OpenSearch – Runde I
Worum geht es in der Serie? Wir wollen mit Euch erste Blicke in die frühen Versuche von OpenSearch und dessen Dashboard (OpenSearch Dashboards) werfen, welche je einen Fork durch AMAZON AWS von Elasticsearch-OSS 7.10.x (OpenSearch) und Kibana-OSS 7.10.x abbilden.
Wie es dazu kam, dürft Ihr in diesem Blog-Post von mir lesen. Dieses „Community“ Projekt könnte man, aufgrund der Hintergründe, als Nebenprodukt des Bezahl-Dienstes „Elasticsearch“ in der Amazon AWS Cloud bezeichnen, da es den Fortbestand dieses Dienstes sichern soll. Dieser war aufgrund der „Wehrhaftigkeit“ von Elastic gefährdet.
Nach über 8 Jahren Erfahrung mit Elastic Stack und Graylog, dachte ich mir zu Beginn des Jahres das wir mal mit OpenSearch in den Ring steigen. Mit der Zeit entwickelte sich der Trainings-Partner weiter und es gibt nun ein wenig her um davon zu berichten. Letzten Endes bleibt es aber auf unabsehbare Zeit dabei, dass OpenSearch und OpenSearch Dashboards, als „Open Source Community Projekt“ getarnte Quelle für den Amazon AWS Dienst dienen. Was bedeutet das es keine Support-Garantie, oder ähnliche Strukturen um diese Dienste aus dem Projekt-Kreis selbst geben wird. Allerdings treten schon die ersten Firmen auf, welche eine Support- (mit SLA), Consulting- und Fehlerbehebung als Service anbieten, jedoch bisher keine im deutschsprachigen Raum.
Worum geht also nun der erste Teil? Wir wollen uns mit OpenSearch und OpenSearch Dashboards auseinander setzen und Euch einen Weg zum ersten eigenen Betrieb aufzeigen.
Installationsquellen und Veröffentlichungen
Zum aktuellen Zeitpunkt gibt es tarballs für Linux: x64, ARM64, System-Pakete für FreeBSD: x64, ARM64, x86 und Docker-Images. Ein Release von stabilen Linux-Paketen und einem möglichen Paket-Repository ist für die nächste Veröffentlichung v1.2 am 16. November. 2021 angedacht, so zumindest der Fahrplan.
Im weiteren Verlauf werden wir uns für die ersten Versuche mittels Docker eine Testumgebung aufbauen. Zuerst wollen wir jedoch auf den Umfang von OpenSearch eingehen.
Funktionen von OpenSearch
OpenSearch ist in weiten Teilen mit Elasticsearch und Kibana aus der aktuellen Elastic-Stack Version in Bezug auf Templates und weiteren Funktionen gleich. Lediglich für die Einlieferung und der damit zusammen hängenden Funktionen gibt es wesentliche Unterschiede. Zum Zeitpunkt der Tests ist die Einlieferung nur mit Filebeat-OSS 7.12.1 oder logstash-7.13.2 in Verbindung mit dem Plugin „logstash-output-opensearch“ möglich.
Was hat nun funktioniert bzw. nicht?
- Einliefern mit Standard-Inputs
- Einliefern mit Modulen in OpenSearch
- Laden der Ingest-Pipeline in OpenSearch
- Einliefern mit Logstash (bedingt)
- ILM und Index Management waren nicht möglich!
Letzteres sind nicht ganz so schöne Dinge, aber nun gut, später mehr.
Was ist denn wichtig und gleich aufgebaut wie in Elasticsearch?
- Template API
- Ingest Pipeline API
- Index-Management (teilweise)
Folgende Plugins bringt OpenSearch mit sich:
- opensearch-job-scheduler
- opensearch-sql
- opensearch-alerting
- opensearch-security
- opensearch-cross-cluster-replication
- opensearch-performance-analyzer
- opensearch-index-management
- opensearch-knn
- opensearch-anomaly-detection
- opensearch-asynchronous-search
- opensearch-reports-scheduler
- opensearch-notebooks
Einige davon werden wir uns in Runde III genauer ansehen, diese Plugins bilden auch die Grundlage für einige Dashboard-Integrationen um z.B Alarmierungen, Notizen oder Berechtigungen in Form von Rollen und Benutzern zu verwalten. OpenSearch Dashboards nutzt somit die Plugins von OpenSearch.
Funktionen von OpenSearch Dashboards
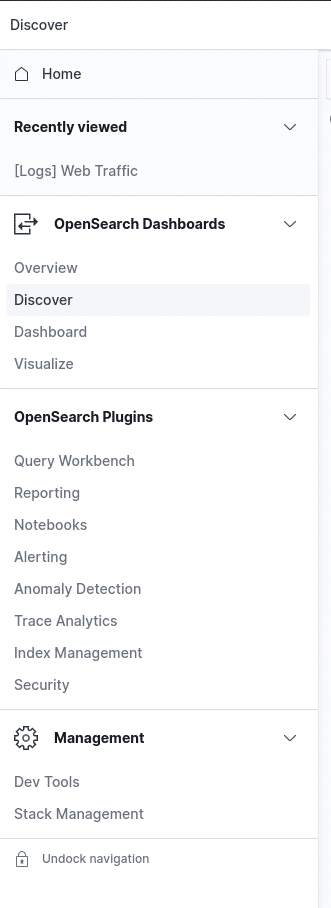
Hier gibt es einiges Neues aber auch einiges was fehlt.
Folgend das Wichtigste und die neuesten Dinge:
- Suche in den Daten
- Dashboards
- Visualisierungen
- Reporting (NEU)
- Notebooks (NEU)
- Anomaly Detction
- Index-Management; jedoch ohnne Index-Template Management!
Los Geht’s
Im folgenden Szenario gehen wir von einem Linux-Arbeitsplatz aus! Daher kommt gleich das Wichtigste zuerst! Wir gehen auch davon aus, dass eine funktionierende Docker-Umgebung auf dem Arbeitsplatz oder Zugriff auf eine solche besteht!
Die Container können übrigens in der richtigen Umgebung auch produktiv eingesetzt werden. Solche Umgebungen bekommt Ihr in Form von Kubernetes auch bei unseren Kollegen von NMS
Vorbereitung ist alles!
Für den Betrieb der Container brauchen wir, egal wie viel Last wir erzeugen, einen erhöhten „<code>vm.max_map_count</code> Wert.
Dies erledigt man wie folgt:
[code lang=“plain“]
# entweder dauerhaft
$ sudo echo "vm.max_map_count=262144" &amp;amp;gt;&amp;amp;gt; /etc/sysctl.conf
$ sudo sysctl -p
# Oder temporär
$ sudo sysctl -w vm.max_map_count=262144
$ sudo sysctl -p
[/code]
Wir setzen unsere Umgebung zusammen
Dafür benötigen wir nichts weiter als eine einfache Docker-Compose Beschreibung in einer Datei:
[code lang=“yaml“]
version: ‚3‘
services:
opensearch-node1: # Wählt hier euren Namen für eure Knoten
image: opensearchproject/opensearch:latest # Lädt immer die letzte stabile Veröffentlichung eines Abbild
container_name: opensearch-node1
environment:
– cluster.name=opensearch-cluster # Euer Cluster-Name
– node.name=opensearch-node1 # Wählt hier euren Namen für eure Knoten
– discovery.seed_hosts=opensearch-node1,opensearch-node2 # Knoten zur Cluster erkennung
– cluster.initial_master_nodes=opensearch-node1,opensearch-node2
– bootstrap.memory_lock=true # along with the memlock settings below, disables swapping
# – jedes weitere beliebige elasticsearch Einstellung wie Knoten-Typ oder Knoten Eigenschaften (node.attr.)
– "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # minimum and maximum Java heap size, recommend setting both to 50% of system RAM
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536 # maximum number of open files for the OpenSearch user, set to at least 65536 on modern systems
hard: 65536
volumes:
– opensearch-data1:/usr/share/opensearch/data # keine dauerhaften Daten! Pfad im Container
# Wollt hier die Knoten dauerhaft betreiben empfiehlt es sich einen dauerhaften lokalen Pfad abzubilden um die Daten nicht zu verlieren
# – ./srv/opensearch-data1:/usr/share/opensearch/data
– 9200:9200
– 9600:9600 # required for Performance Analyzer
networks:
– opensearch-net
opensearch-node2:
image: opensearchproject/opensearch:latest
container_name: opensearch-node2
environment:
– cluster.name=opensearch-cluster
– node.name=opensearch-node2
– discovery.seed_hosts=opensearch-node1,opensearch-node2
– cluster.initial_master_nodes=opensearch-node1,opensearch-node2
– bootstrap.memory_lock=true
– "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
– opensearch-data2:/usr/share/opensearch/data
networks:
– opensearch-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
ports:
– 5601:5601
expose:
– "5601"
environment:
OPENSEARCH_HOSTS: ‚["https://opensearch-node1:9200","https://opensearch-node2:9200"]‘
networks:
– opensearch-net
volumes:
opensearch-data1: # bitte beides auskommentieren für dauerhafte Daten, siehe oben.
opensearch-data2:
networks:
opensearch-net:
[/code]
Die Netzwerkeinstellungen im obigen Konfigurationsbeispiel sind für eine Portweiterleitung gesetzt. Im Folgenden gehen wir davon aus, dass das Notebook die beispielhafte IP 192.168.2.42 hat.
Nun starten wir aus dem Verzeichnis heraus, unsere Komposition und lassen alles zusammen spielen:
[code lang=“plain“]
$ docker-compose up
Starting opensearch-node1 … done
Starting opensearch-dashboards … done
Starting opensearch-node2 … done
Attaching to opensearch-node2, opensearch-node1, opensearch-dashboards
opensearch-node2 | [2021-10-11T17:15:44,498][INFO ][o.o.n.Node ] [opensearch-node2] version[1.0.0], pid[11], build[tar/34550c5b17124ddc59458ef774f6b43a086522e3/2021-07-02T23:22:21.383695Z], OS[Linux/5.10.0-8-amd64/amd64], JVM[AdoptOpenJD
K/OpenJDK 64-Bit Server VM/15.0.1/15.0.1+9]
opensearch-node2 | [2021-10-11T17:15:44,501][INFO ][o.o.n.Node ] [opensearch-node2] JVM home [/usr/share/opensearch/jdk], using bundled JDK [true]
opensearch-node2 | [2021-10-11T17:15:44,501][INFO ][o.o.n.Node ] [opensearch-node2] JVM arguments [-Xshare:auto, -Dopensearch.networkaddress.cache.ttl=60, -Dopensearch.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -D
java.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -XX:+ShowCodeDetailsInExceptionMessages, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dio.netty.al
locator.numDirectArenas=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.locale.providers=SPI,COMPAT, -Xms1g, -Xmx1g, -XX:+UseG1GC, -XX:G1ReservePercent=25, -XX:InitiatingHeapOccupancyPercent=30, -Djava.io.tmpdir=/tmp/opensearch-1450963
1834068960625, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Dclk.tck=100, -Djdk.attach.allowAttachSelf=true, -Djava.
security.policy=/usr/share/opensearch/plugins/opensearch-performance-analyzer/pa_config/opensearch_security.policy, -Dopensearch.cgroups.hierarchy.override=/, -Xms512m, -Xmx512m, -XX:MaxDirectMemorySize=268435456, -Dopensearch.path.home=/usr/share/opensearch,
-Dopensearch.path.conf=/usr/share/opensearch/config, -Dopensearch.distribution.type=tar, -Dopensearch.bundled_jdk=true]
opensearch-node1 | [2021-10-11T17:15:44,792][INFO ][o.o.n.Node ] [opensearch-node1] version[1.0.0], pid[11], build[tar/34550c5b17124ddc59458ef774f6b43a086522e3/2021-07-02T23:22:21.383695Z], OS[Linux/5.10.0-8-amd64/amd64], JVM[AdoptOpenJD
K/OpenJDK 64-Bit Server VM/15.0.1/15.0.1+9]
opensearch-node1 | [2021-10-11T17:15:44,794][INFO ][o.o.n.Node ] [opensearch-node1] JVM home [/usr/share/opensearch/jdk], using bundled JDK [true]
opensearch-node1 | [2021-10-11T17:15:44,794][INFO ][o.o.n.Node ] [opensearch-node1] JVM arguments [-Xshare:auto, -Dopensearch.networkaddress.cache.ttl=60, -Dopensearch.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -XX:+ShowCodeDetailsInExceptionMessages, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dio.netty.al
locator.numDirectArenas=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.locale.providers=SPI,COMPAT, -Xms1g, -Xmx1g, -XX:+UseG1GC, -XX:G1ReservePercent=25, -XX:InitiatingHeapOccupancyPercent=30, -Djava.io.tmpdir=/tmp/opensearch-1753077
5664832230117, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Dclk.tck=100, -Djdk.attach.allowAttachSelf=true, -Djava.security.policy=/usr/share/opensearch/plugins/opensearch-performance-analyzer/pa_config/opensearch_security.policy, -Dopensearch.cgroups.hierarchy.override=/, -Xms512m, -Xmx512m, -XX:MaxDirectMemorySize=268435456, -Dopensearch.path.home=/usr/share/opensearch,
-Dopensearch.path.conf=/usr/share/opensearch/config, -Dopensearch.distribution.type=tar, -Dopensearch.bundled_jdk=true]
opensearch-node2 | [2021-10-11T17:15:45,739][INFO ][o.o.s.s.t.SSLConfig ] [opensearch-node2] SSL dual mode is disabled
opensearch-node2 | [2021-10-11T17:15:45,740][INFO ][o.o.s.OpenSearchSecurityPlugin] [opensearch-node2] OpenSearch Config path is /usr/share/opensearch/config
opensearch-node1 | [2021-10-11T17:15:45,863][INFO ][o.o.s.s.t.SSLConfig ] [opensearch-node1] SSL dual mode is disabled
opensearch-node1 | [2021-10-11T17:15:45,863][INFO ][o.o.s.OpenSearchSecurityPlugin] [opensearch-node1] OpenSearch Config path is /usr/share/opensearch/config
opensearch-dashboards | {"type":"log","@timestamp":"2021-10-11T17:15:45Z","tags":["info","plugins-service"],"pid":1,"message":"Plugin \"visTypeXy\" is disabled."}
opensearch-node2 | [2021-10-11T17:15:45,991][INFO ][o.o.s.s.DefaultSecurityKeyStore] [opensearch-node2] JVM supports TLSv1.3
opensearch-node2 | [2021-10-11T17:15:45,992][INFO ][o.o.s.s.DefaultSecurityKeyStore] [opensearch-node2] Config directory is /usr/share/opensearch/config/, from there the key- and truststore files are resolved relatively
opensearch-dashboards | {"type":"log","@timestamp":"2021-10-11T17:15:46Z","tags":["warning","config","deprecation"],"pid":1,"message":"\"cpu.cgroup.path.override\" is deprecated and has been replaced by \"ops.cGroupOverrides.cpuPath\""}
opensearch-dashboards | {"type":"log","@timestamp":"2021-10-11T17:15:46Z","tags":["warning","config","deprecation"],"pid":1,"message":"\"cpuacct.cgroup.path.override\" is deprecated and has been replaced by \"ops.cGroupOverrides.cpuAcctPath\""}
opensearch-node1 | [2021-10-11T17:15:46,131][INFO ][o.o.s.s.DefaultSecurityKeyStore] [opensearch-node1] JVM supports TLSv1.3
opensearch-node1 | [2021-10-11T17:15:46,132][INFO ][o.o.s.s.DefaultSecurityKeyStore] [opensearch-node1] Config directory is /usr/share/opensearch/config/, from there the key- and truststore files are resolved relatively
opensearch-dashboards | {"type":"log","@timestamp":"2021-10-11T17:15:46Z","tags":["info","plugins-system"],"pid":1,"message":"Setting up [45] plugins: [alertingDashboards,usageCollection,opensearchDashboardsUsageCollection,opensearchDashboardsLegacy,mapsLe
gacy,share,opensearchUiShared,legacyExport,embeddable,expressions,data,home,console,apmOss,management,indexPatternManagement,advancedSettings,savedObjects,securityDashboards,indexManagementDashboards,anomalyDetectionDashboards,dashboard,notebooksDashboards,vi
sualizations,visTypeVega,visTypeTimeline,timeline,visTypeTable,visTypeMarkdown,tileMap,regionMap,inputControlVis,ganttChartDashboards,visualize,reportsDashboards,traceAnalyticsDashboards,queryWorkbenchDashboards,charts,visTypeVislib,visTypeTimeseries,visTypeT
agcloud,visTypeMetric,discover,savedObjectsManagement,bfetch]"}
[/code]
Und ja ich gebe es zu, ich hatte alles schon mal am Laufen!
Nun prüfen wir ob alles läuft!
Im Standard wird OpenSearch und OpenSearch Dashboards bereits mit Zertifikaten und einer Absicherung ausgerollt. Der Standard-Benutzer ist „admin“ und auch das Passwort lautet „admin“. Bitte denkt daran das es sich um selbst signierte Zertifikate handelt! Dies ist bei allen Anbindungen zu beachten (ssl.verification_mode: none).
[code lang=“plain“]
$ curl -k -u "admin:admin" -X GET ‚https://192.168.2.42:9200/_cluster/health?pretty‘
{
"cluster_name" : "opensearch-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"discovered_master" : true,
"active_primary_shards" : 12,
"active_shards" : 24,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}[/code]
Und nun ab in die visuelle Ansicht:
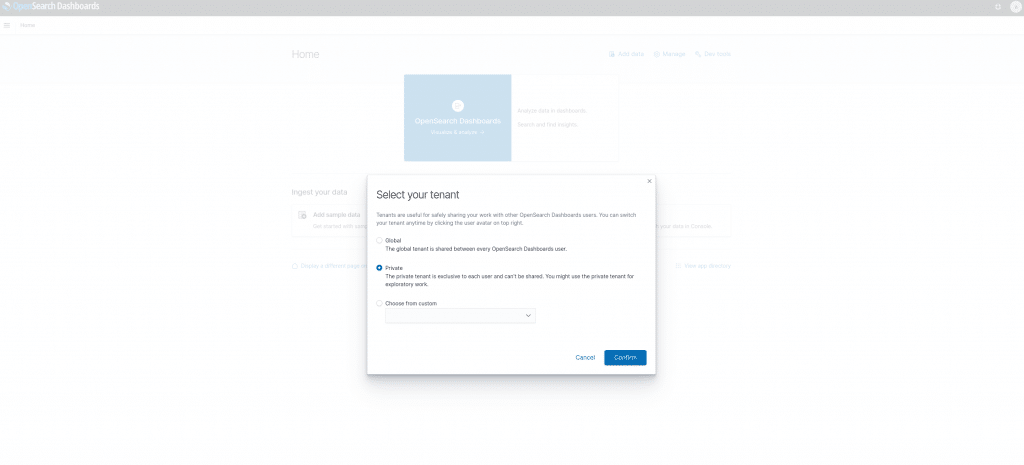
Hier empfiehlt es sich erst mal den Tenant auf Privat zu setzen.
Nun folgt eine kleines Video. Mein erstes Video Tutorial oder was auch immer nur für euch:
Und da ist der Pausengong!
Und schon ist sie rum, die erste Runde und OpenSearch steht noch! Also macht Euch alle bereit für die nächste Runde. Wenn Euch das, was ihr jetzt schon gelesen habt gefällt und Ihr es nicht bis Runde II aushaltet, dann meldet Euch doch einfach bei unserem Sales Team sales[at]netways.de. Wir helfen Euch in einem PoC (Proof of Concept) gleich von Runde I an mit zu kämpfen! Nach den letzten Monaten intensiver OpenSearch Evaluierung bin ich der Trainer der euch „State of the Art“ Euren „Kampf gegen die Informationsflut“ gewinnen lässt.



















