A Highlight Coming Up
As 2022 is in its last quarter, this year’s event season is also slowly coming to an end. But there’s one last big highlight awaiting us all! After having been to OpenInfra Summit, KubeCon and stackconf (see the flashback below), NWS is now looking forward to attending OSMC as Silver Sponsor! The Open Source Monitoring Conference will take place in Nuremberg from November 14 – 16.
It was a blast at #stackconf – let’s wrap it up with a #team foto!
Lots of interesting connections, insightful talks from great speakers and the #OpenSource #Infrastructure community made this #conference one to remember! Thanks for the amazing time and until next year! pic.twitter.com/4wpe2H1ISY
— NETWAYS Web Services (@NetwaysCloud) July 20, 2022
Who is going?
All good things are three – and sometimes eleven! In addition to myself, Georg, Marc, Michael, Achim, Dominik, Justin, Martin and Jonas will be attending OSMC, plus Leonie and Stefan from the Sales Team. We’ll certainly have other team members keeping the business running smoothly and making sure, any open issues from our customers are being answered.
What can you expect?
I am excited to meet lots of interesting people and get into a chat with them, share experiences and opinions, etc. Of course, the OSMC program with the outstanding selection of speakers is also something we can all look forward to! My personal highlights this year will be Pascal Fries talking about “Monitoring multiple Kubernets Clusters with Thanos” and George Hantzaras talking about “Scaling SLOs with Kubernetes and Cloud Native Observability”. What are yours?
On top of that, we’re planning a few cool things that you can definitely count on – make sure to stop by our booth!
Why should you attend?
What will your take aways and experiences be? Learn, which monitoring and observability solutions are available and how they can best be integrated with other tools.
Besides the main conference, there are also workshops about Kubernetes and more on November 14th. Other than that, the evening event is always a highligh and the perfect opportunity to round up the first conference day on November 15th with great food, drinks and a good time! Trust me: been there, done that 🙂
So, these should be enough reasons for you to be part of the extraordinary event, right? We sure hope to see you around!
Follow us on Twitter to get some first hand impressions of our experience at OSMC 2022!

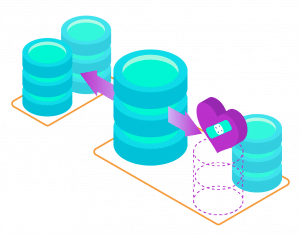

 Vertical scaling can be done by just choosing the next available size of our plans. This is just a click and done in minutes. Read traffic can be accelerated by adding more replicas to the cluster. If you need even more and vertical scaling is no more an option, it’s possible to scale horizontally. This process can be infinitely, so to say. It can be done through sharding and partitioning your data into smaller pieces, which are stored on multiple database instances grouped to single, logical database without reengineering your application. This advanced feature will be explained in
Vertical scaling can be done by just choosing the next available size of our plans. This is just a click and done in minutes. Read traffic can be accelerated by adding more replicas to the cluster. If you need even more and vertical scaling is no more an option, it’s possible to scale horizontally. This process can be infinitely, so to say. It can be done through sharding and partitioning your data into smaller pieces, which are stored on multiple database instances grouped to single, logical database without reengineering your application. This advanced feature will be explained in 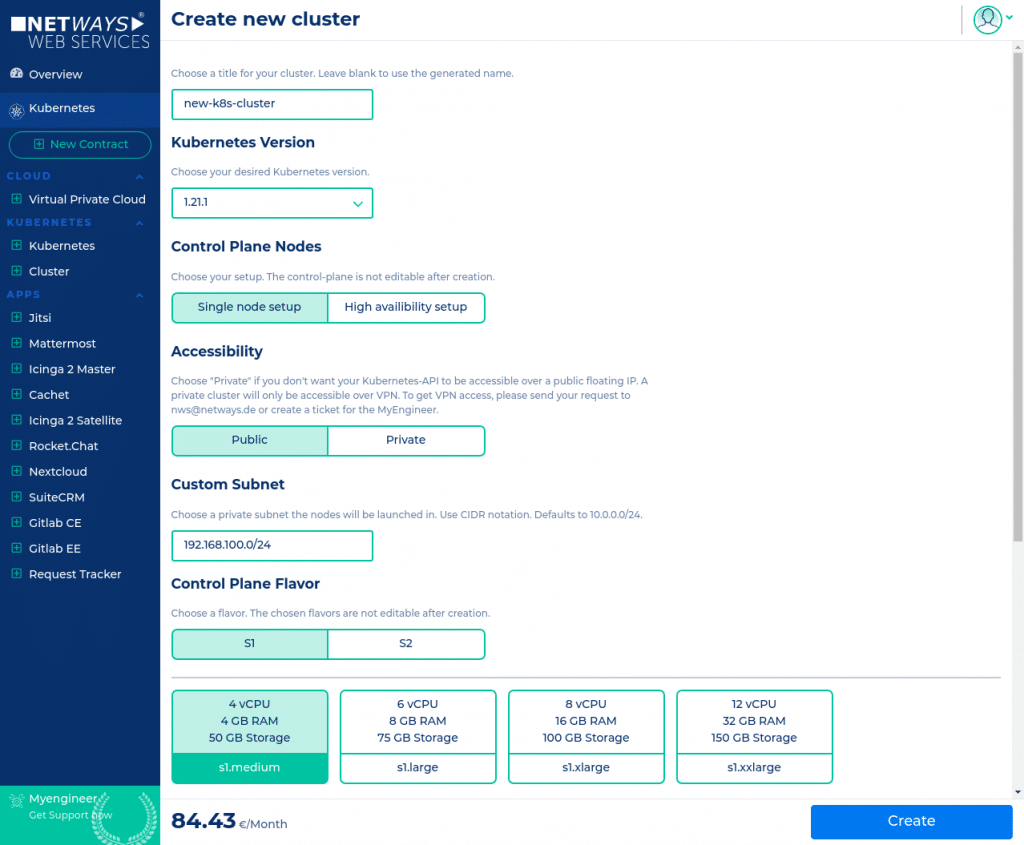
 Die Idee
Die Idee

















