Last year’s Open Source Monitoring Conference (OSMC) was a great experience. It was a pleasure to meet attendees from around the world and participate in interesting talks about the current and future state of the monitoring field.
Personally, this was my first time attending OSMC, and I was impressed by the organization, the diverse range of talks covering various aspects of monitoring, and the number of attendees that made this year’s event so special.
If you were unable to attend the congress, we are being covering some of the talks presented by the numerous specialists.
This blog post is dedicated to this year’s Gold Sponsor Eliatra and their wonderful speakers Leanne Lacey-Byrne and Jochen Kressin.
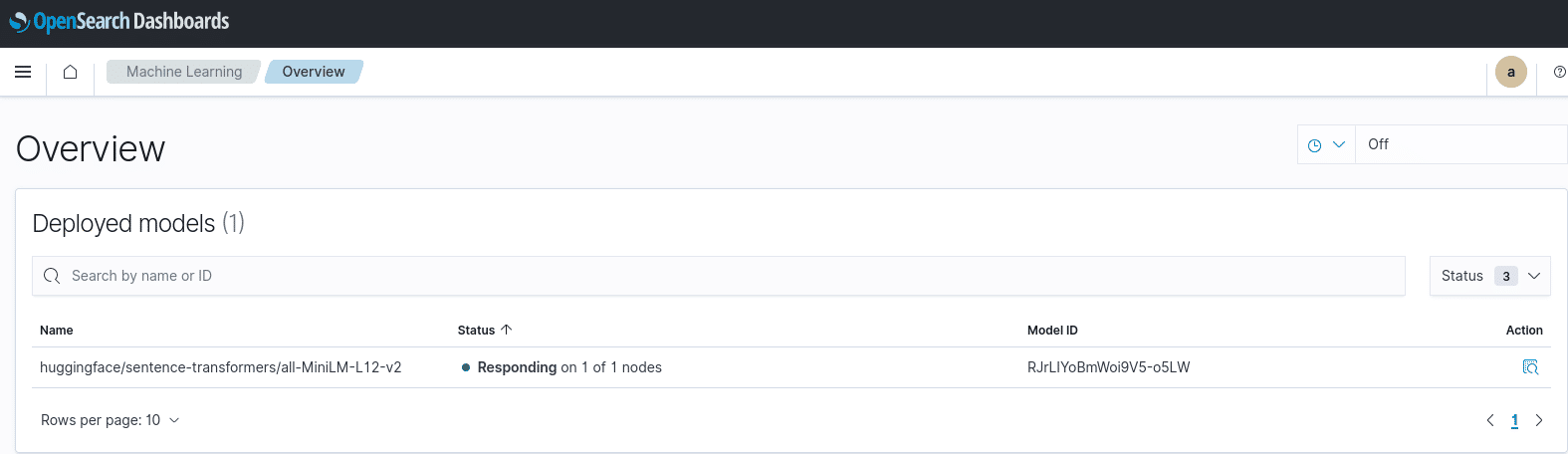
Could we enhance accessibility to technology by utilising large language models?
This question may arise when considering the implementation of artificial intelligence in a search engine such as OpenSearch, which handles large data structures and a complex operational middleware.
This idea can also be seen as the starting point for Eliatra’s experiments and their findings, which is the focus of this talk.
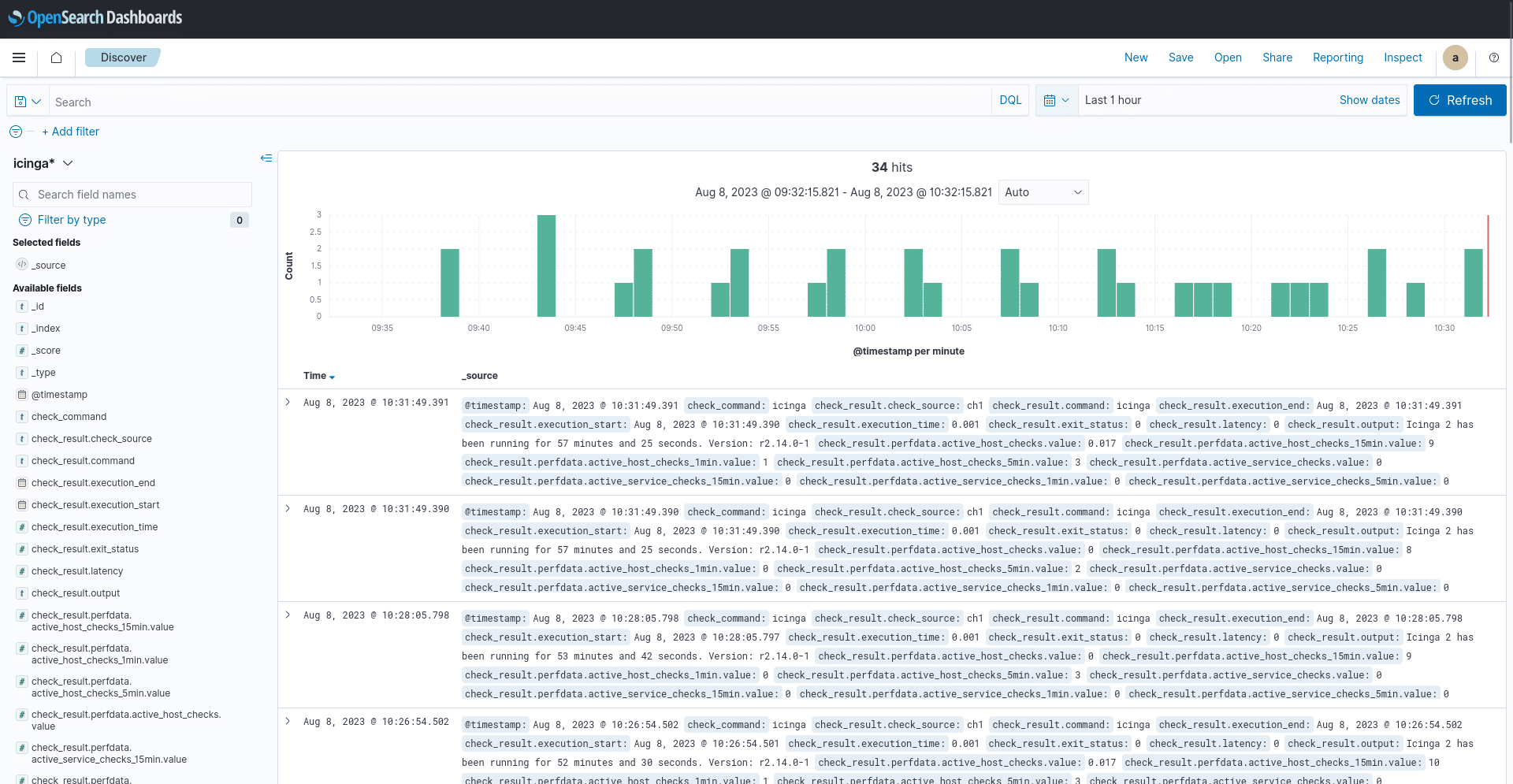
Working with OpenSearch Queries
OpenSearch deals with large amounts of data, so it is important to retrieve data efficiently and reproducibly.
To meet this need, OpenSearch provides a DSL which enables users to create advanced filters to define how data is retrieved.
In the global scheme of things, such queries can become very long and therefore increase the complexity of working with them.
What if there would be a way of generating such queries by just providing the data scheme to a LLM (large language model) and populate it with a precise description of what data to query? This would greatly reduce the amount of human workload and would definitely be less time-consuming.
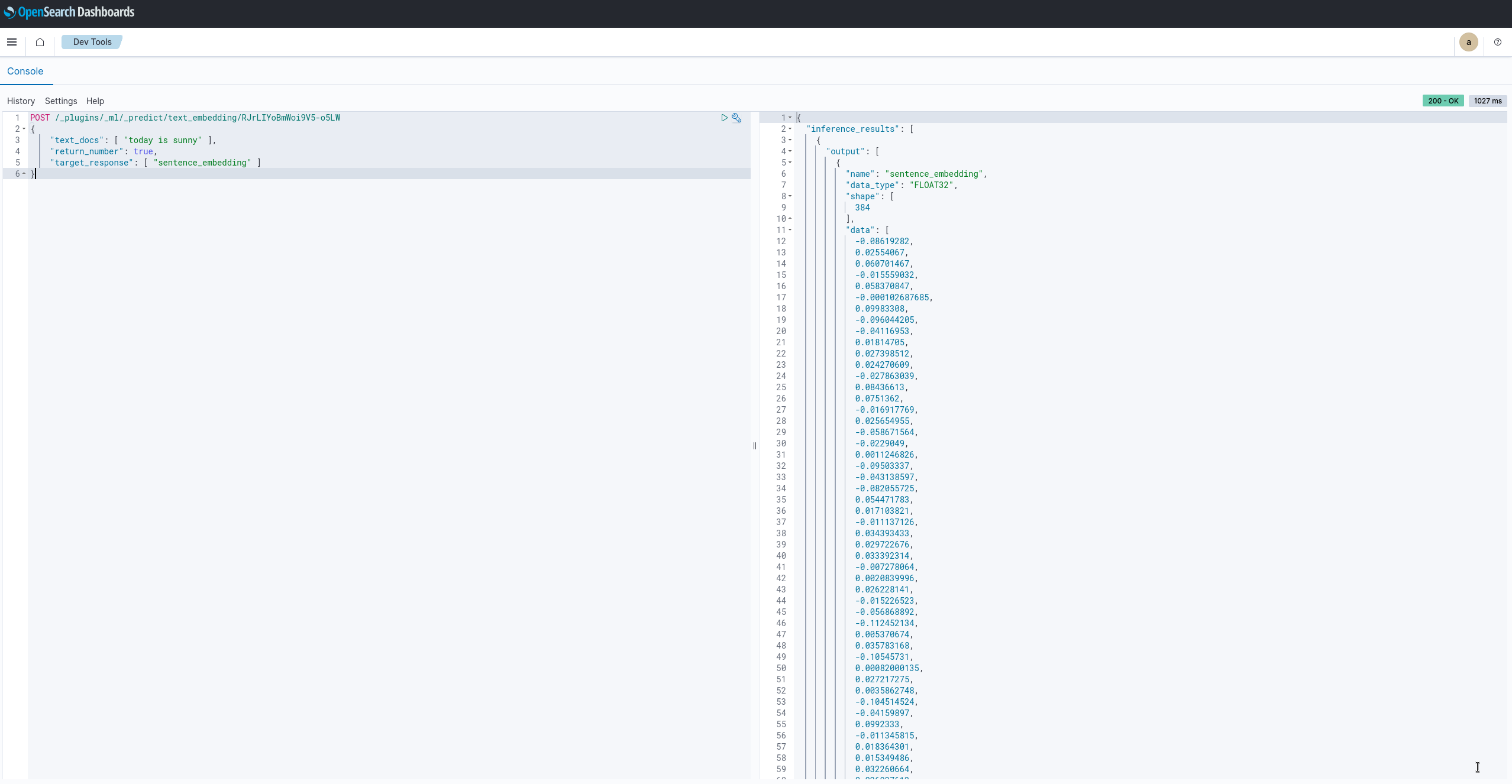
Can ChatGPT be the Solution?
As a proof-of-concept, Leanne decided to test ChatGPT’s effectiveness in real-world scenarios, using ChatGPT’s LLM and Elasticsearch instead of OpenSearch because more information was available on the former during ChatGPT’s training.
The data used for the tests were the Kibana sample data sets.
Leanne’s approach was to give the LLM a general data mapping, similar to the one returned by the API provided by Elasticsearch, and then ask it a humanised question about which data it should return. Keeping that in mind, this proof of concept will be considered a success if the answers returned consist of valid search queries with a low failure rate.
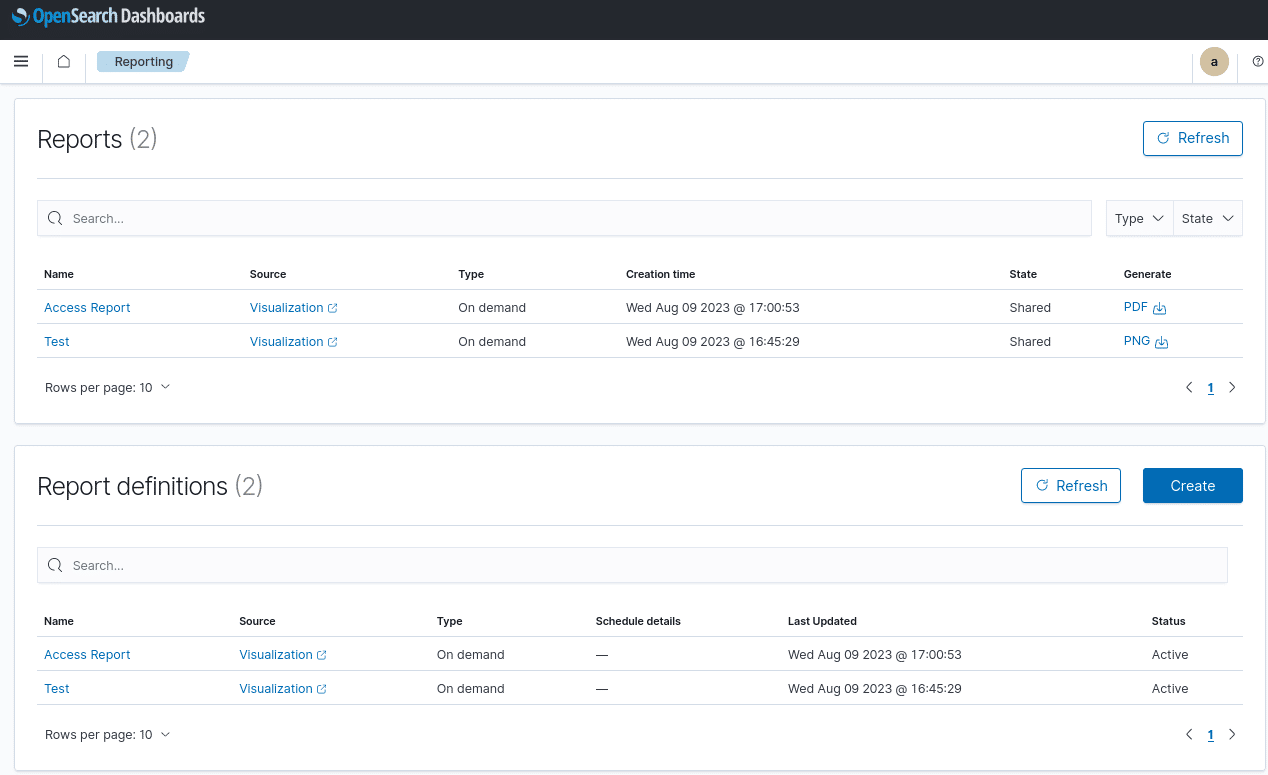
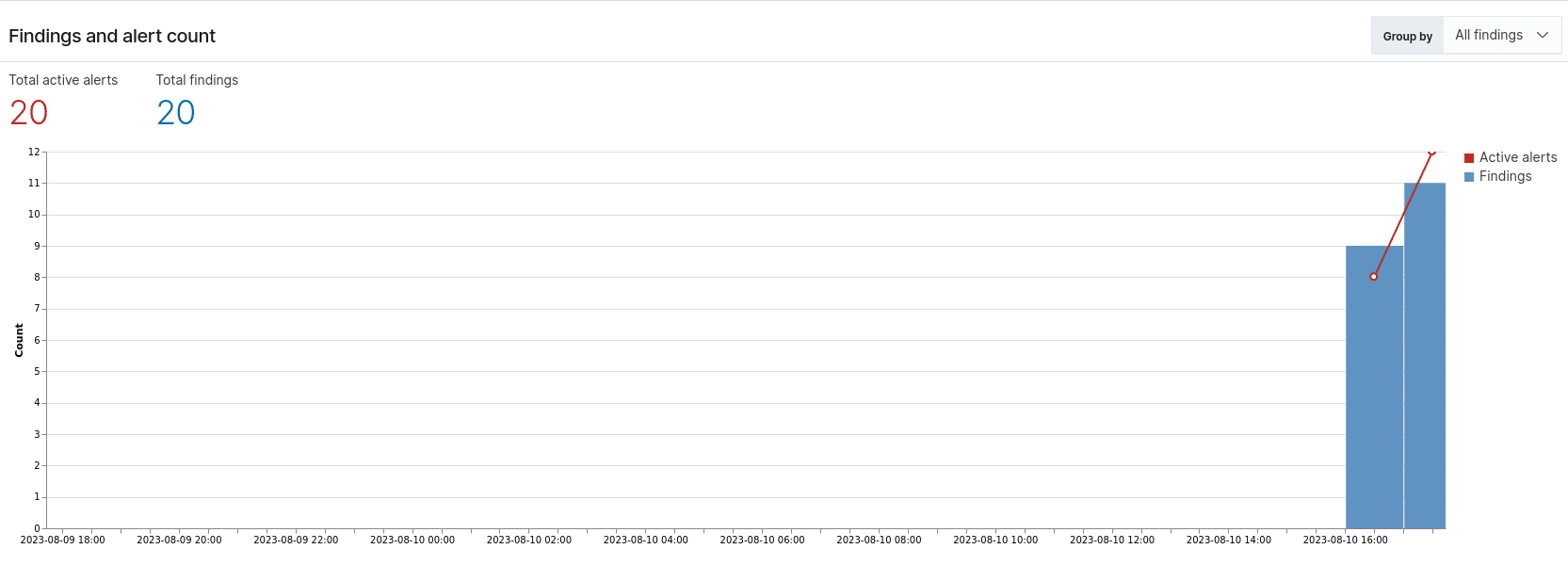
Performance Analysis
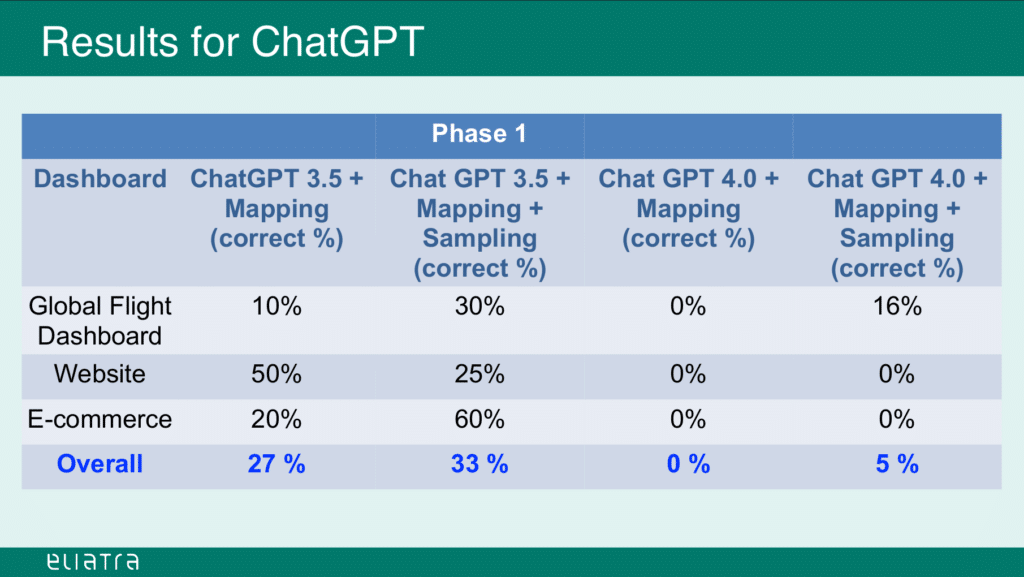
Source: slideshare.net (slide 14)
As we can see, the generated queries achieved only 33% overall correctness. And this level was only possible by feeding the LLM with a number of sample mappings and the queries that were manually generated for them.
Now, this accuracy could be further improved by providing more information about the mapping structures, and by submitting a large number of sample mappings and queries to the ChatGPT instance.
This would however result in much more effort in terms of compiling and providing the sample datasets, and would still have a high chance of failure for any submitted prompts that deviate from the trained sample data.
Vector Search: An Abstract Approach
Is there a better solution to this problem? Jochen presents another approach that falls under the category of semantic search.
Large language models can handle various inputs, and the type of input used can significantly impact the results produced by such a model.
With this in mind, we can transform our input information into vectors using transformers.
The transformers are trained LLM models that process specific types of input, for example video, audio, text, and so on.
They generate n-dimensional vectors that can be stored in a vector database.
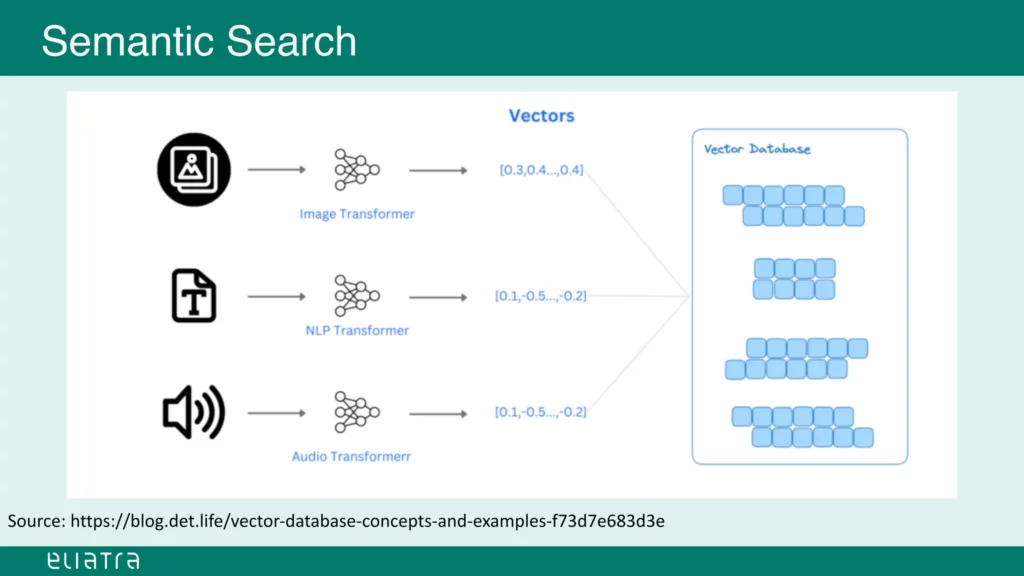
Source: slideshare.net (slide 20)
When searching a vector-based database, one frequently used algorithm for generating result sets is the ‘K-NN index’
(k-nearest-neighbour index). This algorithm compares stored vectors for similarity and provides an approximation of their relevance to other vectors.
For instance, pictures of cats can be transformed into a vector database. The transformer translates the input into a numeric, vectorized format.
The vector database compares the transformed input to the stored vectors using the K-NN algorithm and returns the most fitting vectors for the input.
Are Vectors the Jack of all Trades?
There are some drawbacks to the aforementioned approach. Firstly, the quality of the output heavily depends on the suitability between the transformer and the inputs provided.
Additionally, this method requires significantly more processing power to perform these tasks, which in a dense and highly populated environment could be the bottleneck of such an approach.
It is also difficult to optimize and refine existing models when they only output abstract vectors and are represented as black boxes.
What if we could combine the benefits of both approaches, using lexical and vectorized search?
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) was first mentioned in a 2020 paper by Meta. The paper explains how LLMs can be combined with external data sources to improve search results.
This overcomes the problem of stagnating/freezing models, in contrast to normal LLM approaches. Typically, models get pre-trained with a specific set of data.
However, the information provided by this training data can quickly become obsolete and there may be a need to use a model that also incorporates current developments, the latest technology and currently available information.
Augmented generation involves executing a prompt against an information database, which can be of any type (such as the vector database used in the examples above).
The result set is combined with contextual information, for example the latest data available on the Internet or some other external source, like a flight plan database.
This combined set could then be used as a prompt for another large language model, which would produce the final result against the initial prompt.
In conclusion, multiple LLMs could be joined together while using their own strengths and giving them access to current data sources and that could in turn generate more accurate and up to date answers for user prompts.
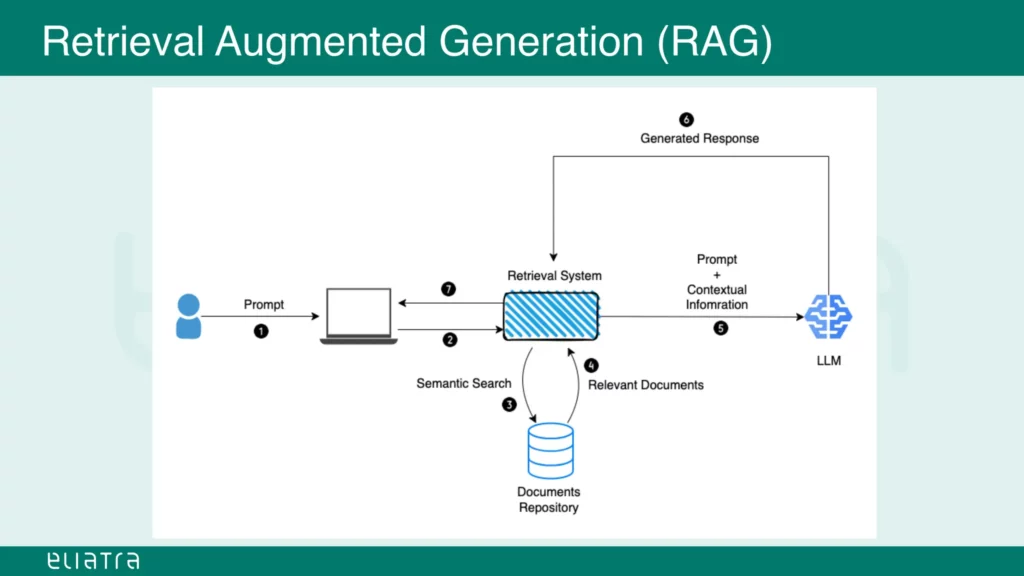
Source: slideshare.net (slide 36)