
At the Open Source Data Center Conference (OSDC) 2019 in Berlin, Jan Martens invited to audience to travel with him in his talk „Evolution of a Microservice-Infrastructure”. You have missed him speaking? We got something for you: See the video of Jan‘s presentation and read a summary (below).
The former OSDC will be held for the first time in 2020 under the new name stackconf. With the changes in modern IT in recent years, the focus of the conference has increasingly shifted from a mainly static infrastructure approach to a broader spectrum that includes agile methods, continuous integration, container, hybrid and cloud solutions. This development is taken into account by changing the name of the conference and opening the topic area for further innovations.
Due to concerns around the coronavirus (COVID-19), the decision was made to hold stackconf 2020 as an online conference. The online event will now take place from June 16 to 18, 2020. Join us, live online! Save your ticket now at: stackconf.eu/ticket/
Evolution of a Microservice-Infrastructure
Jan Martens signed up with a talk titled “Evolution of a Microservice Infrastructure” and why should I summarize his talk if he had done that himself perfectly: “This talk is about our journey from Ngnix & Docker Swarm to Traefik & Nomad.”
But before we start getting more in depth with this talk, there is one more thing to know about it. This is more or less a sequel to “From Monolith to Microservices” by Paul Puschmann a colleague of Jan Martens, but it’s not absolutely necessary to watch them in order or both.
So there will be a bunch of questions answered by Jan during the talk, regarding their environment, like: “How do we do deployments? How do we do request routing? What problems did we encounter, during our infrastructural growth and how did we address them?”
After giving some quick insight in the scale he has to deal with, that being 345.000 employees and 15.000 shops, he goes on with the history of their infrastructure.
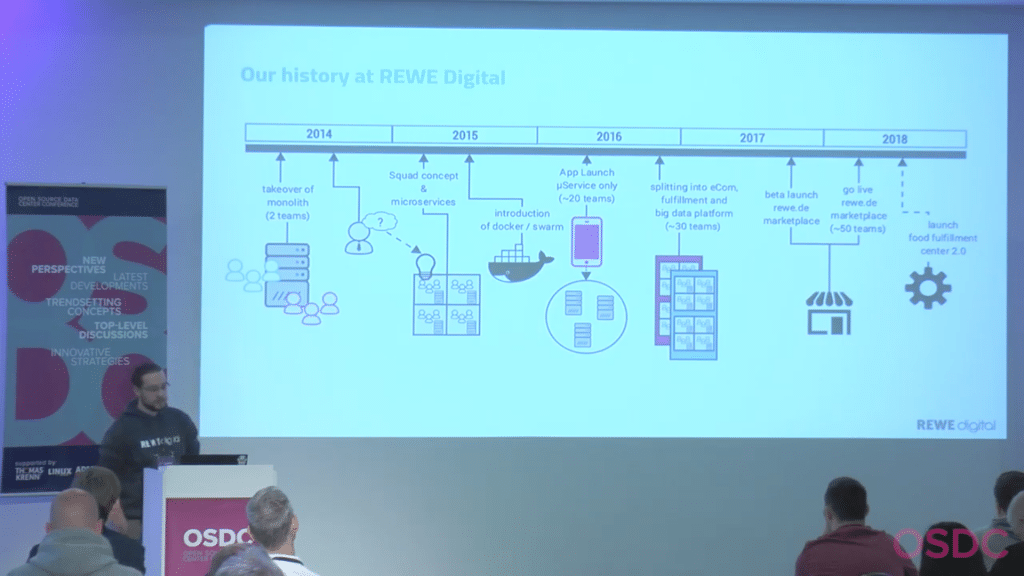
Jan works at REWE Digital, which is responsible for the infrastructure around services, like delivery of groceries. They started off with the takeover of an existing monolithic infrastructure, not very attractive huh? They confronted themselves with the question: “How can we scale this delivery service?” and the solution they came up with was a micro service environment. Important to point out here, would be the use of Docker/Swarm for the deployment of micro services.
Let’s skip ahead a bit and take a look at the state of 2018 REWE Digital. Well there operating custom Docker-Environment consists of: Docker, Consul, Elastic Stack, ngnix, dnsmasq and debian
Jan goes into explaining his infrastructure more and more and how the different applications work with each other, but let’s just say: Everything was fine and peaceful until the size of the environment grew to a certain point. And at that point problems with nginx were starting to surface, like requests which never reached their destination or keepalive connections, which dropped after a short time. The reason? Consul-template would reload all ngnix instances at the same time. The solution? Well they looked for a different reverse proxy, which is able to reload configuration dynamically and best case that new reverse proxy is even able to be configured dynamically.
The three being deemed fitting for that job were envoy, Fabio and traefik, but I have already spoiled their decision, its treafik. The points Jan mentioned, which had them decide on traefik were that it is dynamically configurable and is able to reload configuration live. That’s obviously not all, lots of metrics, a web ui, which was deemed nice by Jan and a single go binary, might have made the difference.
Jan drops a few words on how migration is done and then invests some time in talking about the benefits of traefik, well the most important benefit for us to know is, that the issues that existed with ngnix are gone now.
Well now that the environment was changed, there were also changes coming for swarm, acting on its own. The problems Jan addresses are a poor container spread, no self-healing, and more. You should be able to see where this is going. Well the candidates besides Docker Swarm are Rancher, Kubernetes and Nomad. Well, this one was spoiled by me as well.
The reasons to use nomad in this infrastructure might be pretty obvious, but I will list them anyway. Firstly, seamless consul integration, well both are by HashiCorp, who would have guessed. Nomad is able to selfheal and comes in a single go binary, just like traefik. Jan also claims it has a nice web UI, we have to take his word on that one.
Jan goes into the benefits of using Nomad, just like he went into the benefits of ngnix and shows how their work processes have changed with the change of their environment.
This post doesn’t give enough credit to how much information Jan has shared during his talk. Maybe roughly twenty percent of his talk are covered here. You should definitely check it out the full video to catch all the deeper more insightful topics about the infrastructure and how the applications work with each other.






















