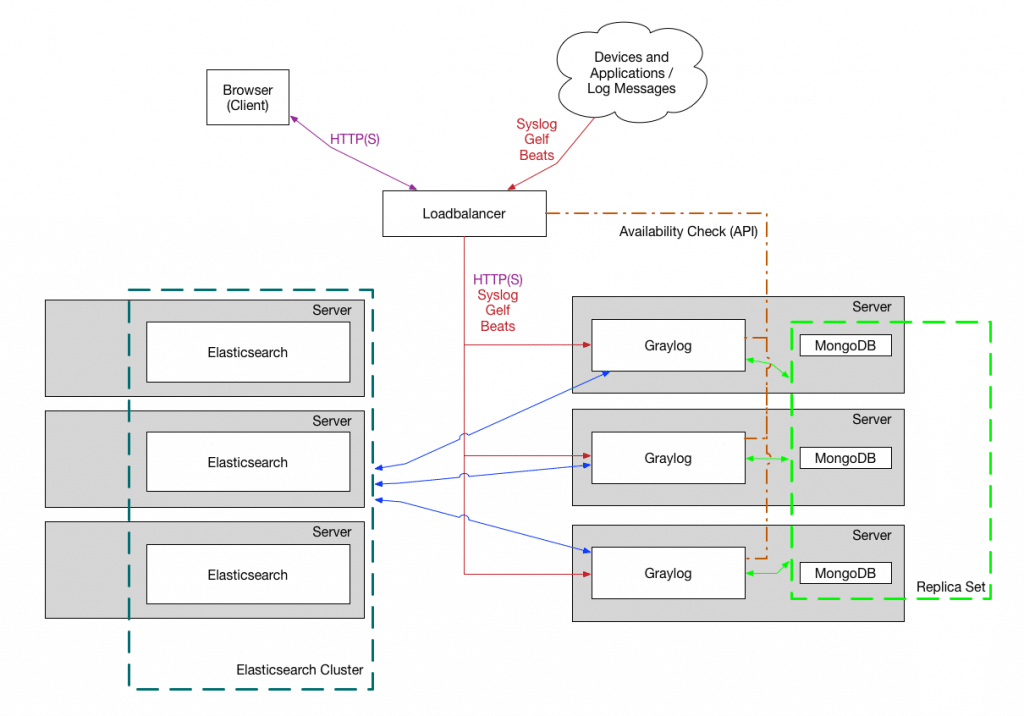
Graylog Sidecar ist ein Konfigurationsmanagementsystem, ein sogenanntes Framework, für unterschiedliche Log Collectoren, auch Backends genannt. Die Graylog Nodes agieren hier als zentraler Hub und halten die Konfiguration der Log Collectoren. Auf unterstützten Systemen, die Log Messages generieren, kann Sidecar als Service (unter Windows) oder daemon (unter Linux) laufen. Die Kommunikation zwischen Sidecar und Graylog wird durch eine SSL-Verschlüsselung der API gewährleistet. Für die Verbindung zwischen den Collectoren und Graylog sollte als Best Practive TLS aktiviert werden.
Die Log Collector Konfigurationen werden zentral über die Graylog Weboberfläche verwaltet. Periodisch holt sich der Sidecar daemon über die REST API alle relevanten Konfigurationen für das Ziel. Beim ersten Durchlauf oder nach einer Konfigurationsänderung erstellt Graylog Sidecar automatisch die relevanten Backend-Konfigurationsdateien. Im Anschluss werden die neu- oder umkonfigurierten Log Collectoren (neu-)gestartet.
Schematische Darstellung
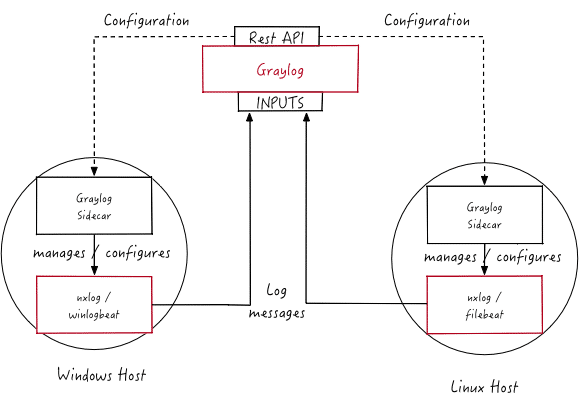
Quelle: Graylog Sidecar
Folgende Punkte sind hierbei wichtig zu verstehen und zu beachten:
- Eine Konfiguration ist die Darstellung einer Log Collector Konfigurationsdatei in der Graylog Weboberfläche. Eine Konfigurationsdatei kann den Sidecars zugewiesen werden, womit auch die entsprechenden Collectoren zugewiesen werden. Es können mehrere Konfigurationen einem einzigen Log Collector zugewiesen werden, jedoch kann ein Kollektor nicht mehreren Sidecars zugewiesen werden.
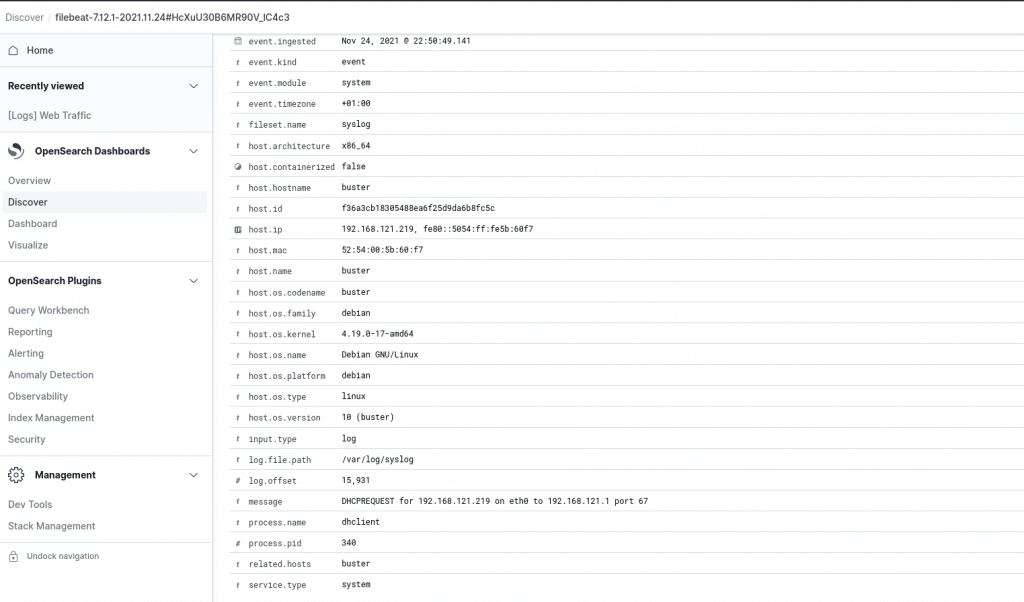
- Inputs stellen die Prozesse dar, mit denen die Collectoren Daten sammeln. Ein Input kann z. B. ein Log File sein, das vom Collector in regelmäßgen Abständen gelesen wird, oder eine Verbindung zu einem Windows Event System, das Log Events ausgibt. Ein Input ist verbunden mit einem Output, ansonsten wäre es nicht möglich, die Daten an den näschsten Punkt zu weiterzugeben. Daher muss als erstes ein Output erstellt werden, mit dem danach einer oder mehrere Inputs verknüpft werden.
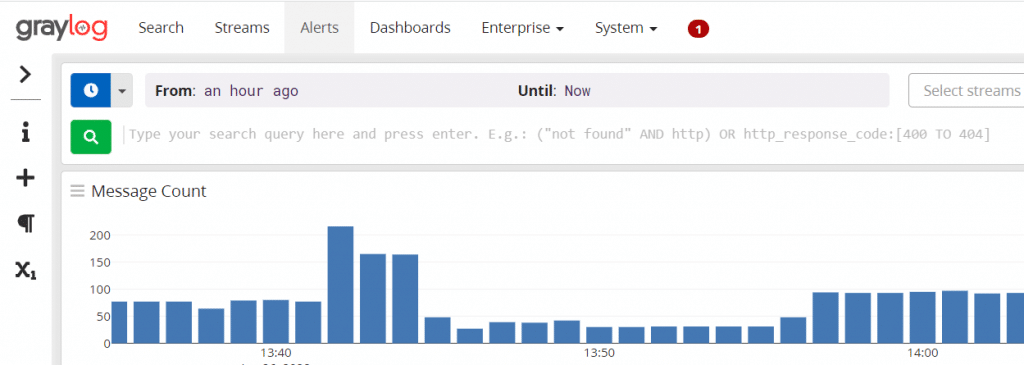
- Jede Sidecar Instanz kann Statusinformationen zurück an Graylog senden. Über die Aktivierung der entsprechenden Funktion können Metriken wie Load oder auch die IP Adresse des Hosts, auf dem Sidecar läuft, gesendet werden. Des Weiteren sind auch Metriken enthalten, die für die Stabilität des Systems wichtig sind, z. B. Disk Volumes mit mehr als 75 % Füllstand. Zusätzlich kann per Aktivierung eine Liste mit Directories in der Graylog Weboberfläche angezeigt werden, worüber eingesehen werden kann, welche Dateien zum Sammeln bereit stehen. Diese Liste wird periodisch aktualisiert.
- Für Sidecar existieren .deb und .rpm Packages sowie entsprechende Windows-Installer.
Log Collectors für Sidecar
Graylog umfasst unter anderem per Default Collector Konfigurationen für Filebeat, Winlogbeat oder NXLog (siehe untenstehende Liste). Es können aber auch weitere, eigene Collector Backends eingebracht werden wie z. B. sysmon, auditd oder packetbeat.
- Beats on Linux: Filebeat und andere Beats
- Beats on Windows: Im Windows Sidecare Package ist Filebeat und Winlogbeat bereits enthalten.
- NXLog on Ubuntu
- NXLog on CentOS
- NXLog on Windows
Wir haben Euer Interesse an Graylog geweckt? Es haben sich Fragen aufgetan zu Eurer bestehenden Graylog-Umgebung? Dann her damit! Schreibt uns einfach über unser Kontaktformular oder an sales@netways.de. Auch per Telefon sind wir für Euch unter der 0911 / 92885-66 zum Thema Graylog erreichbar.
Quelle Titelbild: pixabay.com / Creator: Murmel