erkennungs- Funktionen, hat man alles Notwendige für ein schnelles Vorfalls-Mangaement zur Hand. Hinzu kommen die Integrationen des Elasticsearch Index-Managements, dem Elastic Stack Monitoring, des Berechtigungs-Managements, der Beats und sogar des Logstash-Pipeline-Managements.
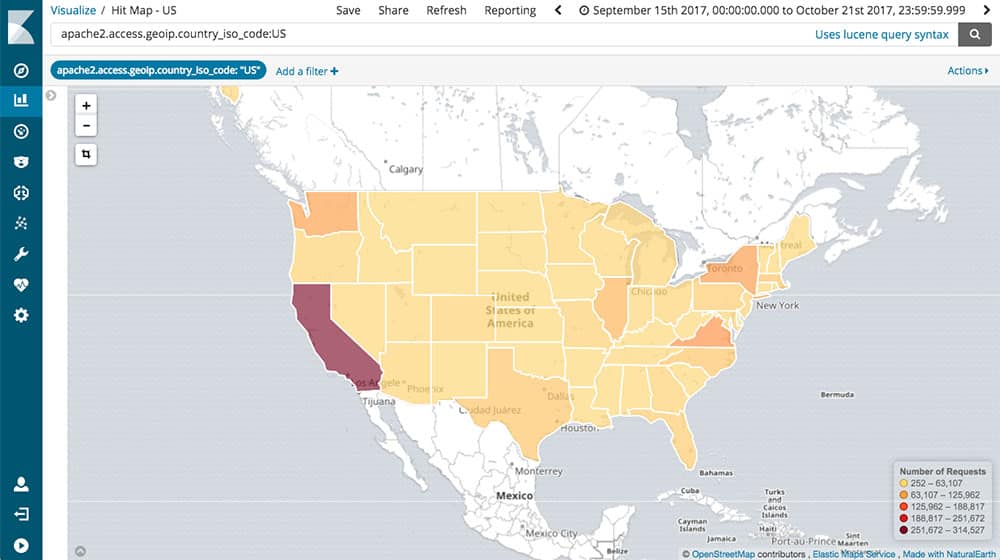
Geoinformationen können ganz einfach in Kibana verwendet werden um einen lokalen Datenbezug herzustellen. Mit Hilfe des Geoip-Filter-Plugins können Logdaten anhand der vorhandenen IP-Adresse mit entsprechenden Geoinformationen angereichert werden.
Elasticsearch ist mehr als eine reine Index-Datenbank verfügt über eine leistungsstarke Engine für Zeitserien, den so genannten Timeseries. So können Performance-Informationen aus Logdaten über längere Zeiträume gespeichert und analysiert werden.
Beats
Sammeln, Analysieren und Versenden
Beats ist die Plattform zum Bau von leichtgewichtigen Datensammlern für eine Vielzahl von Datentypen.
Es gibt unterschiedliche Beats mit einer Vielzahl von Möglichkeiten für das Einlesen von Daten, vom vorab Anreichern oder Verarbeiten von Daten durch Prozessoren, über eine Vielzahl von Modulen mit vorgefertigten Verarbeitungsketten für das direkte Einliefern in Elasticsearch, bis hin zu fertigen Dashboards für unterschiedlichste Produkte. Dazu kommt die Möglichkeit Daten nicht nur an Elasticsearch und Logstash zu senden, denn das absolute Plus ist die Möglichkeit, die Daten bereits beim Einlesen vor dem Versenden durch zusätzliche Informationen in Form von Dokumenten-Felder und Tags anzureichern.
Dabei überzeugen die Beats nicht nur durch Ihre Integrationen, sondern auch durch ihren sehr geringen Fußabdruck auf dem System.
Wie jedes Mitglied der Elastic Stack Werkzeugkiste ist auch der Beat ein Standardwerkzeug bei der Vearbeitung von Informationen und Ereignissen jeglicher Art, Codecs und Quellen. So ist es fast unmöglich um den Beat bei der Sammlung von Informationen mit dem Elastic Stack oder artverwandten Werkzeugen herum zu kommen.
Filebeat
Der Filebeat ist das Werkzeug für das Sammeln von Log-Informationen aus einer Vielzahl von Quellen in unterschiedlichsten Formaten. Hier geht die Palette der Inputs vom Plain-File bis hin zu Syslog. Dies prädestiniert den Filebeat auch als Site-Collector, um dann in ein zentrales Elasticsearch-Cluster zu liefern.
Ja richtig gelesen – Elasticsearch! Denn mit seiner Vielzahl an Modulen für eine Vielzahl von Produkten in einer modernen Infrastruktur, liefert Filebeat bereits aufbereitete Daten oder Aufbereitungspipelines für Elasticsearch, sowie Index-Pattern und Kibana-Dashboards mit – und natürlich alles ECS-Konform. Diese Mechanismen garantieren eine einwandfreie Funktion mit z.B der neuen Elastic-Security Integration für eine allumfängliche IT-Sicherheits-Auswertung.
Winlogbeat
Für Windows Eventlogs stellen die Winlogbeats eine besondere Variante der Filebeats dar, welche speziell für die Sammlung von Eventlogs entwickelt wurde. In Verbindung mit zusätzlich gelieferten Processoren und im Zusammenspiel mit Sysmon von Sysinternals bietet sich hier die Möglichkeit eines präzisen Thread-Monitorings.
Somit können auch hier die Daten bereits aufbereitet werden, ohne das System zu belasten und mit Informationen in Form von zusätzlichen Feldern oder Tags angereichert werden.
Das Ergebnis ist eine leichtgewichtige Lösung zur zentralen Speicherung von Windows Logdaten mit direktem Ingest in Elasticsearch oder wahlweise über den Logstash.
Beratung
Elastic Stack Consulting
Wir helfen Dir bei Konzeption, Installation und Integration Deiner Umgebung – für mehr Power, Know-How, Peace of Mind!
Power
Jahrelange Erfahrung
Seit vielen Jahren unterstützen wir unsere Kunden beim Betrieb ihrer IT-Infrastrukturen. Branchen, Tools, Betriebssysteme – wir haben alles Mögliche gesehen, betrieben und gebaut. Wir kennen die Best Practices mit Elastic, Graylog & Co. und viele Themen rund um Open Source und Linux.
Know-How
Volles Verständnis
Wir verstehen nicht nur Deine IT-Systeme und Services, sondern das große Ganze und die unzähligen Aspekte des Betriebs komplexer IT-Infrastrukturen. Häufig mangelt es an Zeit und Personal bei steigender Komplexität und einer sich schnell verändernden IT-Welt.
Peace of Mind
Gezielte Verstärkung
Als Linux-Generalisten und Open Source Expertinnen sind wir breit aufgestellt und bestens eingebunden in die Open Source Communities. Mit uns bist Du nie allein! Ob als IT-Berater, Engineer, Support oder Architekt – wir verstärken Dein Team und nehmen Dir Arbeit ab.
Alles aus einer Hand
Das Ganzheitliche Portfolio von NETWAYS
Du benötigst Unterstützung bei Planung, Einführung und Betrieb deiner Elastic Stack Umgebung. NETWAYS unterstützt Dich bei allen Fragen rund um Consulting, Outsourcing und natürlich Training.
IT Outsourcing
Support
Schulungen
Starterpaket
Der einfache Beginn von etwas Großem
Mit unseren Starterpaketen wollen wir den Einstieg in das Logmanagement mit dem Elastic Stack (Elasticsearch, Logstash und Kibana) vereinfachen und eine kostengünstige Möglichkeit bieten, das Open Source System kennen zulernen ohne erst in große finanzielle Vorleistungen gehen zu müssen, wie es etwa bei kommerziellen Produkten oftmals der Fall ist.
Einer unserer erfahrenen Consultants kommt 4 bzw. 7 Tage vor Ort, richtet das System direkt vor Ort ein und vermittelt die Grundlagen für den weiteren Betrieb. Das Paket wird zum Festpreis abgerechnet und es fallen keine zusätzlichen Kosten an.
Wir empfehlen vor der Buchung des Elastic Stack Starterpakets Standard den Besuch unserer Elastic Stack Schulung. Diese Schulung ist im Elastic Stack Starterpaket Premium bereits enthalten.
Elastic Stack Starterpaket Standard
- Gemeinsamer Workshop zum Thema Log- und Eventmanagement
- Einführung in die Komponenten Logstash, Elasticsearch, Kibana und Beats
- Installation und Grundkonfiguration auf Kundenhardware
- Exemplarische Integration von Kundenlogs und Auswertung mit Hilfe von Kibana
Elastic Stack Starterpaket Premium
- Elastic Stack Schulung (3 Tage für 3 Teilnehmer – weitere Teilnehmer gegen Aufpreis möglich – 6 max.) *
- Gemeinsamer Workshop zum Thema Log- und Eventmanagement
- Einführung in die Komponenten Logstash, Elasticsearch, Kibana und Redis
- Installation und Grundkonfiguration auf Kundenhardware
- Exemplarische Integration von Kundenlogs und Auswertung mit Hilfe von Kibana
* Die Schulung hat den Umfang der Elastic Stack Schulung und wird remote durchgeführt (inkl. Leihnotebooks, Schulungsmaterial und Teilnehmerzeugnissen)
Subscriptions
Elastic Enterprise
Bei uns bekommt ihr alle self-managed Elastic Subscriptions, damit ihr eure On-Premise-Deployments optimal und mit allen ELK-Stack Features nutzen könnt.
Einfach anfragen und wir erstellen ein indivduelles Angebot für eure Umgebung.
Aktuelles
Artikel aus unserem Blog

Kritisch: Fehler in Elasticsearch mit JDK22 kann einen sofortigen Stop des Dienstes bewirken
Update Seit gestern Abend steht das Release 8.13.2 mit dem BugFix zur Verfügung. Kritischer Fehler Der Elasticsearch Dienst kann ohne Vorankündigung stoppen. Diese liegt an einem Fehler mit JDK 22. In der Regel setzt man Elasticsearch mit der "Bundled" Version ein....
Kibana Sicherheits-Updates: CVSS:Critical
Und täglich grüßt das Murmeltier. Nein nicht ganz. Heute ist es aus der Elastic Stack Werkzeugkiste Kibana, für das es ein wichtiges Sicherheits-Update gibt. Es besteht auf jeden Fall Handlungsbedarf! IMHO auch wenn ihr die "Reporting" Funktion deaktiviert habt. Der...
 Subscribe
Subscribe