ich hatte in Vergangenheit bereits einen Blog Post über NodeJS in Verbindung mit dem NodeJS ‚Cluster‘ Modul geschrieben ( siehe hier ), nun möchte ich euch zeigen wie Ihr eure NodeJS Anwendung auch ohne Programmierarbeit (also als reine Ops Tätigkeit) zum Cluster umfunktioniert und wie ihr diese anschließend verwalten könnt.
![]()
Legen wir los, wir benötigen hierzu NodeJS, am besten 4.4 LTS und 4 zusätzliche Module/Helper, fangen wir also mit der Installation an…
$ npm install -g pm2
$ npm install -g express-generator
$ mkdir ~/project && cd project
$ npm install --save express
$ npm install --save sleep
…nun generieren wir das Express Anwendungsgerüst…
$ express -f .
create : .
create : ./package.json
create : ./app.js
create : ./public
create : ./public/javascripts
create : ./public/images
create : ./public/stylesheets
create : ./public/stylesheets/style.css
create : ./routes
create : ./routes/index.js
create : ./routes/users.js
create : ./views
create : ./views/index.jade
create : ./views/layout.jade
create : ./views/error.jade
create : ./bin
create : ./bin/www
install dependencies:
$ cd . && npm install
run the app:
$ DEBUG=project:* npm start
$
… danach löschen wir in der Datei app.js alles von Zeile 13 bis 58, wir benötigen nur das Gerüst selbst und ein paar Zeile selbst geschriebenen Code, um diesen kommen wir leider nicht herum, da wir ja auch was sehen wollen.
Fügt nun ab Zeile 14 folgenden Code hinzu…
var crypto = require( 'crypto' );
var util = require( 'util' );
var sleep = require( 'sleep' ).sleep;
function getRandHash() {
var current_date = (new Date()).valueOf().toString();
var random = Math.random().toString();
return crypto.createHash('sha1').update(current_date + random).digest('hex');
}
var myID = getRandHash();
app.get( '/', function( req, res ) {
sleep( Math.floor( (Math.random() * 3) + 1 ) );
res.send({
"ID": myID,
"PID": process.pid,
"ENV": process.env
});
});
…nun starten wir die App über PM2 im Cluster Mode, hier bitte dem Parameter ‚-i‘ nur einen Wert gleich der Anzahl der CPU Cores mitgeben. Dann testen wir das Ganze doch gleich mal…
$ cd project
$ pm2 start bin/www -i 4
…ihr solltet nun folgende Ausgabe zu sehen bekommen…
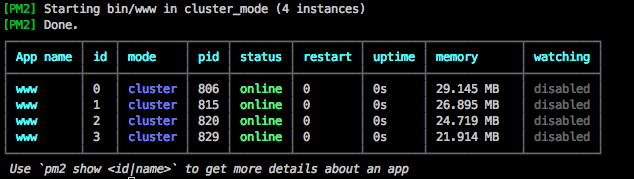
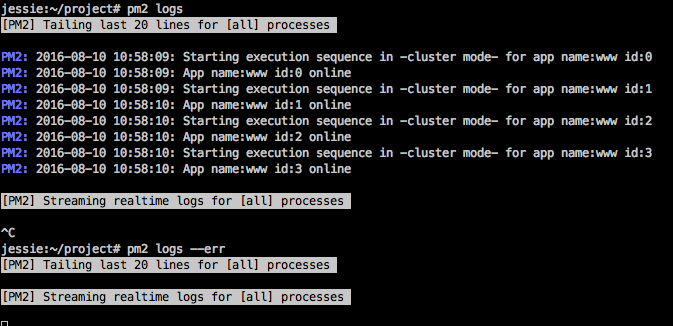
…ihr könnt eure Anwendung auch auf Fehler überprüfen, dafür gibt euch PM2 einen Parameter ‚logs‘ mit, der wiederum einige Flags kennt. Wenn ihr nur ‚pm2 logs‘ eingebt dann bekommt ihr die Standardausgabe unserer Anwendung zu sehen, wenn ihr zusätzlich das Flag ‚–err‘ mit angebt, bekommt ihr die Standard Fehlerausgabe, was für das Debugging recht hilfreich ist.
So, nun könnt ihr in eurem Browser mal die Anwendung aufrufen. Der Listener der Anwendung horcht auf dem Port 3000. Ein Aufruf auf http://127.0.0.1:3000 sollte ein JSON liefern, ähnlich zu dieser Ausgabe hier…
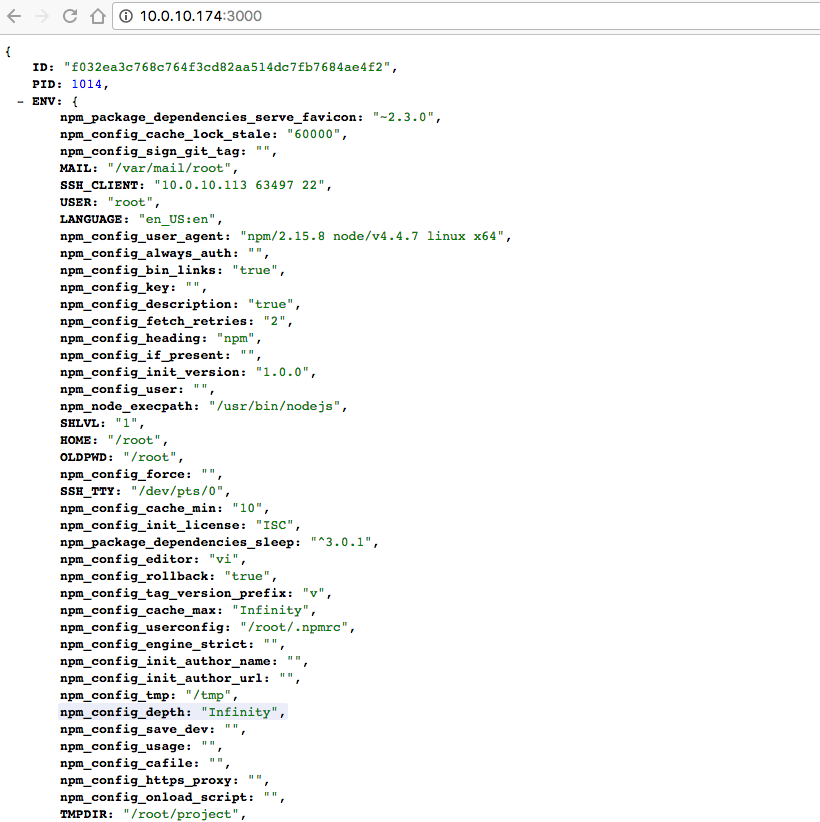
Da wir in unserem Code eine künstliche Verzögerung eingebaut haben, könnt ihr nun mit 2 direkt Aufeinander folgenden Browser Reload sehen das sich die ID u. PID Werte gelegentlich ändern, dies bedeutet, dass unsere Cluster Anwendung funktioniert.
![]()
Ich hoffe ich konnte euch nun zum Spielen und Experimentieren animieren. PM2 wird von der Firma Kissmetrics als OpenSource Project stetig weiter entwickelt und hat noch so viel mehr zu bieten, ganz findige unter euch werden die Monitoring API zu schätzen wissen und diese vmtl. in Icinga2, Graphite, Kibana und anderen Lösungen integrieren wollen.
Dann bis demnächst 🙂




















