Graphite ist eine der beiden häufig genutzten Lösungen zum Erstellen von Graphen durch (nicht nur) Icinga 2. Im Gegensatz zu PNP4Nagios, das zusätzliche Software braucht, bringt Graphite mit dem Carbon Cache schon von Haus aus eine Lösung mit, die Daten zwischenspeichern kann, bevor sie auf Platte geschrieben werden. Während eine einzelne Graphite Installation so etliche Datenpunkte in kurzer Zeit “verdauen” kann, so stösst auch Graphite irgendwann an seine Grenzen.
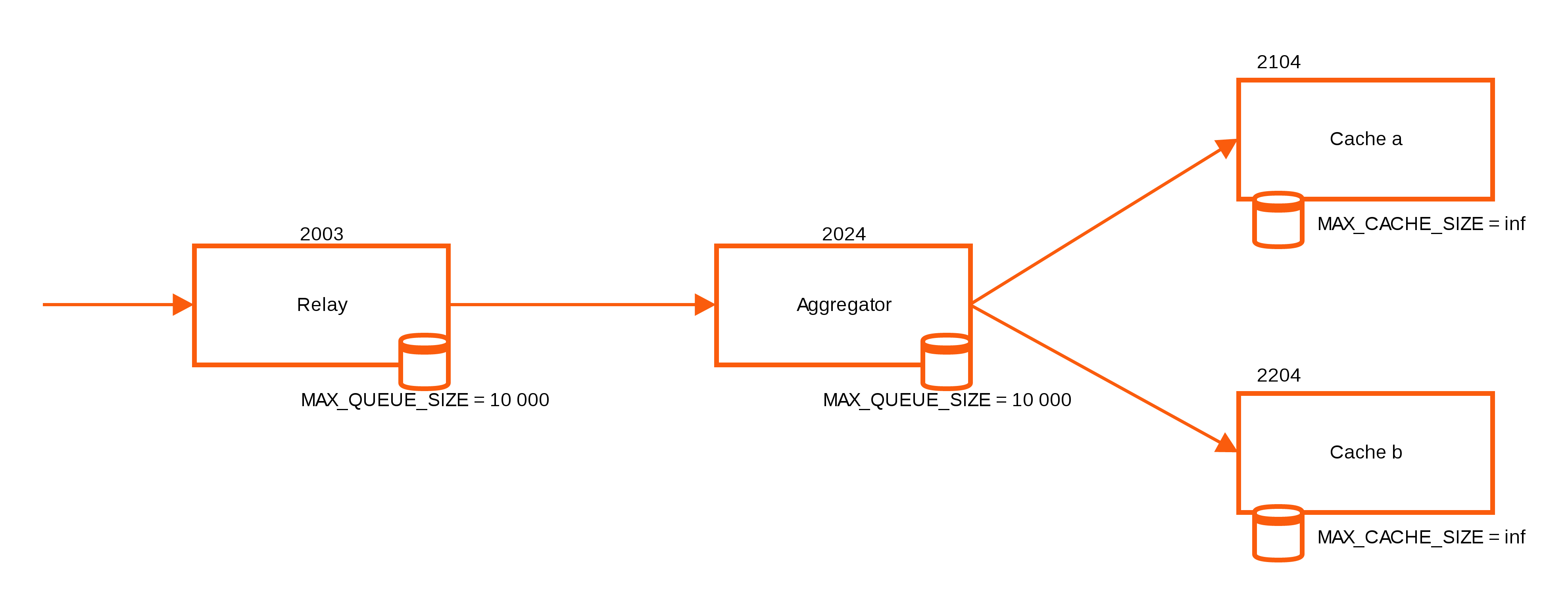
Eine Lösung, die sich bei einig en Setups bewährt hat, ist ein Carbon Relay. Eigentlich dafür gedacht, Daten auf mehrere Carbon Cache Instanzen aufzuteilen, bietet ein solches Relay auch die Möglichkeit, eine weitere Pufferinstanz einzuführen und so noch besser Lastspitzen abzufangen. Sollte das Relay nicht als Pufferinstanz ausreichen, ist damit schon die Grundlage gelegt, Graphite in der Breite zu skalieren.
en Setups bewährt hat, ist ein Carbon Relay. Eigentlich dafür gedacht, Daten auf mehrere Carbon Cache Instanzen aufzuteilen, bietet ein solches Relay auch die Möglichkeit, eine weitere Pufferinstanz einzuführen und so noch besser Lastspitzen abzufangen. Sollte das Relay nicht als Pufferinstanz ausreichen, ist damit schon die Grundlage gelegt, Graphite in der Breite zu skalieren.
Zur Auswahl stehen zwei Implementierungen des Carbon Relay, wobei der neuere, Carbon Relay NG genannte, Rewrite in “Go” bisher deutlich bessere Ergebnisse gebracht hat. Zur Installation werden Pakete angeboten, die auch über Repositories zu beziehen sind. Leider stehen keine einfachen Repo-Files, die die Repositories in den Package Manager konfigurieren, zur Verfügung. Statt dessen wird man gezwungen, ein Script auszuführen, das erst Abhängigkeiten installiert und dann ein passendes Repofile zusammenbaut und ablegt. Da ich nicht gern einfach irgendwelche Scripts auf meinen Hosts laufen lassen, habe ich die Anleitung auf einer Wegwerf-VM befolgt, die Schritte auf den eigentlichen Hosts nachempfunden und das Repofile kopiert. Danach reicht auf CentOS 7 ein yum install carbon-relay-ng um das Relay zu installieren.
Leider scheint das Paket noch nicht ausreichend für CentOS 7 angepasst zu sein, weshalb ein paar Nacharbeiten nötig sind: Die beiden Verzeichnisse /var/spool/carbon-relay-ng und /var/run/carbon-relay-ng müssen angelegt werden. Ausserdem braucht die Konfigurationsdatei /etc/carbon-relay-ng/carbon-relay-ng.conf noch ein paar kleinere Anpassungen. Sehr wichtig dabei ist, zwei Leerzeichen in der addRoute Zeile vor dem Empfänger zu verwenden.
instance = "default"
max_procs = 2
listen_addr = "0.0.0.0:2003"
pickle_addr = "0.0.0.0:2013"
admin_addr = "0.0.0.0:2004"
http_addr = "0.0.0.0:8081"
spool_dir = "/var/spool/carbon-relay-ng"
pid_file = "/var/run/carbon-relay-ng.pid"
log_level = "notice"
bad_metrics_max_age = "24h"
validation_level_legacy = "medium"
validation_level_m20 = "medium"
validate_order = false
init = [
'addRoute sendAllMatch carbon-default 192.168.5.20:2003 spool=true pickle=false',
]
[instrumentation]
graphite_addr = "localhost:2003"
graphite_interval = 1000 # in ms
Dabei ist natürlich 192.168.5.20 durch die IP der Carbon Cache Instanz zu ersetzen.
Leider ist die Dokumentation des carbon-relay-ng aktuell noch etwas dürftig, weshalb einiges an Probiererei gefragt ist, wenn man die Funktionen ausreizen möchte. Zum Probieren und Testen habe ich Vagrant Boxen gebaut, die aktuell nicht viel mehr sind als Prototypen. Wer Erfahrung mit Vagrant und Puppet hat, kann die aber ganz gut als Ausgangsposition nehmen. Wenn sie mal ein bissl ausgereifter sind, wandern die auch aus meinem privaten Github Account in einen “offizielleren”.
Ein grosser Vorteil des Carbon Relay NG ist, dass es nicht nur puffern, sondern die Daten auch sehr einfach auf mehrere Carbon Cache Instanzen verteilen kann. Dazu ändert man einfach den init Teil der Konfigurationsdatei auf folgende Version (auch hier wieder zwei Leerzeichen vor jedem Ziel):
init = [
'addRoute consistentHashing carbon-default 192.168.5.20:2003 spool=true pickle=false 192.168.5.30:2003 spool=true pickle=false',
]
Dabei wird der cosistentHashing Algorithmus von Graphite verwendet, der Metriken anhand ihres Namens auf verschiedene Instanzen verteilt. Somit kann man ganz einfach die Schreiblast auf beliebig viele Carbon Caches verteilen und stellt sicher, dass die Metriken immer am gleichen Cache ankommen. Am besten funktioniert das, wenn man die Verteilung konfiguriert, bevor zum ersten mal Daten in die Carbon Caches geschrieben werden. Sollte man eine bestehende Installation umziehen wollen, muss man alle bereits angelegten Whisper Files auf alle Carbon Caches verteilen. Also eigentlich nicht alle, da es aber nicht einfach nachvollziehbar ist, welche Metriken der Hashing-Algorithmus wo hin schreibt, ist es sicherer, alle zu kopieren und nach einiger Zeit mit find diejenigen zu suchen und zu löschen, in die schon länger nicht mehr geschrieben wurde. Das sollte man ohnehin regelmässig machen, da Whisper Files von Hosts und Services, die man in Icinga 2 umbenennt oder entfernt, liegen bleiben.
Hat man mehrere Carbon Cache Instanzen als Ziel konfiguriert, muss man sie auch für Graphite-Web nutzbar machen. Viele Addons wie Grafana nutzen die API von Graphite-Web, um auf die in Graphite gespeicherten Daten zuzugreifen, weshalb es naheliegend ist, sämtliche Datenquellen dort zu hinterlegen. Graphite-Web lässt in seiner Konfiguration mehrere Datenquellen zu, wobei 3 davon für uns relevant sind:
- lokale Whisper Files
- Andere Graphite-Web APIs
- Andere Carbon Caches (hier sollten nur die angegeben werden, die auf dem selben Host liegen, wie Graphite-Web, sonst lieber den Umweg über Lösung 2)
Da Graphite-Web üblicherweise so konfiguriert ist, dass es die lokalen Whisper Files verwendet, muss in local_settings.py nur mehr die zusätzliche Graphite Instanz auf dem hinzugekommenen Host konfiguriert werden. (Port 8003 ist hier aus den oben genannten Vagrant Boxen entnommen. Natürlich muss hier konfiguriert werden, wie das andere Graphite Web erreicht werden kann)
CLUSTER_SERVERS = ["192.168.5.30:8003"]
So erreicht man zwar keine Hochverfügbarkeit, aber das liesse sich relativ einfach erreichen, in dem man mehrere Graphite Webs anlegt, die jeweils ihre lokalen Whisper Files und die APIs aller anderen Instanzen konfiguriert haben. Davor einen Loadbalancer, fertig. Auf jeden Fall hat man auf diese Weise aber Carbon Cache in die Breite skaliert, was für grosse Installationen, die vielleicht nicht nur aus Icinga 2, sondern auch aus dem Elastic Stack und collectd Daten erhalten, einige Probleme lösen kann.
Wer jetzt Lust bekommen hat, mehr über Graphite zu erfahren, der sollte sich mal unser Schulungsangebot dazu ansehen.

 Der
Der