Throughout this blogpost I want to share some awareness on search engines and current trends of fingerprinting. Some parts have tags for defense and offense. In the following Black Hats are considered evil and destructive, whereas Red Teams simulate Black Hats, allowing organizations to test their effective defenses by Blue Teams.
Warning: Make sure to follow your countries jurisdiction on using Shodan and Censys. In most countries querying keywords is not an issue for public available data, as it is public and has been harvested and tagged by the search engine itself already. This is just like google dorking something like Grafana intitle:Grafana – Home inurl:/orgid, private Keys: site:pastebin.com intext:”—–BEGIN RSA PRIVATE KEY—–” , or AWS Buckets: site:http://s3.amazonaws.com intitle:index.of.bucket .
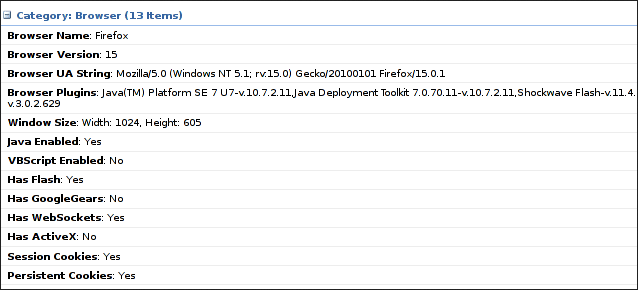
Browser fingerprinting & custom malware
Sites like amiunique directly show how WebGL and other metadata tracks us. This is why TOR disables Javascript entirely and warns you about going fullscreen.
Offense:
Beef and Evilgophish would be two OSS frameworks for fishing and victim browser exploitation, which have profiling included.
Defense:
You could use:
1) User Agent Spoofer for changing your Operating System
2) Squid in Paranoid Mode, to shred as many OS & hardware details as possible
3) Proxychains with Proxybroker to collect and rotate IPs. KASM allowing containerized throw away workspaces would also throw many attackers off conveniently.
Infrastructure tracking
Shodan has a list of filters to set, depending on your payment plan. Often advanced payment planes are not necessary (but you are limited to a number of queries/day), more so the correct hashes and keywords.
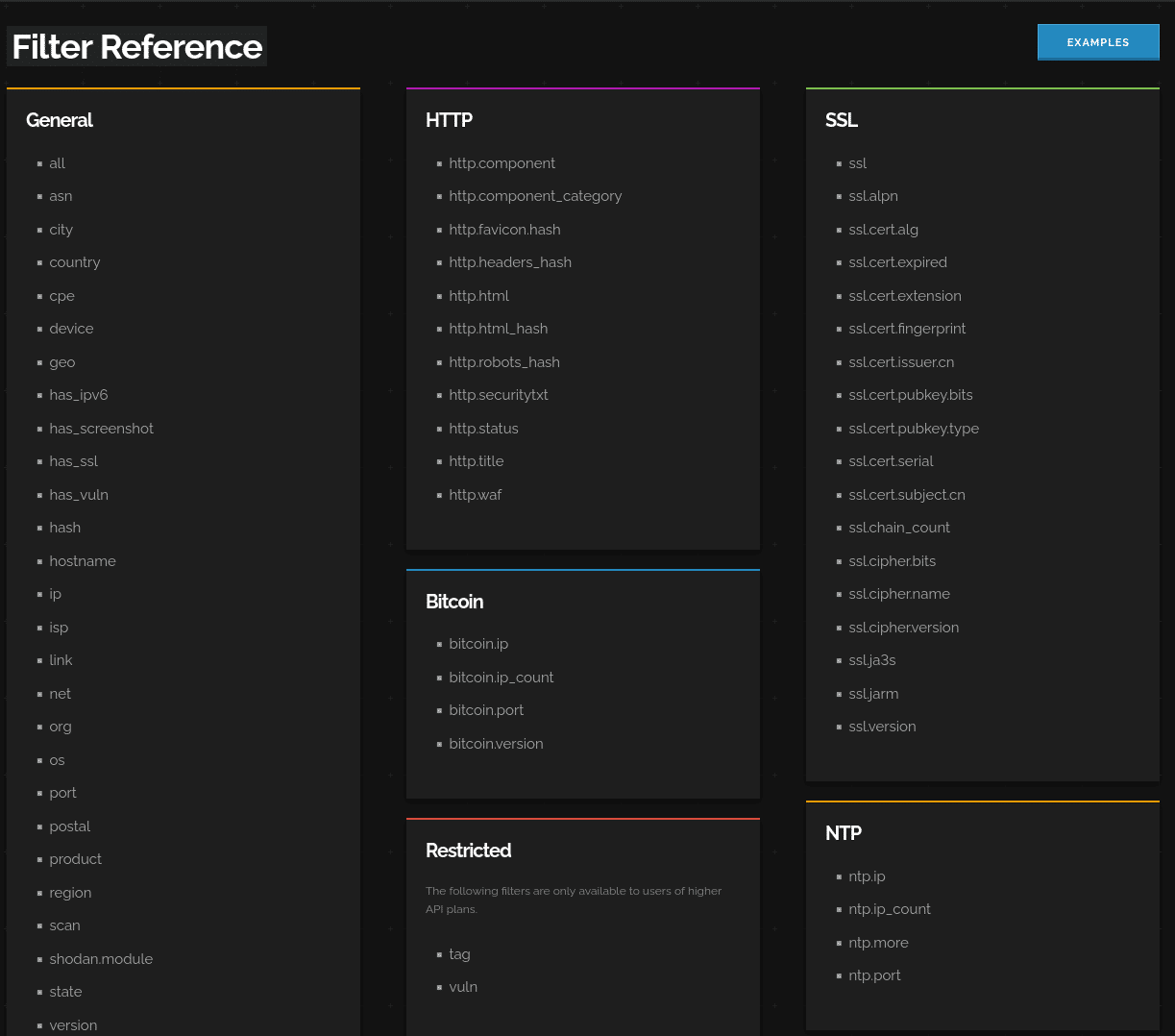
Recently Michal Koczwara a Threat Hunter, shared some great posts on targeting Black Hat infrastrastructure.
JARM TLS Fingerprinting
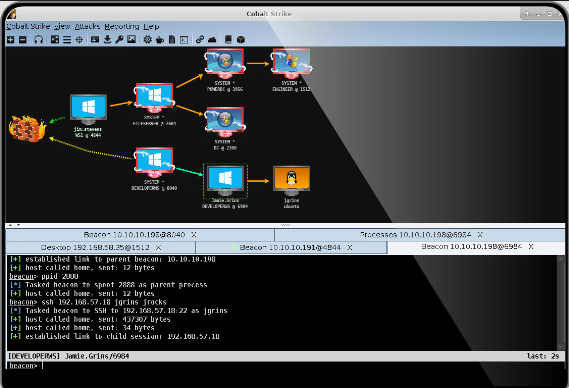
Firstly, what is a C2? It is a Command & Controll server that has Remote Code Execution over all the malware agents. Cobalt Strike is one of the top two C2 for Red Teamers and Black Hats. An analogy to monitoring would be an Icinga Master, which has visibility, alerting & code execution over multiple monitoring agents.
Defense:
Salesforce JARM is an amazing way to fingerprint the TLS handshaking method. This is because a TLS handshake is very unique, in addition to bundled TLS ciphers used. A basic Shodan query for this would be: ssl.jarm:”$ID-JARM”. Of course C2 developers could update their frameworks (but most don’t).
Below you see a query of Cobalt Strike JARM C2s and the top countries it is deployed in. Of course servers are individually visible too, but at this point I try to not leak the IPs.
.
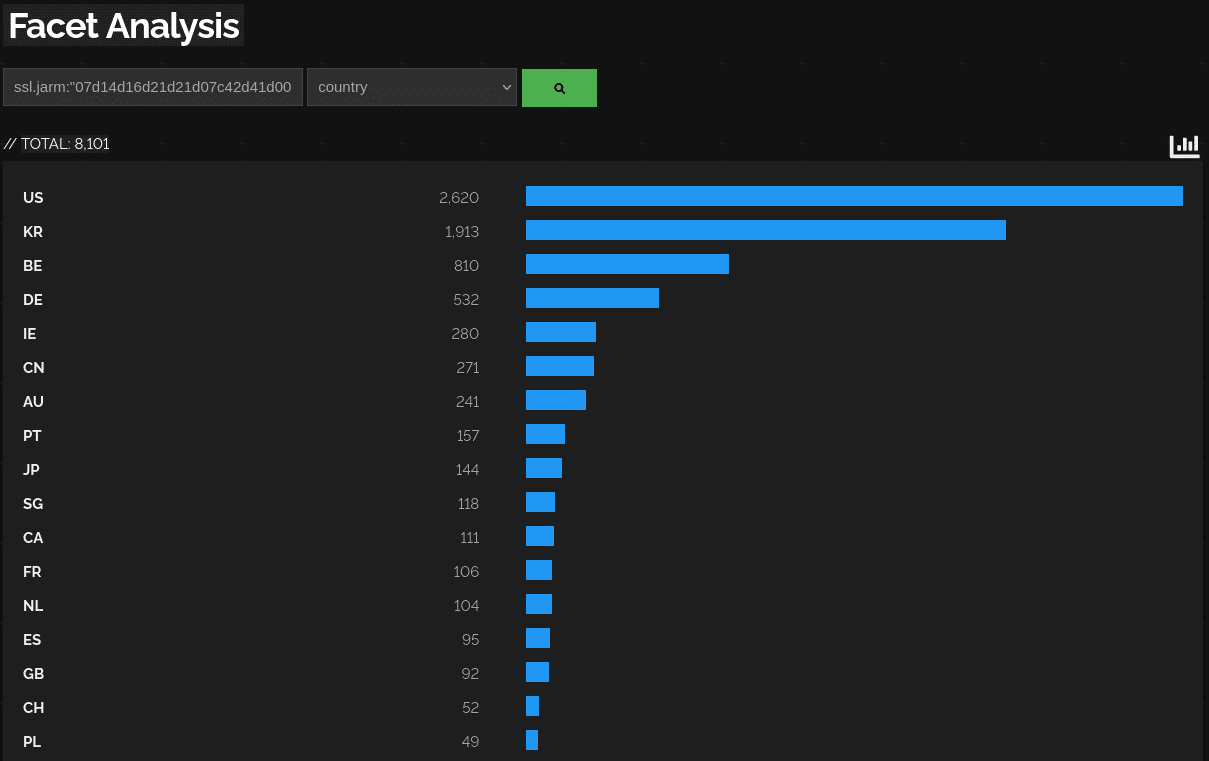
This also works for Deimos C2, or any other C2.

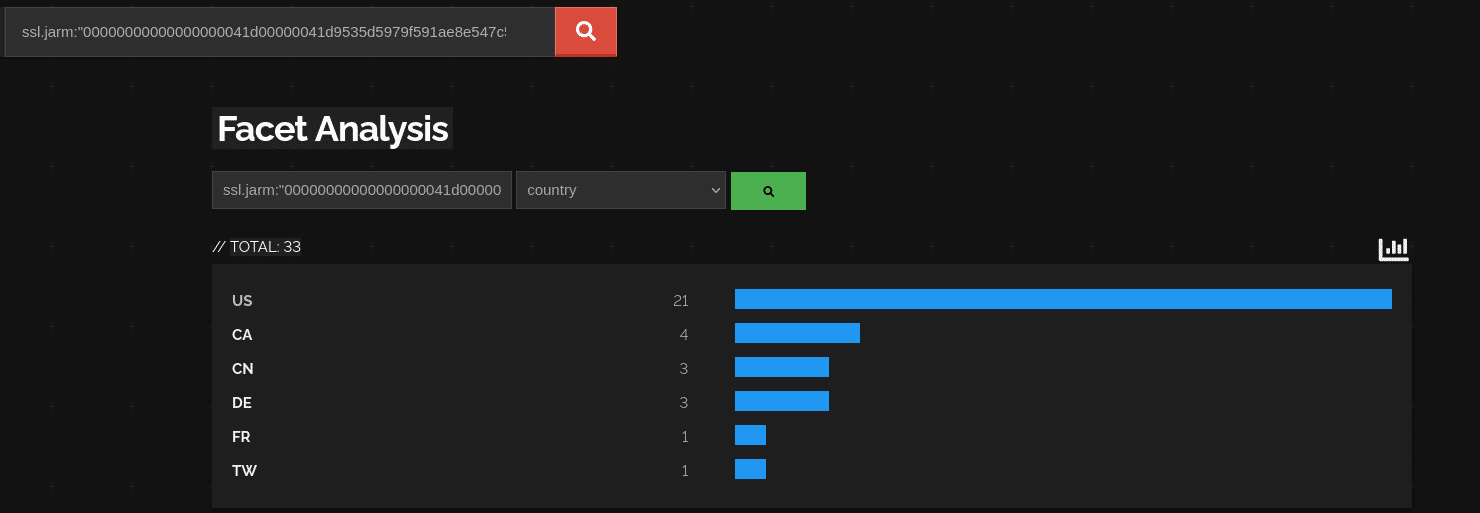
You can find various lists of JARM hashes, and all you need to do is run JARM against an IP and port, to create your own lists. This could scale greatly tcpdump, Elastic or my little detector collecting IPs, and alert on the very first TCP connection (basically on the first stager phase of the malware, before any modules are pulled off the C2).
Offense:
Put your C2 behind a proxy, make sure to select a good C2 for operational security, and add randomization for the JARM.
Http.Favicon Hashes
For Favicons: Use Hash Calculators like this one here. This is quite common in bounty hunting to avoid Web Application Firewalls if the server has internet access without a full WAF tunnel. A basic Shodan query would be look this: http.favicon.hash:-$ID.
Http.html Hashes
There are even more OSINT indicators like those ones by BusidoUK which show http.html hashes impact on Metasploit http.html:”msf4″ or Miners http.html:”XMRig”. Some Black Hats or Red Teamers don’t even bother to put any authentication on their C2s at all?
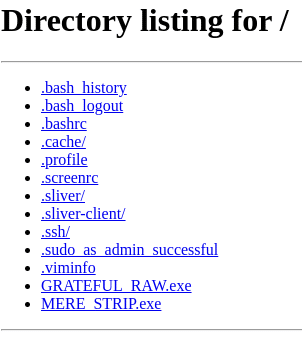
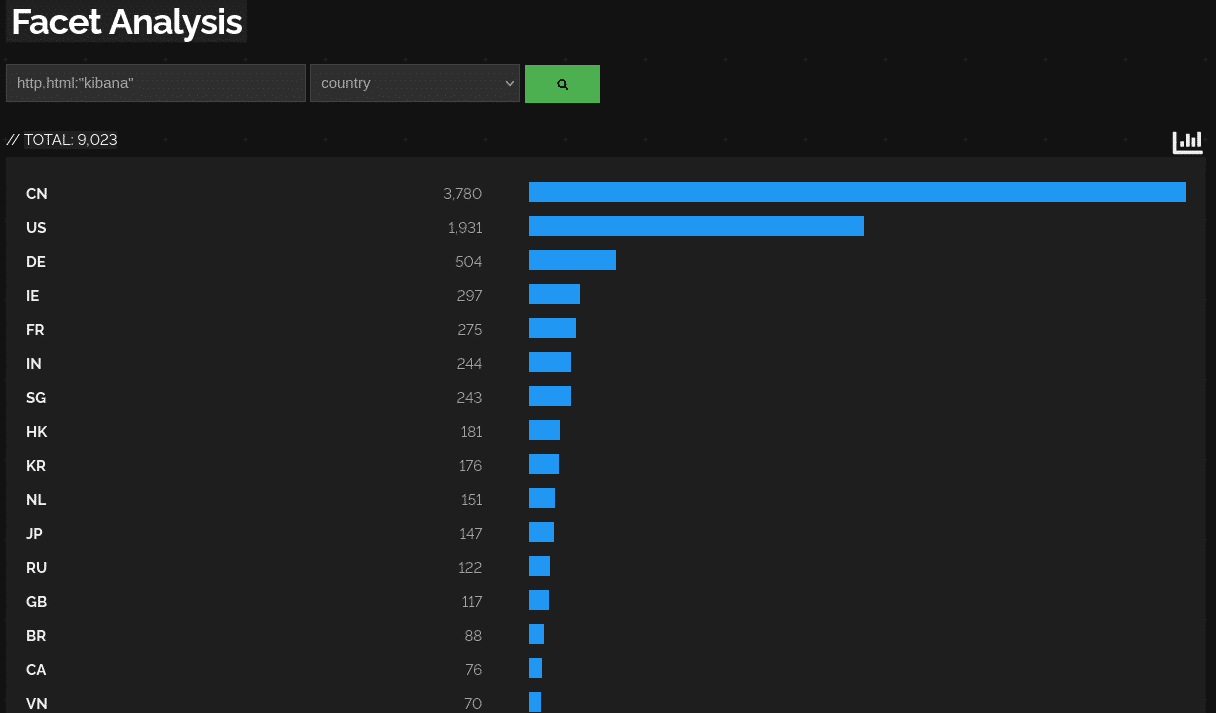
Http.hml Hashes are brutal! You even find literally anything online, even defensive products like Nessus http.html:”nessus”
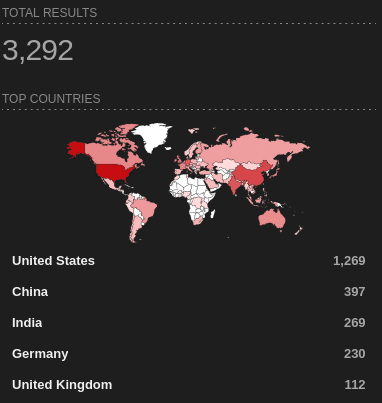
or Kibana http.html:”kibana”.
Fingerprinting Honeypots
Interestingly the chinese Version of Shodan, Zoomeye, is also offering fingerprinting honeypot detection in the VIP and Enterprise models. Some honeypots should really work on their Opsec, but of course this is an expensive cat and mouse game, and pull requests are always welcome right.

As of now I am diving more into honeypots with Elastic backends, and even complete Active Directory Honeypots, to help you as our customers more in the future.
In case you’re interested in consultancy services about Icinga 2, Elastic or another of our supported applications feel free to contact us at any time!