Bei unseren Online-Trainings von NETWAYS, werden jedem einzelnen Teilnehmer eine oder mehrere explizite VMs zur Verfügung gestellt, welche in der OpenStack-Umgebung von NWS gehostet werden. Hierbei benötigen die VMs jeweils öffentliche IPs, welche leider nicht unendlich zu Verfügung stehen. Aus dieser Prämisse heraus entstand die Idee, einen sog. reverse Proxy zu benutzen, welcher Anfragen von Clients an Webserver weiterleitet – in diesem Fall an die entsprechende VM.
Das Problem an dieser Stelle ist, dass es für Traefik noch keinen Provider für OpenStack gibt. Daher wurde ein experimenteller openstack-provider entwickelt, welchen ich hier kurz vorstelle.
Funktionsweise des openstack-providers
Der openstack-traefik-provider benutzt den http-provider von Traefik um die VMs/Instanzen innerhalb eines OpenStack-Projektes zu suchen/finden. Damit Traefik die Informationen über die Instanzen erhält, wird ein OpenStack-Go-Client innerhalb eines Docker-Containers gestartet, welcher anschließend über die URL http://openstack:8080/traefik (diese URL kann im Code selbst angepasst werden), alle Informationen des Projektes über ein HTTP-Response zur Verfügung stellt. Traefik selbst pollt alle 10 sek. von dieser Adresse, um die Routen, Middlewares, etc. zu aktualisieren.
Beispielhafte Konfiguration
Jeglicher HTTPS-Traffic soll am Proxy terminiert werden, sodass innerhalb des internen Netzwerks HTTP benutzt wird:
main.go
[...]
settings := discovery.DefaultSettings
settings.DefaultRule = "Host(`{{ .Name }}.trainig.netways.de`)"
settings.DefaultEnable = true
settings.AddressType = "floating"
settings.DefaultLabels = map[string]string{
// HTTP
"traefik.http.routers.{{ .Name }}-http.service": "{{ .Name }}-http",
"traefik.http.routers.{{ .Name }}-http.rule": "Host(`{{ .Name }}.trainig.netways.de`)",
"traefik.http.routers.{{ .Name }}-http.entrypoints": "http",
"traefik.http.services.{{ .Name }}-http.loadBalancer.server.port": "80",
"traefik.http.routers.{{ .Name }}-http.middlewares": "http-to-https",
// HTTPS
"traefik.http.routers.{{ .Name }}-https.service": "{{ .Name }}-https",
"traefik.http.routers.{{ .Name }}-https.rule": "Host(`{{ .Name }}.trainig.netways.de`)",
"traefik.http.routers.{{ .Name }}-https.entrypoints": "https",
"traefik.http.services.{{ .Name }}-https.loadBalancer.server.port": "80",
"traefik.http.routers.{{ .Name }}-https.tls": "true",
// Redirect HTTP to HTTPS
"traefik.http.middlewares.http-to-https.redirectscheme.scheme": "https",
"traefik.http.middlewares.http-to-https.redirectscheme.permanent": "true",
}
[...]
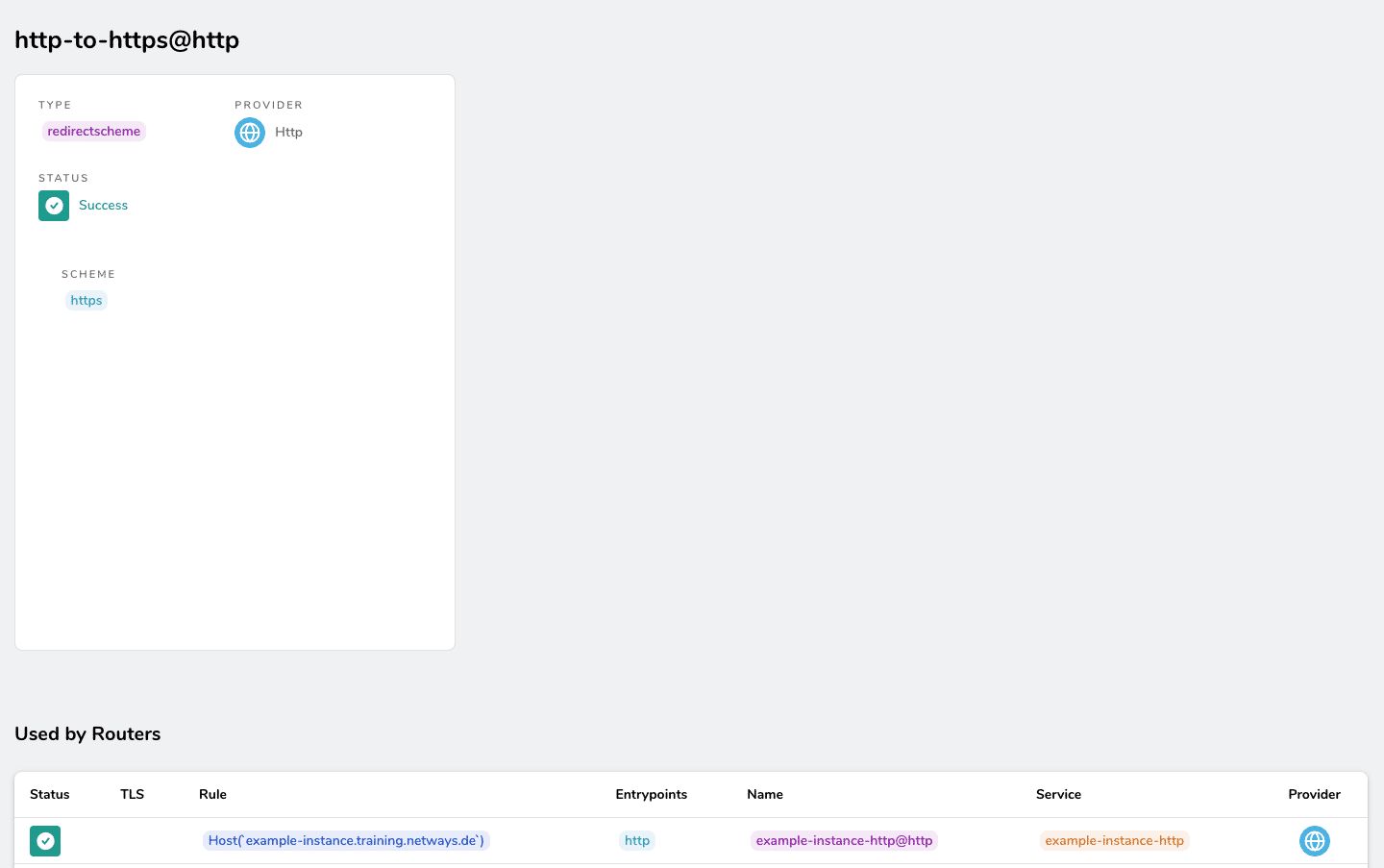
Anschließend muss über den Befehl docker-compose up der Docker-Container mit der neuen Konfiguration gestartet werden und die Routen + Middleware sollten im Frontend zu sehen sein:
Da das Projekt sich derzeit noch in Entwicklung befindet, würde ich mich über Vorschläge, PullRequests oder Kritik von der Open Source Community sehr freuen!
Sobald das Projekt abgeschlossen ist, werde ich auch davon berichten!