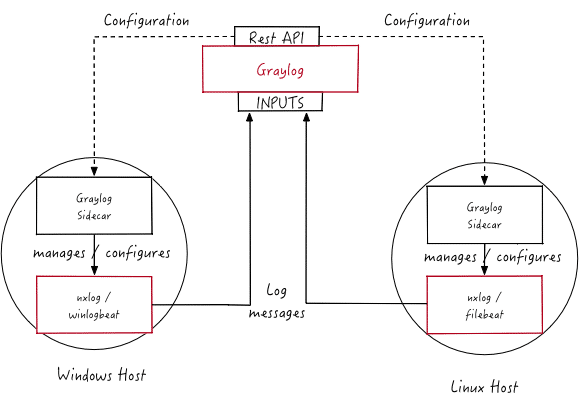
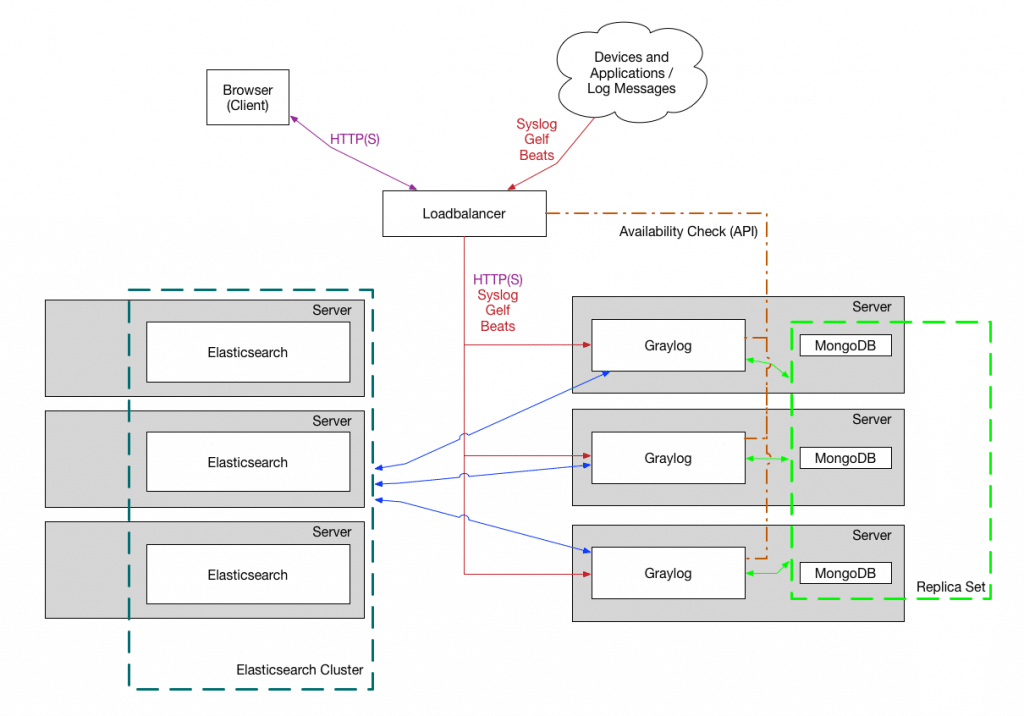
Was nutzt das beste Log Management, wenn man sich das Ganze nicht auch ansehen kann? Für den Elastic Stack kann man hier auf Kibana setzen – ein mächtiges Tool, das neben höchster Funktionalität auch noch sehr schick aussieht.
Kibana – was ist das? Die wichtigsten Fakten!
- Benutzeroberfläche: offen und kostenlos
- Visualisierung der Elasticsearch-Daten mit folgenden Anzeigeoptionen:
- Histogramme
- Liniendiagramme
- Kreisdiagramme
- Ringdiagramme und vieles mehr
- Elastic Maps bietet die Möglichkeit, Topographien und Ebenen zu erstellen – perfekt geeignet für Eure Standortanalysen!
- Darstellung mithilfe von Graphen und Netzwerken erlaubt das Aufzeigen von bisher unerkannten Zusammenhängen
- Navigieren im Elastic Stack
- Suchfunktion und Filter über alle Dokumente hinweg – Abfragen, Transformationen und Visualisierungen werden durch unkomplizierte Ausdrücke erstellt
- Analyse Eurer Daten anhand von Zeitreihen
- Erkennen von Anomalien: durch ein selbstständiges Machine Learning kann analysiert werden, wodurch Anomalien auftreten und beeinflusst werden
- Alarmierung im Falle des Falles! Stellt selbst Eure Schwellenwerte ein, egal ob index- oder metrikbasiert und lasst Euch benachrichtigen über:
- Slack
- PagerDuty
- weitere Drittanbieter-Integrationen
- Alle Alarmierungen können auch als Verlauf angezeigt werden!
Oder wie Elastic es so schön nennt: “Das Fenster in den Elastic Stack.”
Hier noch ein Screenshot, damit man sich auch ein Bild von den Möglichkeiten machen kann:
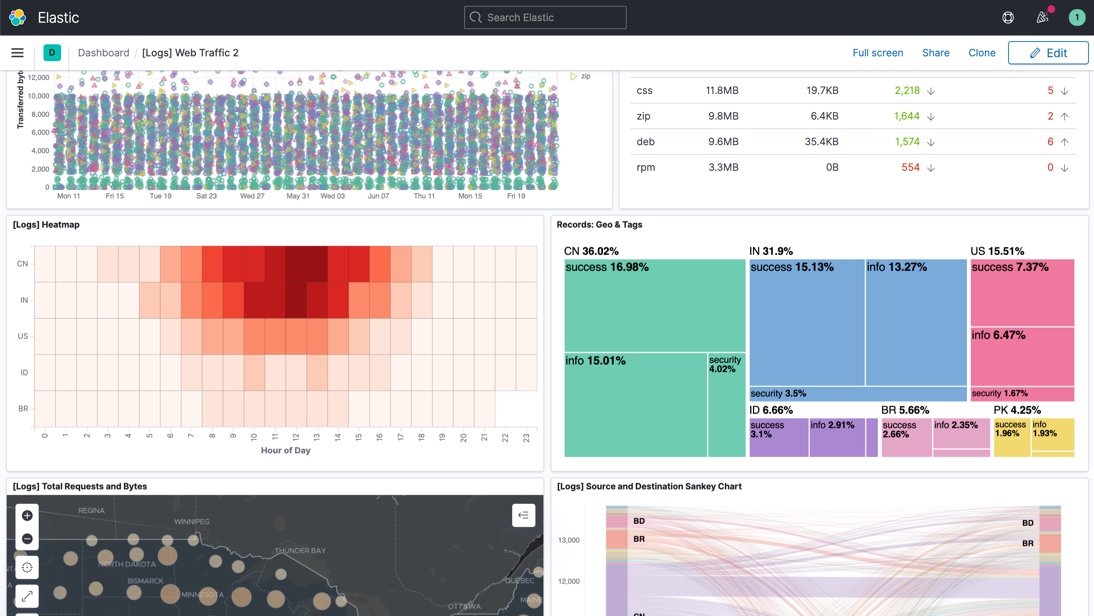
Quelle: https://www.elastic.co/de/kibana/
Wir haben Euer Interesse an Kibana und dem Elastic Stack geweckt? Ihr wollt vielleicht wissen, ob die Tools als Lösung für Eure Use Cases in Frage kommen? Dann kommt einfach auf uns zu! Wir sind erreichbar unter sales@netways.de oder über unser Kontaktformular.
Auch könnt Ihr über unsere Website direkt Schulungen buchen für Elastic, aber auch für viele andere Produkte wie Graylog oder Icinga 2. Solltet Ihr Euch unsicher sein oder weitere Infos benötigen, dann kontaktiert einfach unsere Kollegen über events@netways.de.
Wer kurzfristig etwas lernen möchte, dem empfehle ich unsere Webinare. Hier findet hier auf unserer Website die bereits gehaltenen Webinare sowie Ankündigungen für neue. Insbesondere haben wir kürzlich Webinare zum Thema Elastic hinzugefügt.