![]() When you are into developing Ruby code, or even Ruby near stuff like Puppet modules, or Chef cookbooks, there is a nice tool you should have a look at.
When you are into developing Ruby code, or even Ruby near stuff like Puppet modules, or Chef cookbooks, there is a nice tool you should have a look at.
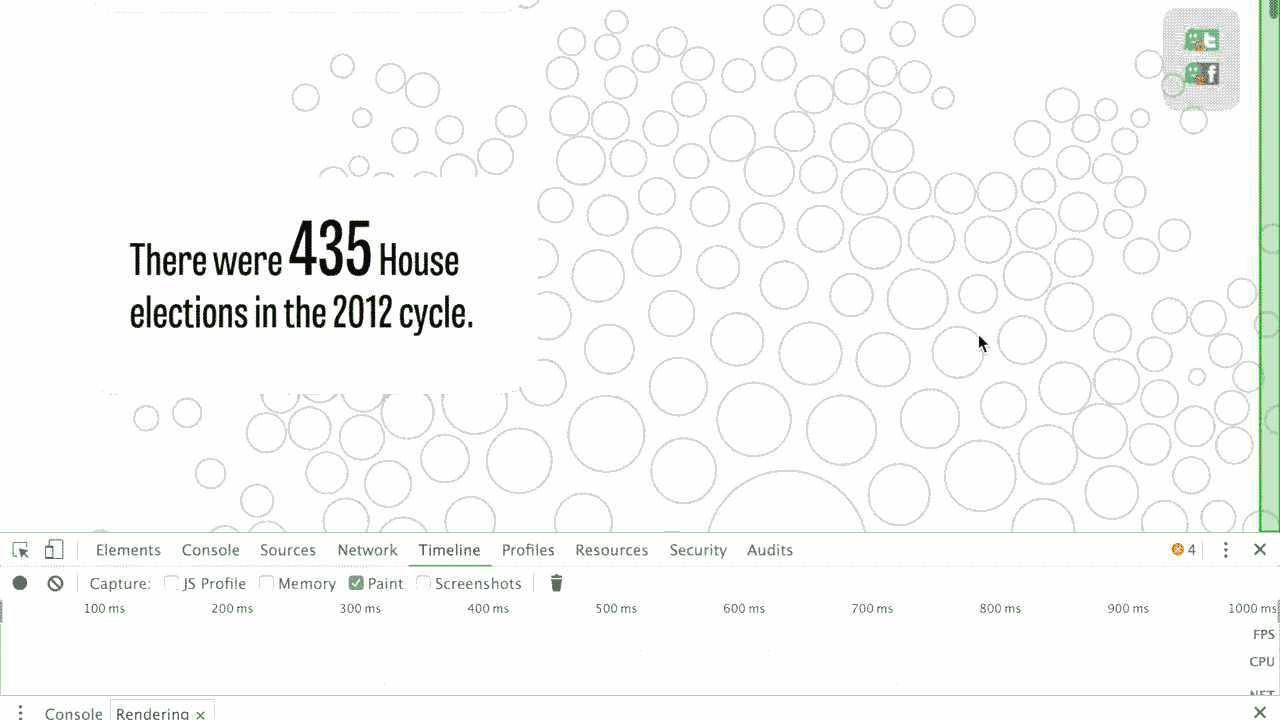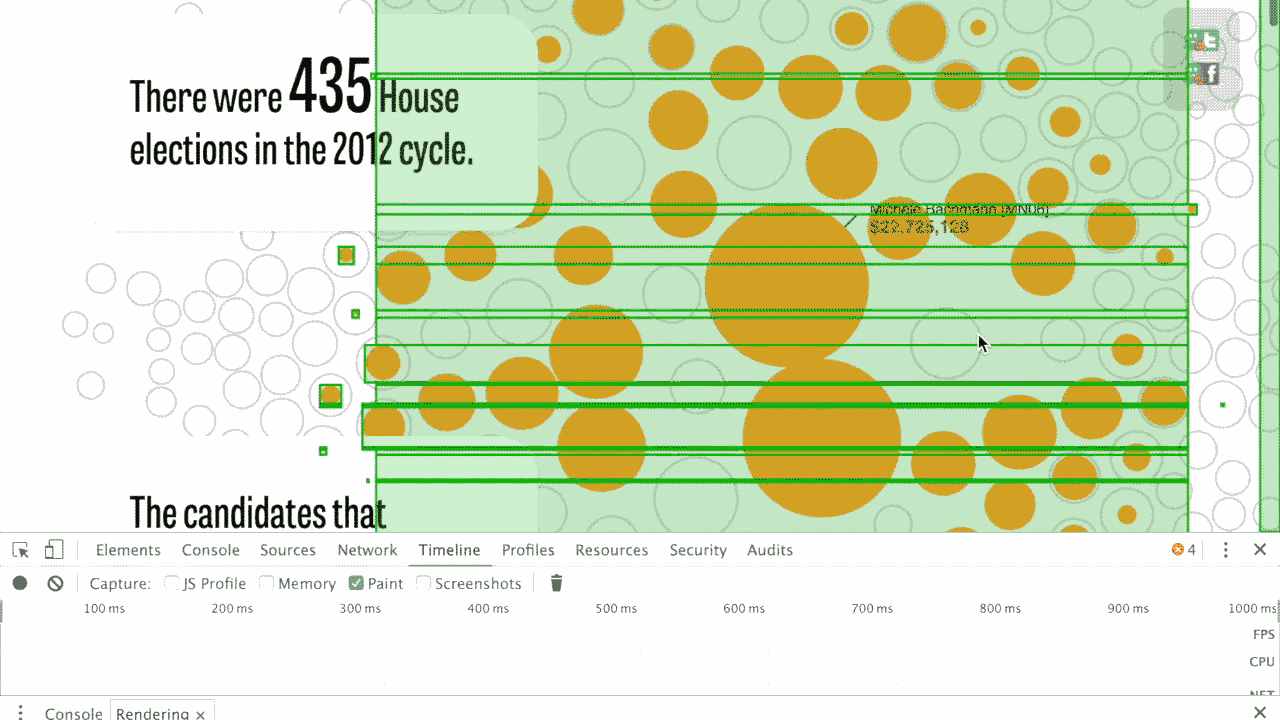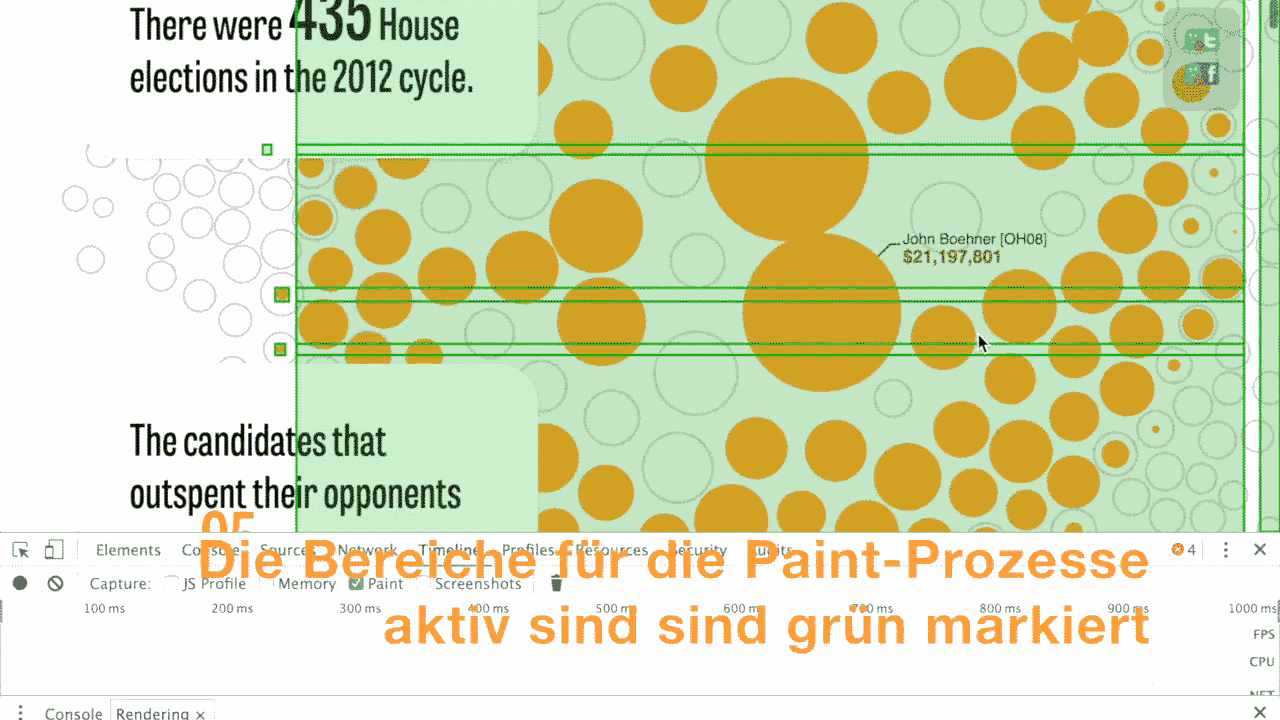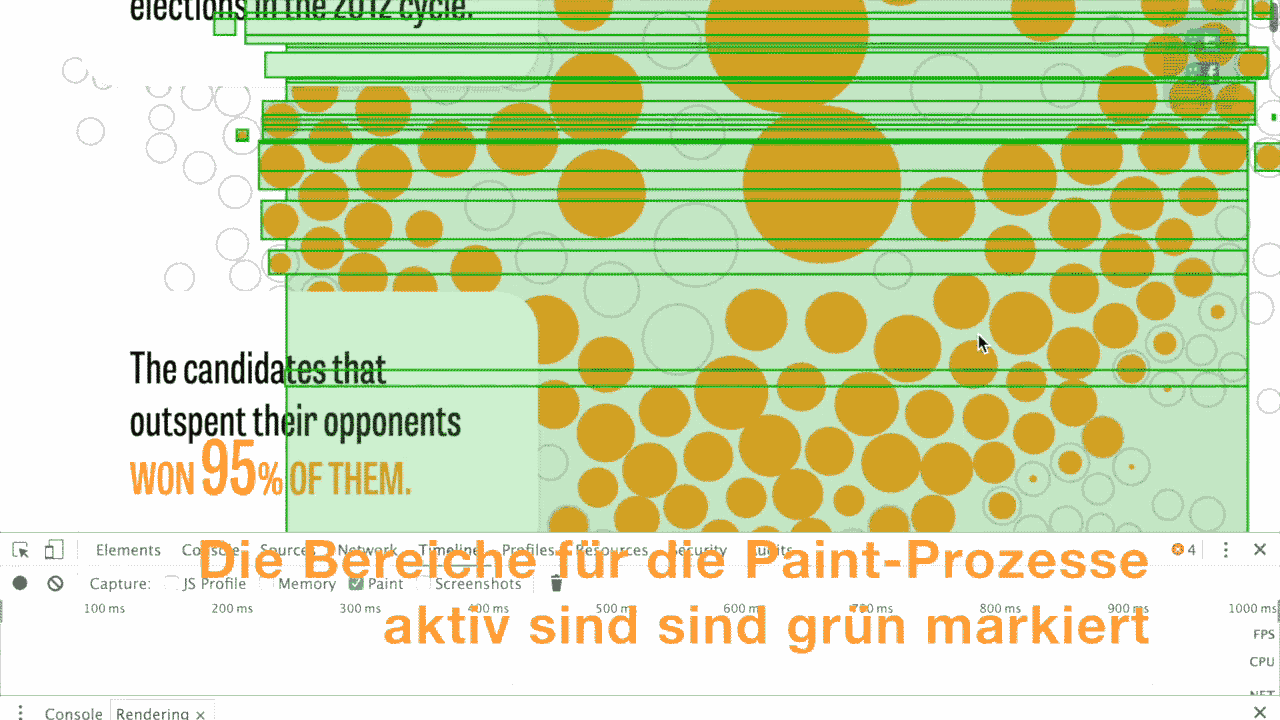
The RuboCop can help you writing better Ruby code, it certainly did it for me.
In short words, RubyCop is a code analyzer that checks Ruby code against common style guidelines and tries to detect a lot of mistakes and errors that you might write into your code.
There are a lot of configuration options, and even an auto-correct functionality, that updates your code.
Simple usage
Either install the gem, or add it to your Gemfile:
gem 'rubocop', require: false
You can just run it without configuration, and it will look for all Ruby files in your work directory.
$ rubocop
Inspecting 19 files
....C............CC
Offenses:
lib/test/cli.rb:3:3: C: Missing top-level class documentation comment.
class CLI
^^^^^
lib/test/cli.rb:36:1: C: Extra empty line detected at method body beginning.
lib/test/cli.rb:41:1: C: Extra empty line detected at block body beginning.
lib/test/cli.rb:45:4: C: Final newline missing.
end
bin/test:12:1: C: Missing space after #.
#api.login('username', 'Passw0rd') unless api.logged_in?
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
bin/test:15:3: C: Missing space after #.
#puts response.code
^^^^^^^^^^^^^^^^^^^
bin/test:19:1: C: Missing space after #.
#session.save(file)
^^^^^^^^^^^^^^^^^^^
18 files inspected, 7 offenses detected
You can add it as a rake job to your Rakefile:
require 'rubocop/rake_task' RuboCop::RakeTask.new task default: [:spec, :rubocop]
And run the test via your rake tests:
$ rake $ rake rubocop
Configuration galore
There are a lot of options to modify the behavior and expectations of RuboCop.
Here is a short example I used with recent Puppet module.
require: rubocop-rspec
AllCops:
TargetRubyVersion: 1.9
Include:
- ./**/*.rb
Exclude:
- vendor/**/*
- .vendor/**/*
- pkg/**/*
- spec/fixtures/**/*
# We don't use rspec in this way
RSpec/DescribeClass:
Enabled: False
RSpec/ImplicitExpect:
Enabled: False
# Example length is not necessarily an indicator of code quality
RSpec/ExampleLength:
Enabled: False
RSpec/NamedSubject:
Enabled: False
Where to go next
- Check the documentation for all the cops (e.g. Linting)
- Check available command line arguments
- Search what other people are doing with Rubocop on GitHub