Auf unserer Produktseite für Graphite werden ja schon einige alternative Webinterfaces für Graphite genannt. Heute möchte ich unser Portfolio erweitern und gleichzeitig meinen Favoriten vorstellen. Mit Grafana besteht ein Webinterface das nicht nur Daten aus Graphite darstellen kann, sondern auch aus InfluxDB oder Elasticsearch. Die GUI ähnelt nicht nur im Namen dem Logstash Webinterface Kibana, auch die Visualisierung und Bedienung ist vergleichbar. Wie bei Kibana, liefert Grafana lediglich Javascript Code aus. Es macht sich die API von Graphite zunutze um Datenpunkte anzuziehen, die ganze „Arbeit“ passiert also im Browser vom User. Zur Darstellung der Daten wird die JavaScript Library Flot für jQuery verwendet, womit die Graphen deutlich besser als im nativen Graphite-Web dargestellt werden.
Zur Darstellung verwendet Grafana Dashboards. Ein Dashboard besteht in der Regel aus mehreren Panels die Daten aus Graphite oder InfluxDB anzeigen. Für die langfristige Nutzung können Dashboards in einem eigenen Elasticsearch Index gespeichert und mit Tags versehen werden, um das wiederfinden zu vereinfachen. Temporäre Dashboards können mit einem generierten Link an Dritte versendet werden. Mit der Playlist Funktion werden mehrere Dashboards nacheinander in einem festgelegten Intervall im Fullscreen Mode abgespielt. Dieses Feature zielt auf die Darstellung auf eigenen Monitoren oder Fernsehern ab.
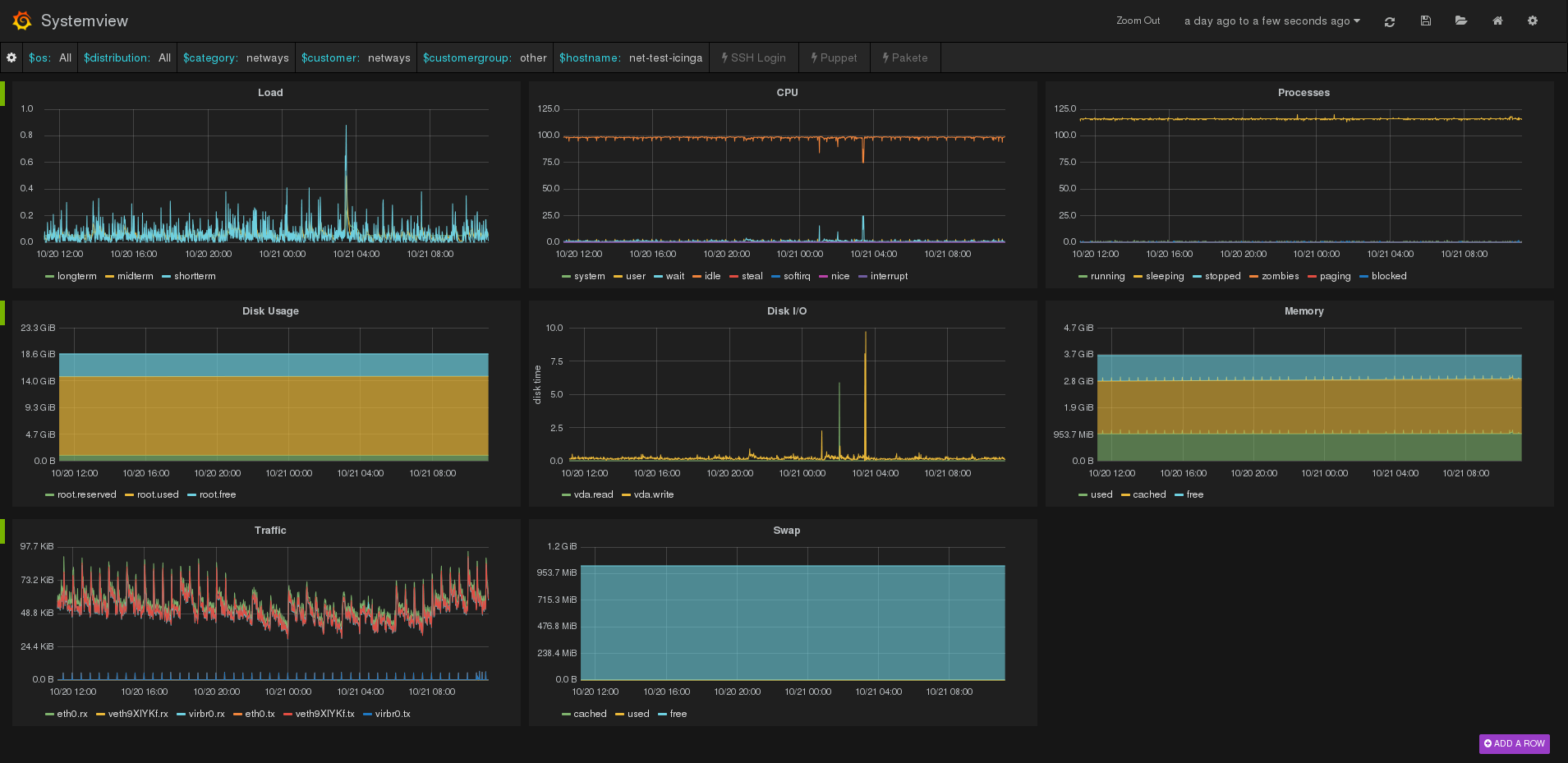
Grafana Systemview
Templates
Grafana Templates
Mit der Template Funktion nutzt Grafana die Möglichkeit von Graphite, Regex im Metrikpfad anzugeben, auf besondere Art und Weise. Man kann einen Pfad angeben, dessen Ende beispielsweise durch ein Wildcard variabel gehalten wird. Grafana stellt dann alle Möglichkeiten in einem Dropdown zur Auswahl dar. Der Metrikpfad lässt sich dann variable aus verschiedenen Teilen zusammenklicken. Damit gehört das wiederholte hangeln durch die gesamte Verzeichnisstruktur entgültig der Vergangenheit an. Für einzelne Variablen lassen sich auch Wildcards einsetzen, wodurch die Darstellung von gruppierten Graphen möglich wird.
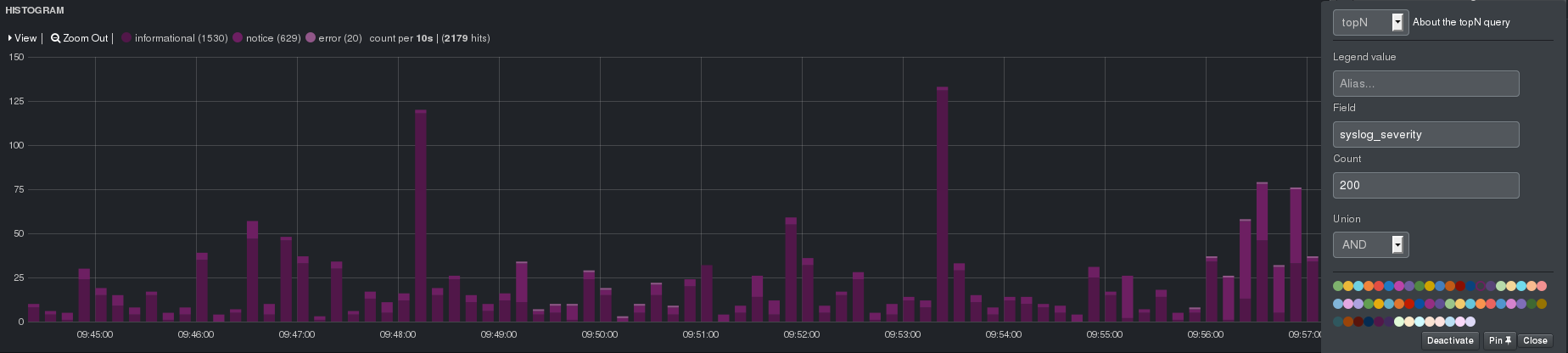
Annotations
Mit dieser Funktion lassen sich Ergebnisse aus Abfragen an Elasticsearch anzeigen. Zum Beispiel können das beliebige Logs sein die von Logstash verarbeitet und dort gespeichert wurden. Die Queries die für eine Annotation festgelegt werden, können auch die oben genannten Varibalen aus dem Template Feature beinhalten.
Mit folgendem Beispiel werden alle SSH Logins für den Ausgewählten Host angezeigt:
hostname:"[[hostname]]" AND program:sshd AND message:"session opened"
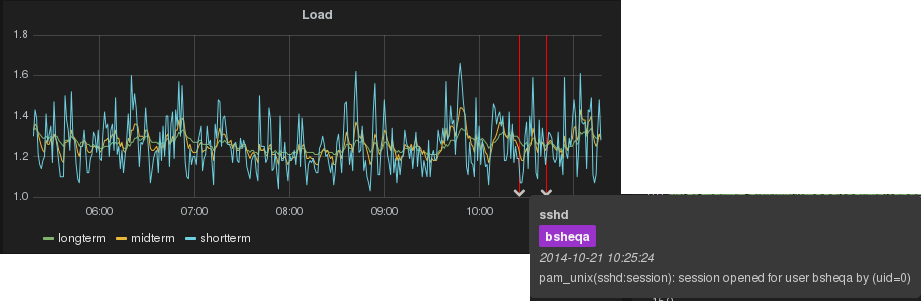
Grafana Annotations

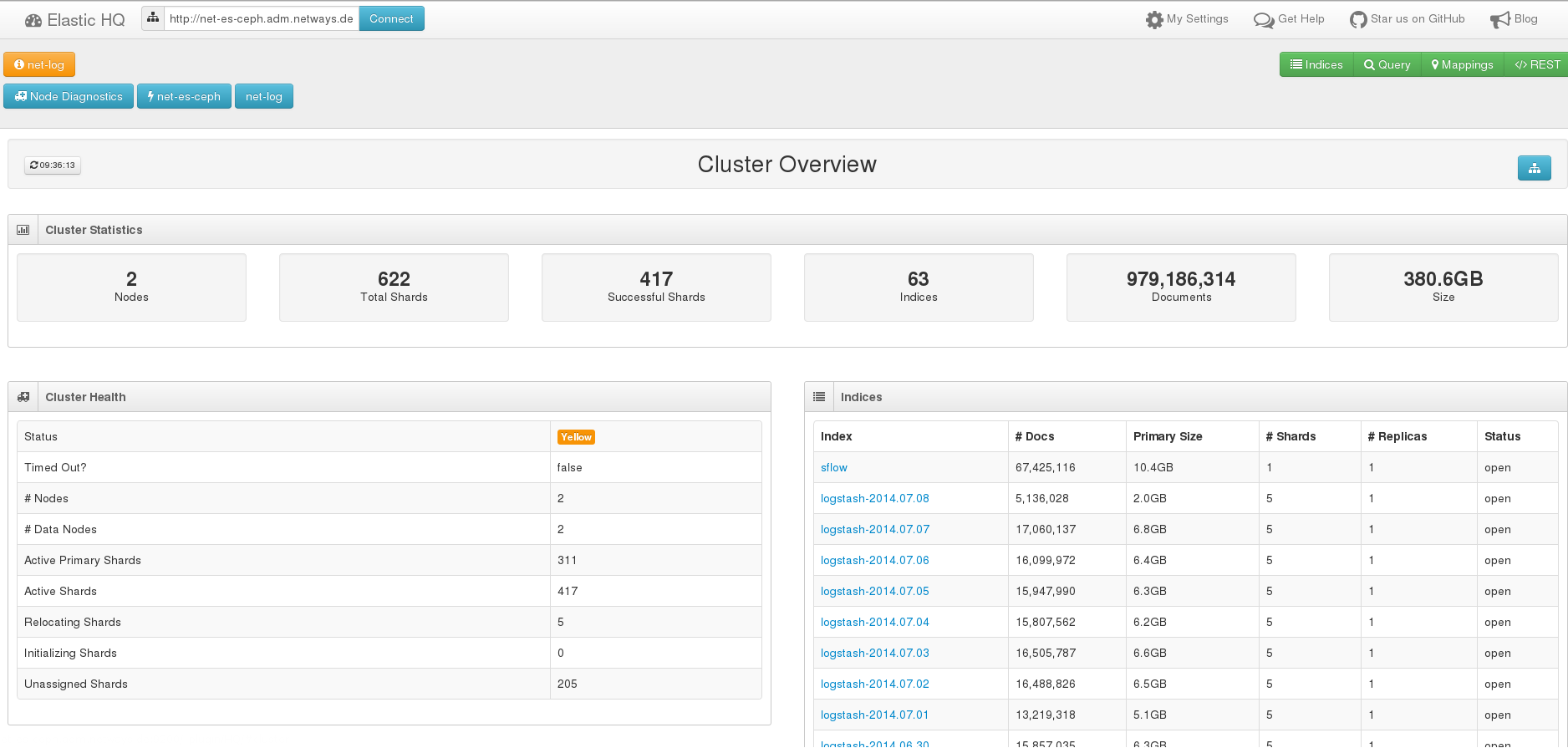

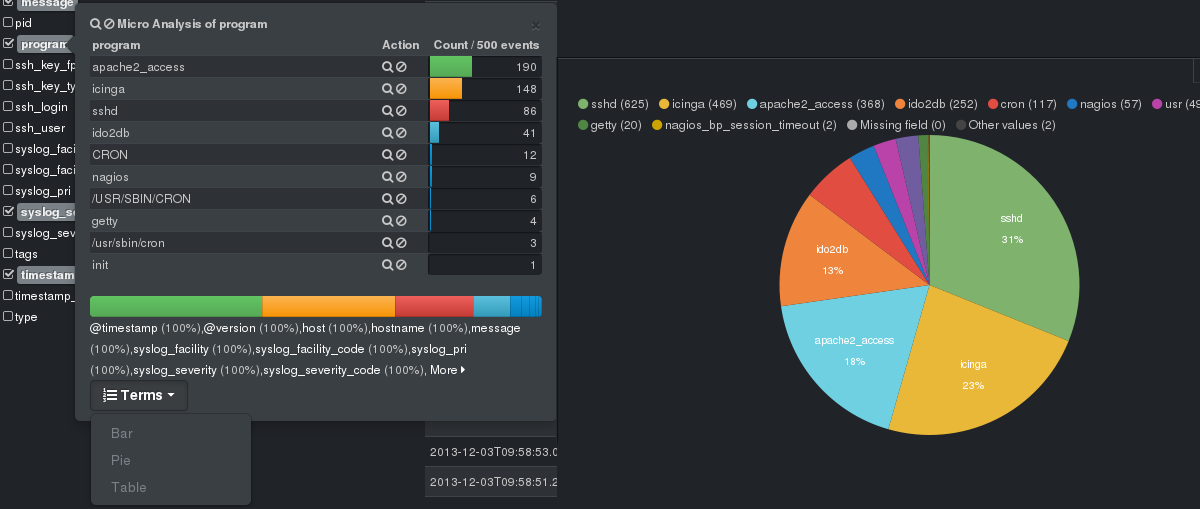
 Je mehr Daten man sammelt, umso aufwändiger wird auch das Indexieren. Eine gute Möglichkeit das Problem anzugehen ist das Open Source Projekt
Je mehr Daten man sammelt, umso aufwändiger wird auch das Indexieren. Eine gute Möglichkeit das Problem anzugehen ist das Open Source Projekt 
















