![]()
Viele von euch haben bestimmt schon einmal von OpenNebula oder OpenStack gehört, beiden Plattformen verwenden standardmäßig libvirtd als Hypervisor, da jedoch die darunter liegende Hardware mit unter stark beansprucht werden wird, vor allem im Cloud Bereich, wo mehrerer KVM Instanzen auf einem Virt Host um CPU/Speicher/IO Resourcen konkurrieren, ist es gelegentlich notwendig die einen oder andere Instanz zu bändigen bzw. in die Schranken zu weisen.
Unsere Cloud läuft derzeit noch mit OpenNebula, wir selbst sind sehr zufrieden mit dem Stack, da sich dieser leicht Verwalten lässt und sich auch gut mit unserem Ceph als Backend verträgt, natürlich verwenden wir in unserem Cloud Stack noch andere Tools, diese sind aber nicht Gegenstand dieses Artikels, mehr dazu in späteren Teilen der Serie.
Libvirtd kann mit CLI Tools wie virsh gesteuert werden, auch besteht die Möglichkeit libvirtd über die entsprechende libvirt C API oder durch seine ScriptLanguage Bindings für ruby/python/perl/javascript/etc… anzusprechen bzw. anzusteuern zu können.
So beispielsweise unterstützt man OpenNebula wenn die Migration einer KVM Instanz von Virt Host A zu Virt Host B aufgrund von Last auf der Instanz selbst partout nicht klappen will…
root@virt1: ~ $ virsh migrate-setmaxdowntime --downtime 1800 one-8366
error: Requested operation is not valid: domain is not being migrated (dieser Fehler kommt nur wenn sich die Instanz nich im Status Migrate befindet, ist hier also nur exemplarisch mit abgebildet)
…oder wenn die Instanz AMOK läuft und somit andere Instanzen zu stark beeinträchtigt…
root@virt1: ~ $ virsh blkdeviotune one-8366 vda --live
total_bytes_sec: 62914560
read_bytes_sec : 0
write_bytes_sec: 0
total_iops_sec : 400
read_iops_sec : 0
write_iops_sec : 0
…dann limitieren wir diese einfach ein bisschen…
root@virt1: ~ $ virsh blkdeviotune one-8366 vda --live 62914560 0 0 200 0 0
…und vergewissern uns nochmal ob unsere neuen IOPs Limits übernommen wurden…
root@virt1: ~ $ virsh blkdeviotune one-8366 vda --live
total_bytes_sec: 62914560
read_bytes_sec : 0
write_bytes_sec: 0
total_iops_sec : 200
read_iops_sec : 0
write_iops_sec : 0
…ich denke, damit sollte klar sein worauf wir hier abzielen möchten.
In folgenden Teilen dieser Serie werden wir euch noch mehr Tips & Tricks mit auf den Weg geben, die helfen sollen eure Cloud zu bändigen bzw. aufkommende Probleme anzugehen, also bleibt gespannt. 😉
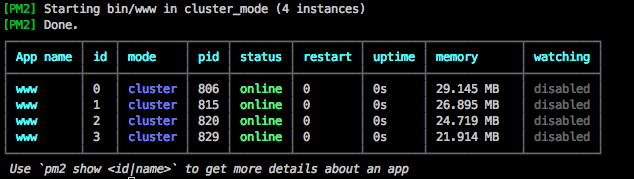
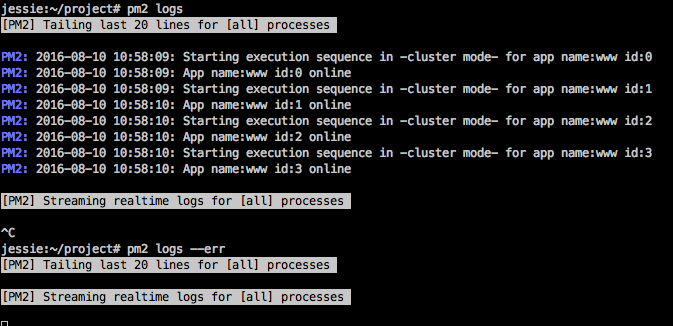

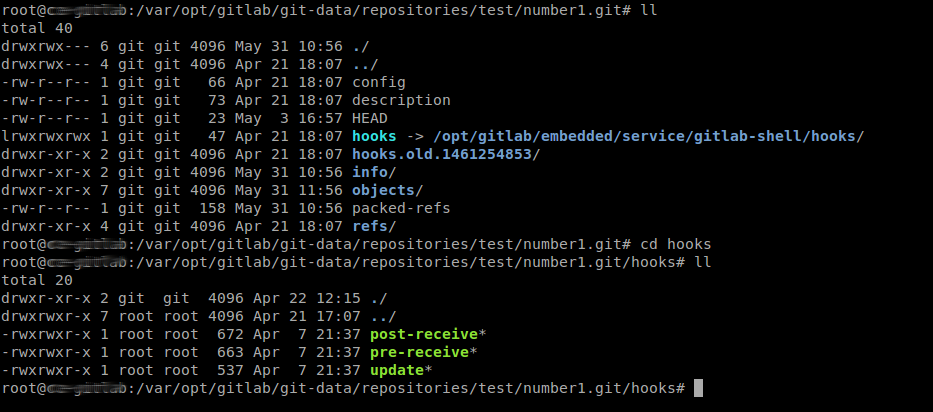
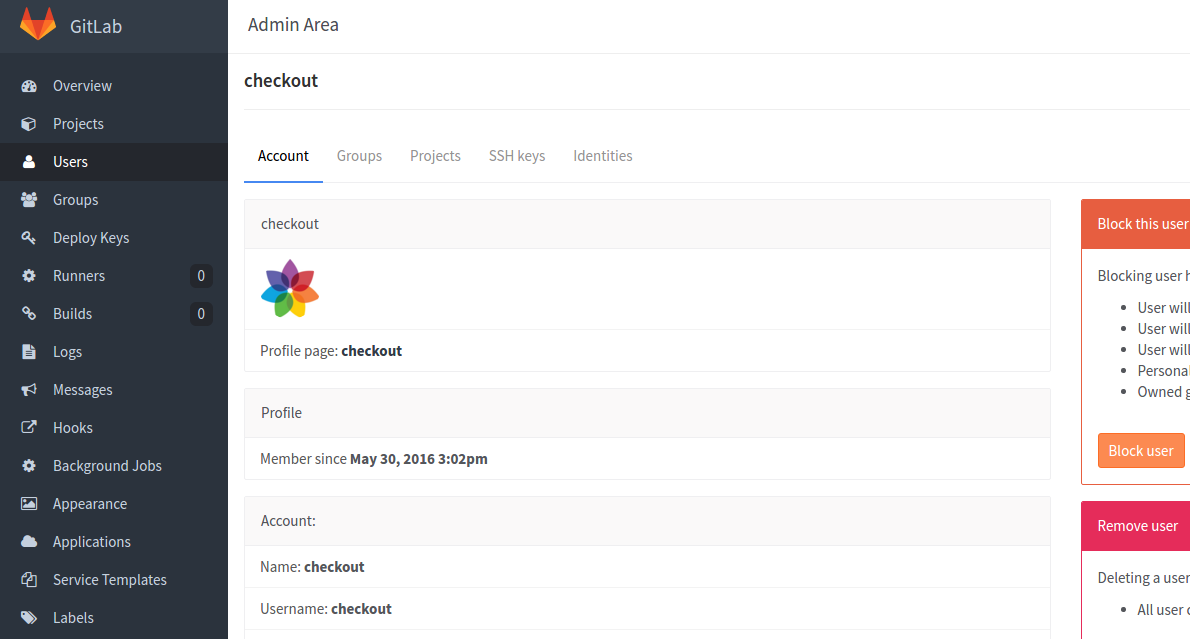
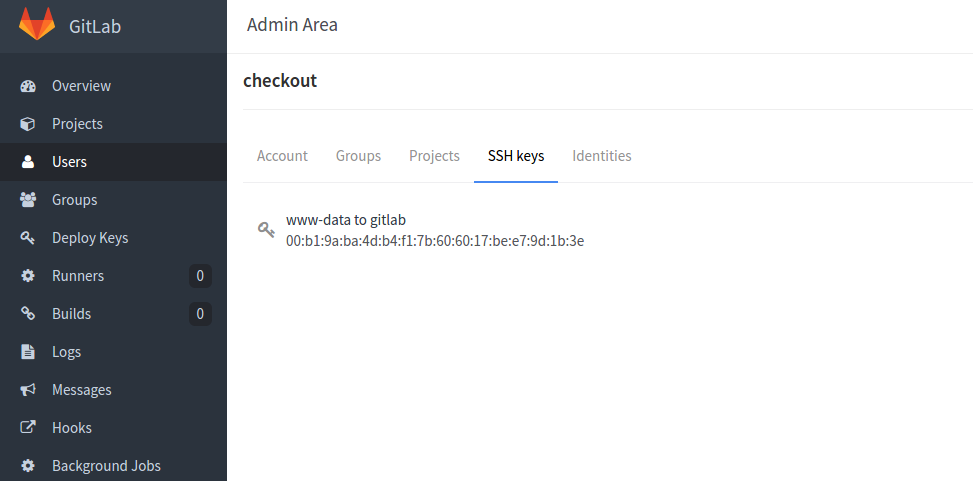
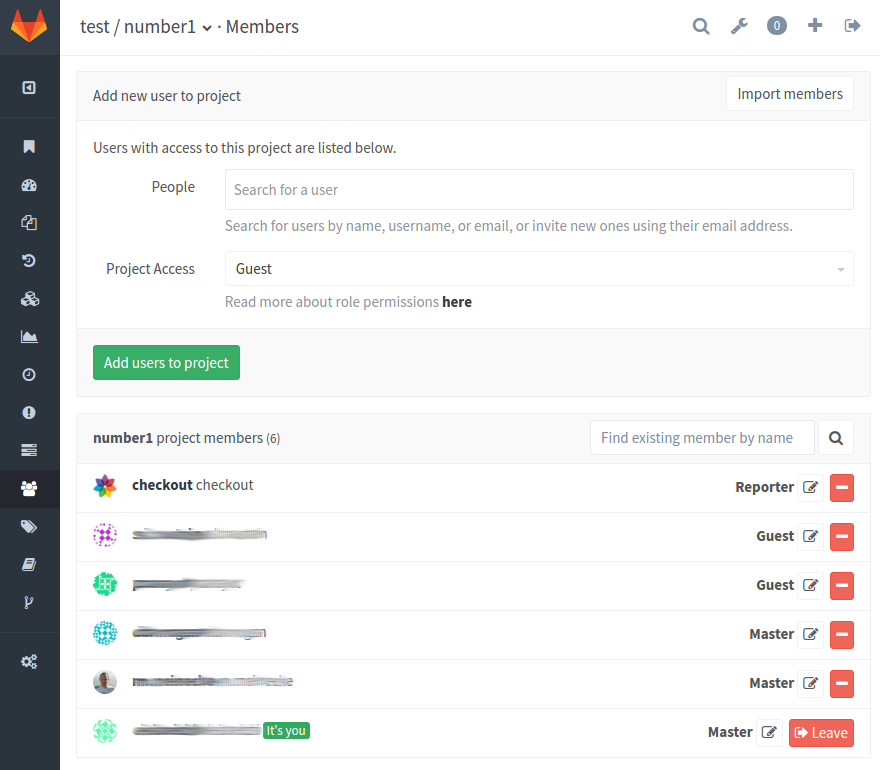
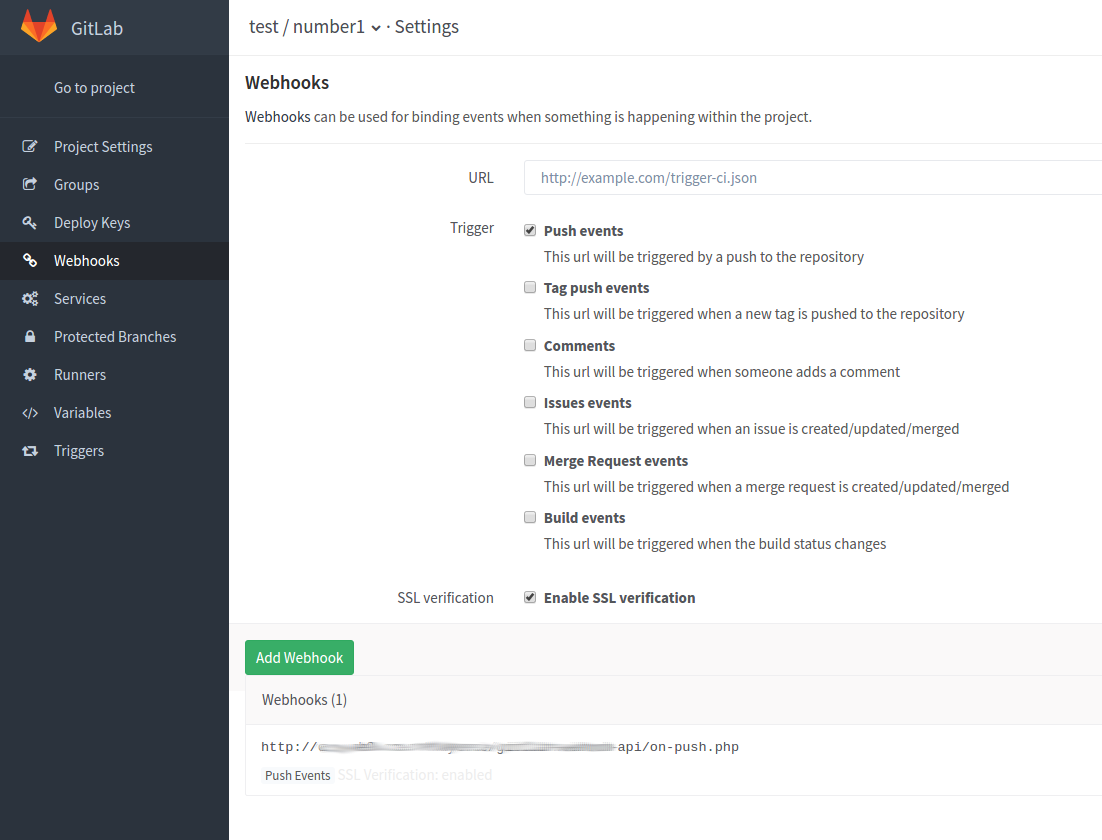
 …bitte beachtet auch, das es beim Entwickeln eines Webhooks sehr hilfreich sein kann wenn ihr über den Button [Test Hook] den Push Event einfach mal Manuell triggert, ansonsten würde euer Webhook erst aufgerufen werden wenn ihr wirklich in das Repository Pusht (das geht natürlich auch, legt euch hierzu einfach ein neues Repository zum spielen an).
…bitte beachtet auch, das es beim Entwickeln eines Webhooks sehr hilfreich sein kann wenn ihr über den Button [Test Hook] den Push Event einfach mal Manuell triggert, ansonsten würde euer Webhook erst aufgerufen werden wenn ihr wirklich in das Repository Pusht (das geht natürlich auch, legt euch hierzu einfach ein neues Repository zum spielen an).