OpenSearch ist in seiner Vanilla Version schon sehr umfangreich. Doch erst mit den OpenSearch Plugins kannst du deine Experience personalisieren und das Maximum aus dem Elastic-Fork herausholen.
Eines vorab, bevor ich richtig ins Thema einsteige: die Geschwindigkeit, in der sich das Projekt aktuell weiterentwickelt ist extrem positiv. Deshalb kann man aktuell davon ausgehen, dass die Plugins beim Release des Blogposts noch mal besser geworden sind oder es noch mehr Regeln geben wird.
OpenSearch Plugins für Backend und Dashboards
Nun aber hinein ins Thema OpenSearch Plugins!
Hier muss direkt zwischen dem Backend „OpenSearch“ und den OpenSearch Dashboards unterschieden werden.
Das Backend kommt schon pre-Bundled mit einer Menge nützlicher Plugins. Diese vorinstallierten Plugins kannst du dir mit einem einfachen Befehl anzeigen lassen:
/usr/share/opensearch/bin/opensearch-plugin list opensearch-alerting opensearch-anomaly-detection opensearch-asynchronous-search opensearch-cross-cluster-replication opensearch-geospatial opensearch-index-management opensearch-job-scheduler opensearch-knn opensearch-ml opensearch-neural-search opensearch-notifications opensearch-notifications-core opensearch-observability opensearch-performance-analyzer opensearch-reports-scheduler opensearch-security opensearch-security-analytics opensearch-sql
Im Gegensatz dazu steht das Frontend OpenSearch Dashboards. Hier gibt es out-of-the-box keine Plugins und du kannst, darfst oder musst hier selbst Hand anlegen. Dadurch haben Anpassungen an deine individuellen Bedürfnisse jedoch nur die Grenze der Software.
Auch wenn du alle Plugins selbst installieren musst, ist dort so schnell viel in Bewegung gekommen, dass es leicht geworden ist, Plugins zu installieren. Und das Ganze ohne sich um Versionen / Git-Repositories kümmern zu müssen.
WICHTIGER HINWEIS: Es wird NICHT empfohlen, nachfolgende Skripte als Root auszuführen. Der Vollständigkeit halber habe ich die Flagge als Kommentar auskommentiert im Skript stehen lassen, solltest du das doch tun wollen.
Zum Installieren von Plugins habe ich mir folgendes „./deploy-plugins.sh„-Skript gebaut, das einfach mit dem Pfad der Binärdatei eine Installation über die Namen der Plugins macht:
#!/bin/bash
PLUGINS=(
alertingDashboards
anomalyDetectionDashboards
customImportMapDashboards
ganttChartDashboards
indexManagementDashboards
mlCommonsDashboards
notificationsDashboards
observabilityDashboards
queryWorkbenchDashboards
reportsDashboards
searchRelevanceDashboards
securityAnalyticsDashboards
securityDashboards
)
for PLUGIN in "${PLUGINS[@]}"
do
/usr/share/opensearch-dashboards/bin/opensearch-dashboards-plugin install $PLUGIN # --allow-root
done
Mit diesem kleinen, von mir geschriebenen Skript ist es schnell und unkompliziert möglich, mehrere OpenSearch Dashboard Plugins gleichzeitig zu installieren.
Da man Plugins in den meisten Fällen nicht nur installieren, sondern auch einmal entfernen will, habe ich dazu ebenfalls ein kleines Skript geschrieben. Es hört auf den Namen „./remove-plugins.sh„:
#!/bin/bash
PLUGINS=(
alertingDashboards
anomalyDetectionDashboards
customImportMapDashboards
ganttChartDashboards
indexManagementDashboards
mlCommonsDashboards
notificationsDashboards
observabilityDashboards
queryWorkbenchDashboards
reportsDashboards
searchRelevanceDashboards
securityAnalyticsDashboards
securityDashboards
)
for PLUGIN in "${PLUGINS[@]}"
do
/usr/share/opensearch-dashboards/bin/opensearch-dashboards-plugin remove $PLUGIN # --allow-root
done
systemctl restart opensearch && systemctl restart opensearch-dashboards
Mit dem letzten Befehl startest du OpenSearch und OpenSearch Dashboards neu. Nur so können wir sichergehen, dass die Installation oder Deinstallation von Plugins auch angenommen wird.
OpenSearch Dashboards: Plugin Überblick
Wenn du mein Skript verwendet hast, um Plugins für das Dashboard zu installieren, solltest du jetzt eine größere Seiten-Leiste haben als zuvor. Denn irgendwie musst du ja auch auf die Plugins zugreifen.
Damit du weißt, welche OpenSearch Plugins ich in meinem Skript verwende, folgt hier nun für jedes Plugin eine kurze Beschreibung sowie ein Screenshot, um dir die visuelle Darstellung vorzustellen.
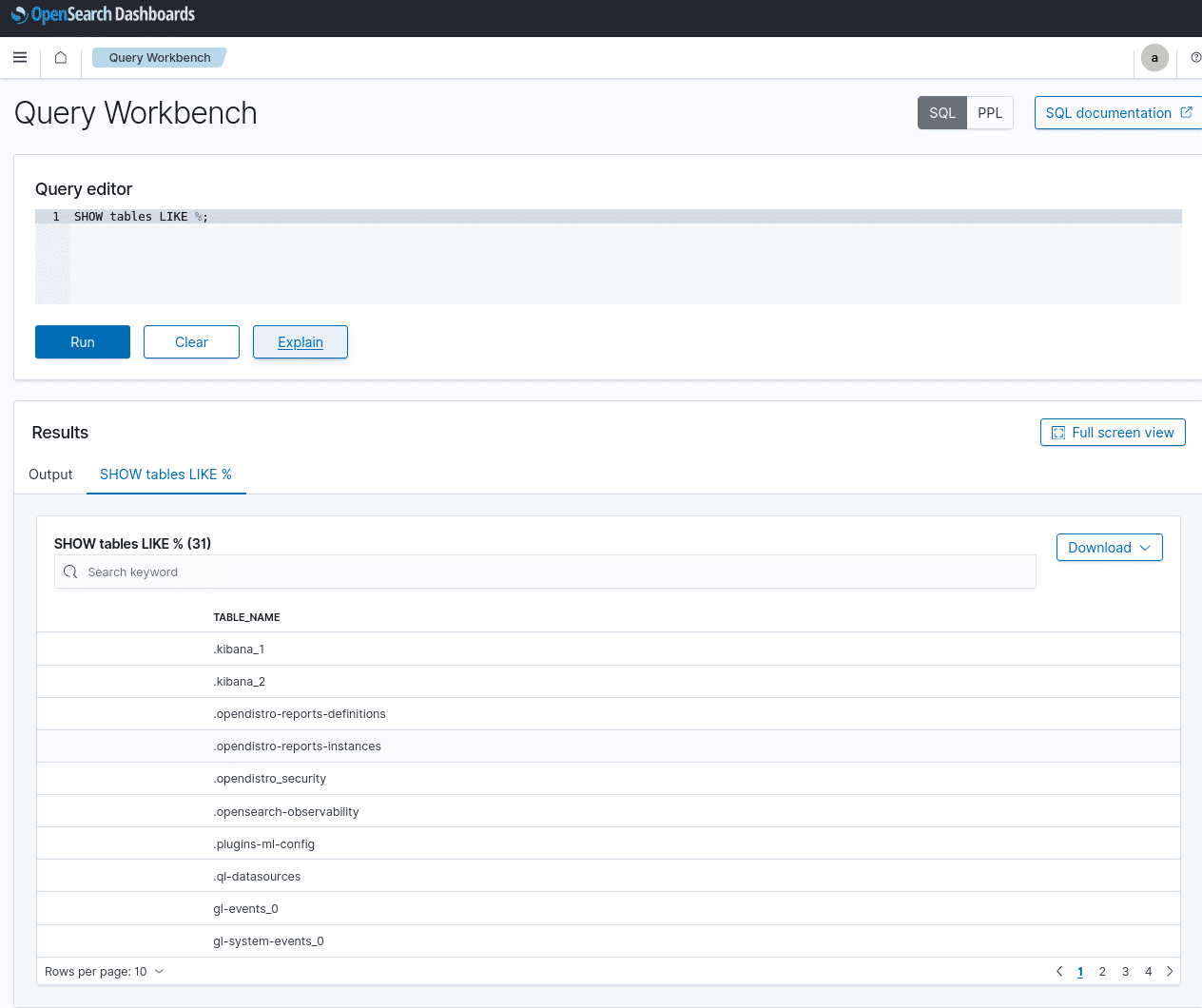
Query Workbench:
Mit diesem Plugin kannst du in SQL und PPL Abfragen machen. Interessant finde ich vor allem die Explain-Funktion, die die Darstellung im JSON-Format zurückgibt.
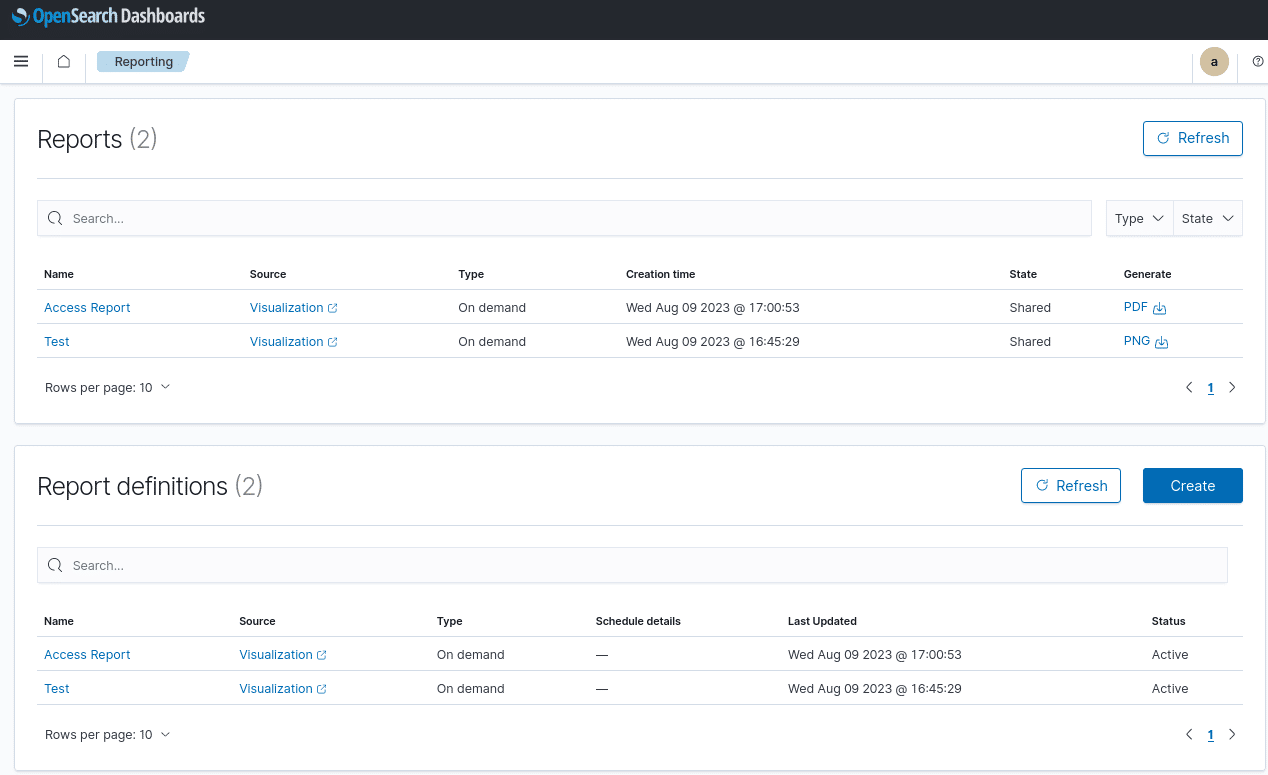
Reporting:
Mit Reporting lassen sich bequem alle relevanten Daten, zum Beispiel deine individuell angelegten Dashboards, aber auch viele weitere Daten exportieren. Der Export kann natürlich auch mit Schedulern automatisiert werden.
Ich kann mir vorstellen, das exportiere Reportings in den Formaten PDF und PNG in vielen Business-Umgebungen eine sinnvolle Erweiterung darstellen.
Alerting:
Hiermit kannst du für alle Parameter, die du überwachst, etwa Anomalien in deinen Datensätzen, Schwellwerte setzen und Aktionen auslösen lassen. Stark sind hier die vielen Möglichkeiten, die geboten werden. Du kannst dich zum Beispiel benachrichtigen lassen, wenn ein „whoami“ eingegeben wird oder ein Icinga2–Host ausfällt! Die Grenzen sind sehr weit gefasst, dass sicher auch für deinen Use Case das passende Alerting einstellbar ist.
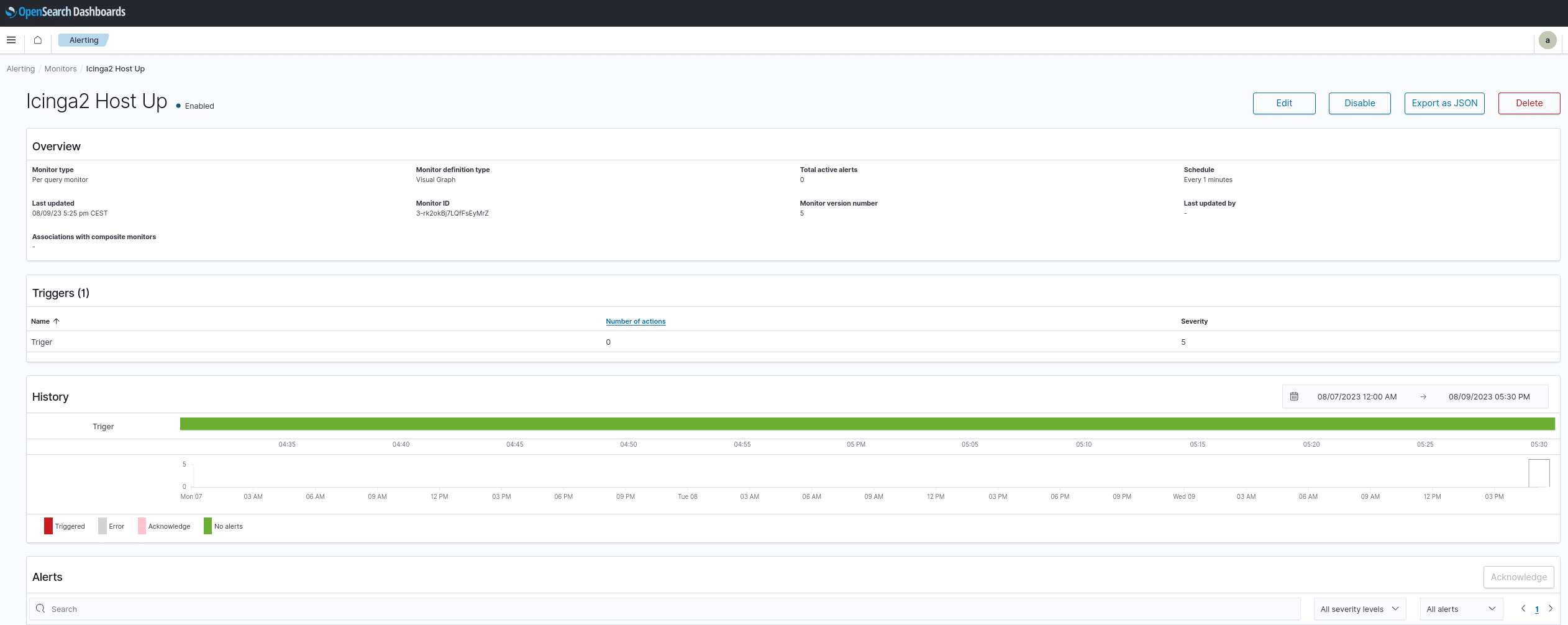
Stark sind vor allem mitgelieferten Notification Channels und das freundliche UI!
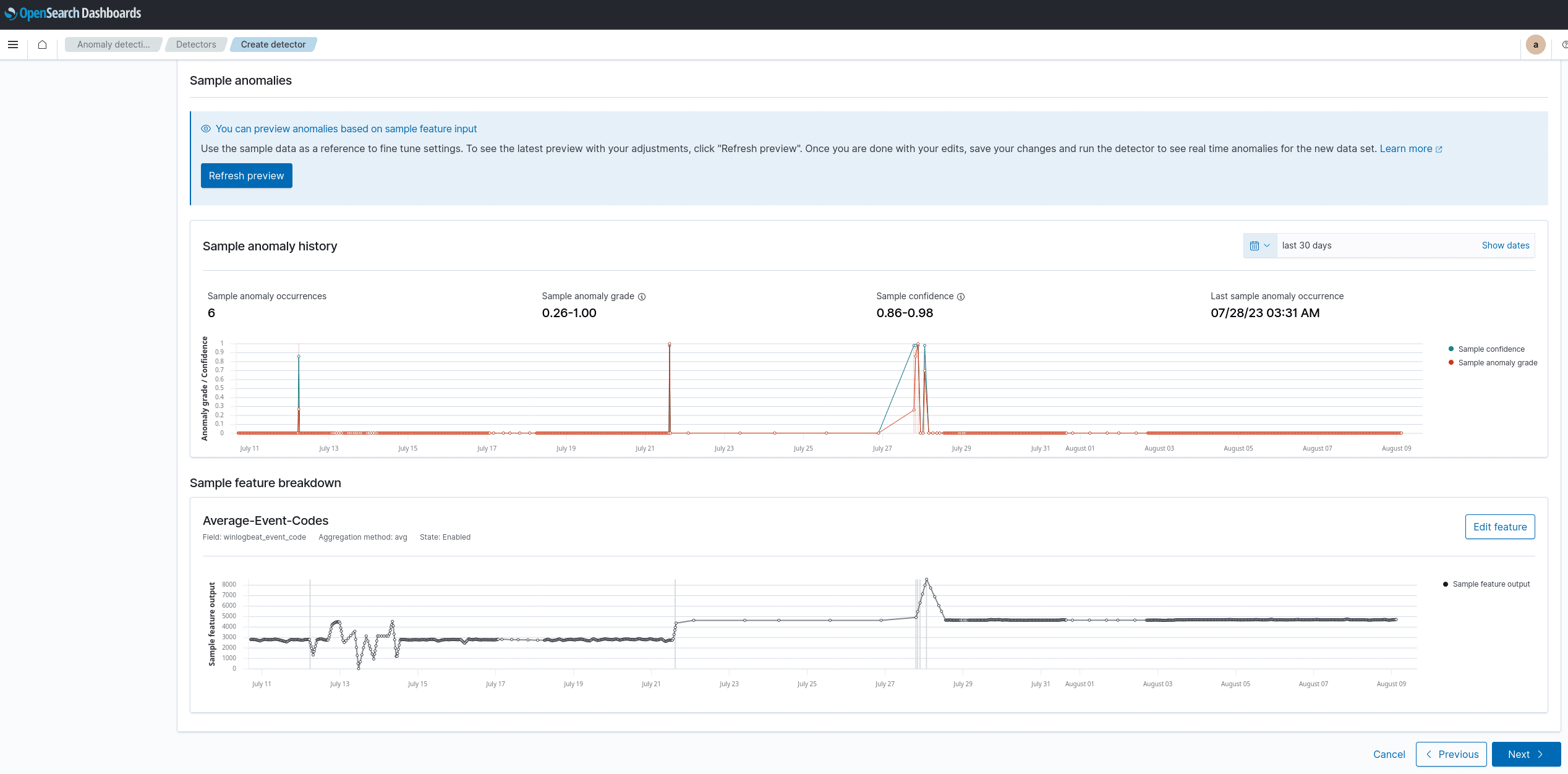
Anomaly Detection:
Hier wird der Nutzer mit mehr Neugier, Statistikwissen und tieferer Kenntnis seiner Daten (sowie, deren Felder) besseren Nutzen rausholen können.
In meinem Screenshot siehst du ein kleines Beispiel der Anomalien der Event Codes eines Active Directories der letzten 30 Tage. Solche Möglichkeiten sind natürlich genial für alle Admins, Data Scientists oder Analysten die projizieren und erkennen wollen:
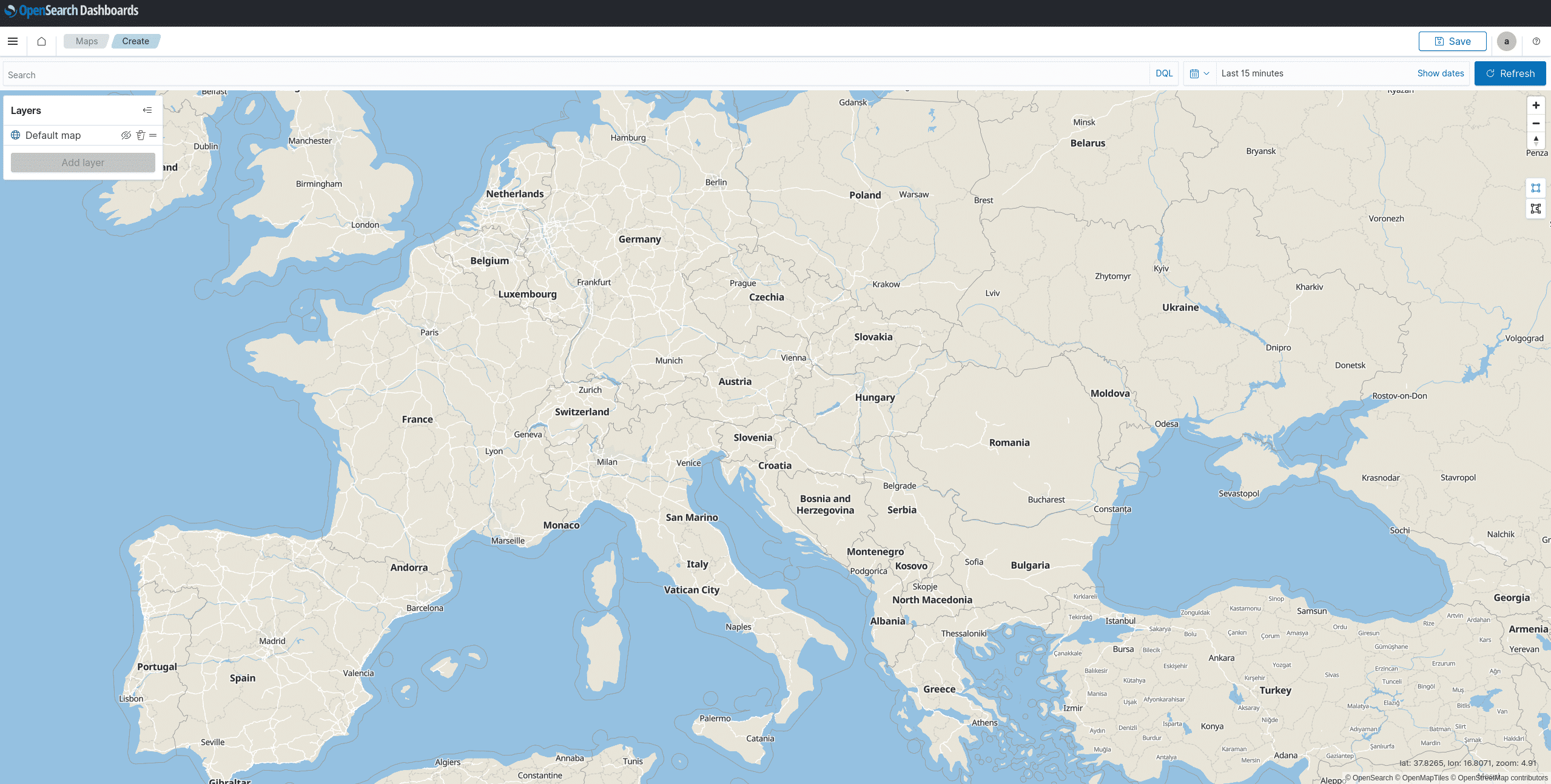
Maps:
Richtig spannend wird es, wenn dir Geodaten zur Verfügung stehen. Im OpenSearch Dashboards Plugin Maps kannst du dann aus mehreren visuellen Layern auswählen. Damit kann man schnell beeindrucken und mit den unterschiedlichen Layern sogar seine präferierte Ansicht wählen.
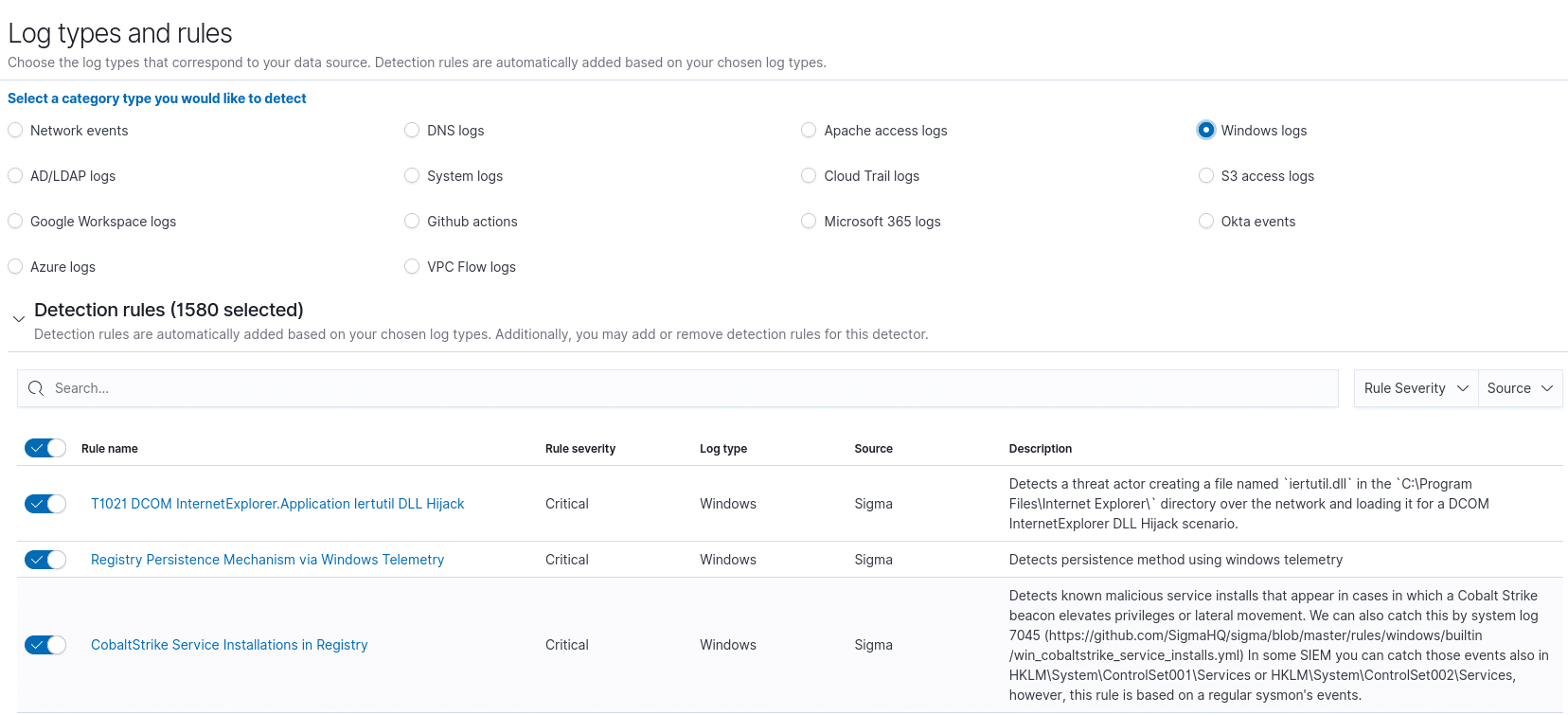
Security Analytics:
Vielleicht hast du mittlerweile auch ähnliche Gedankengänge wie ich zum Zeitpunkt, als ich OpenSearch getestet habe. Einer der prominentesten Gedanken bei mir war „Okay cool. Und das ist wirklich alles umsonst?“. Die einfache Antwort: Yes!
Aber als ich dann bei Security Analytics mit einem Klick einen Detector anlegen wollte, war ich dann einfach nur (positiv) schockiert. Hier sind massig Sigma Regeln eingebunden und das komplett umsonst!
Allein die Auswahl an Providern ist der Wahnsinn.
Fast 1600 Sigma-Regeln für Windows?! Wow!
Die Auswahl an Linux-Regeln ist auch stark und auch wenn es nicht viele sind, scheint man sich mit der Auswahl sehr viel Gedanken gemacht zu haben, um eine breite Trickkiste abzufangen:
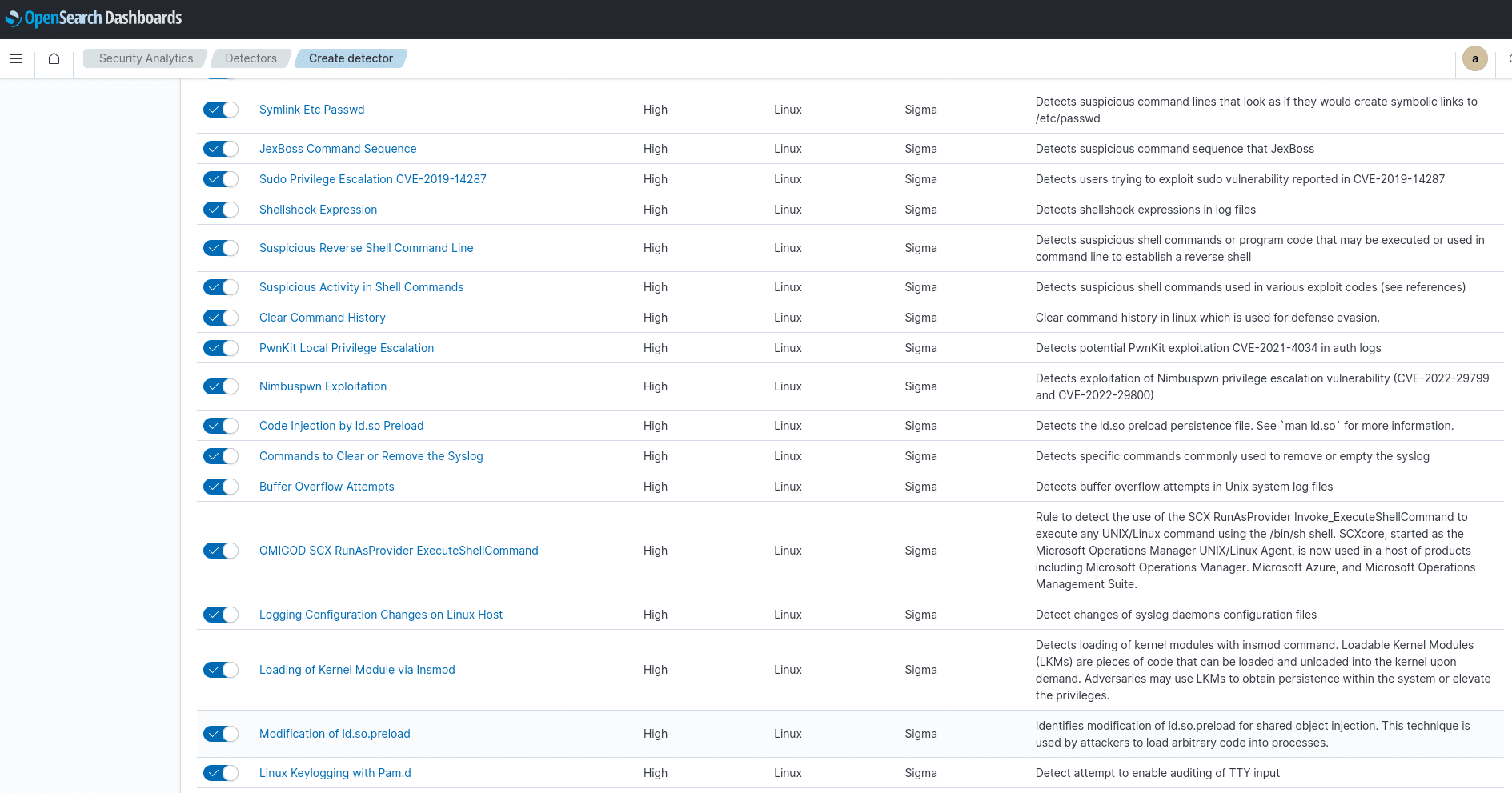
Also ist hier alles perfekt? Sehr gut, ja, aber nicht perfekt. Denn ein kleiner Haken im Vergleich zu Graylog und Elastic, die fertig eingerichtet kommen, ist, dass du die Detector-Regeln erst mal an die Felder der Indices anpassen musst. Dafür benötigst du schon einiges an Wissen und Zeit. Das heißt aber nicht, dass das so bleiben muss / wird!
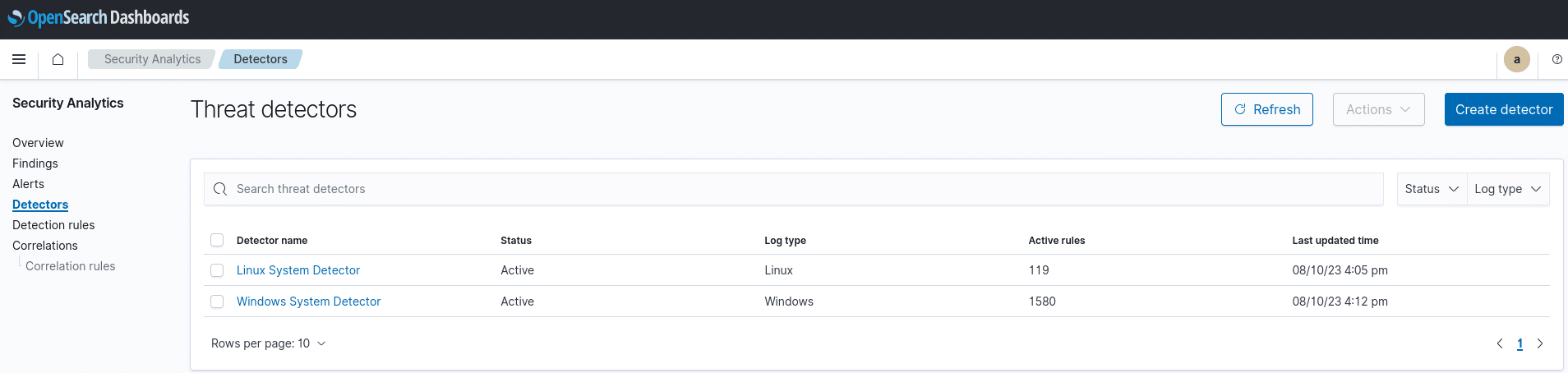
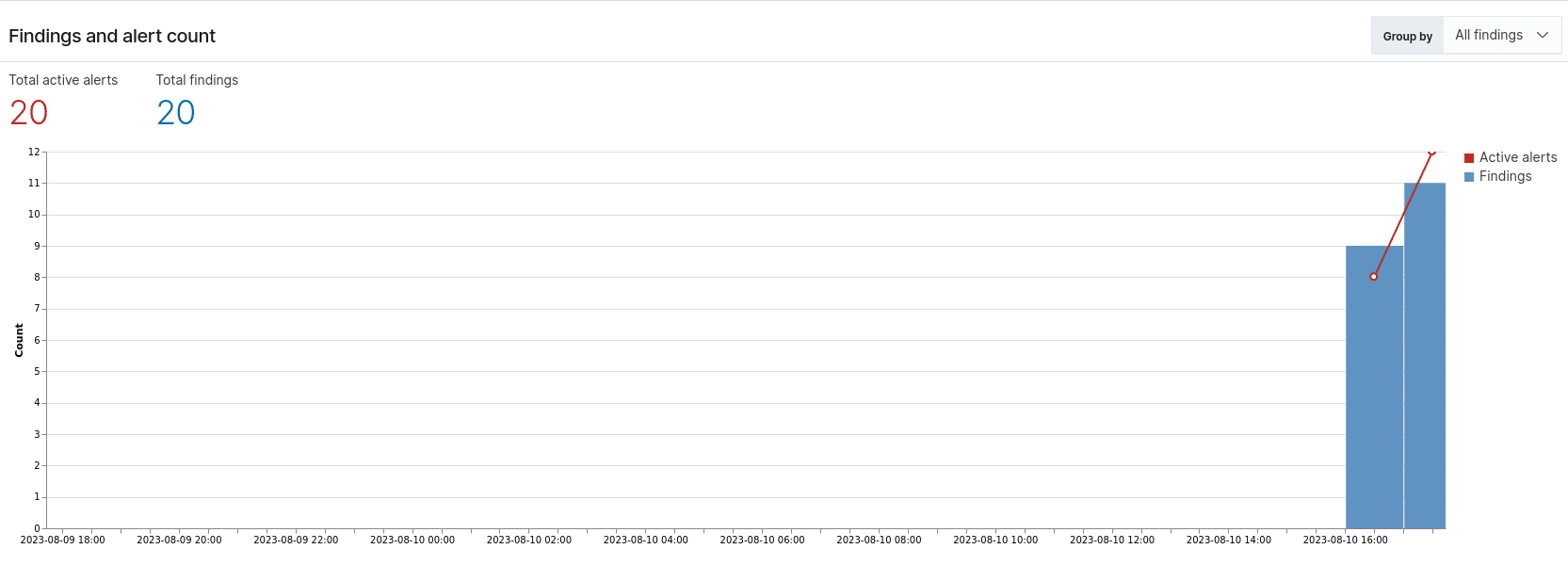
Kaum am Laufen und minimale Anpassungen später hatte ich direkt einen simulierten Treffer in einem Honeypot-AD von mir:
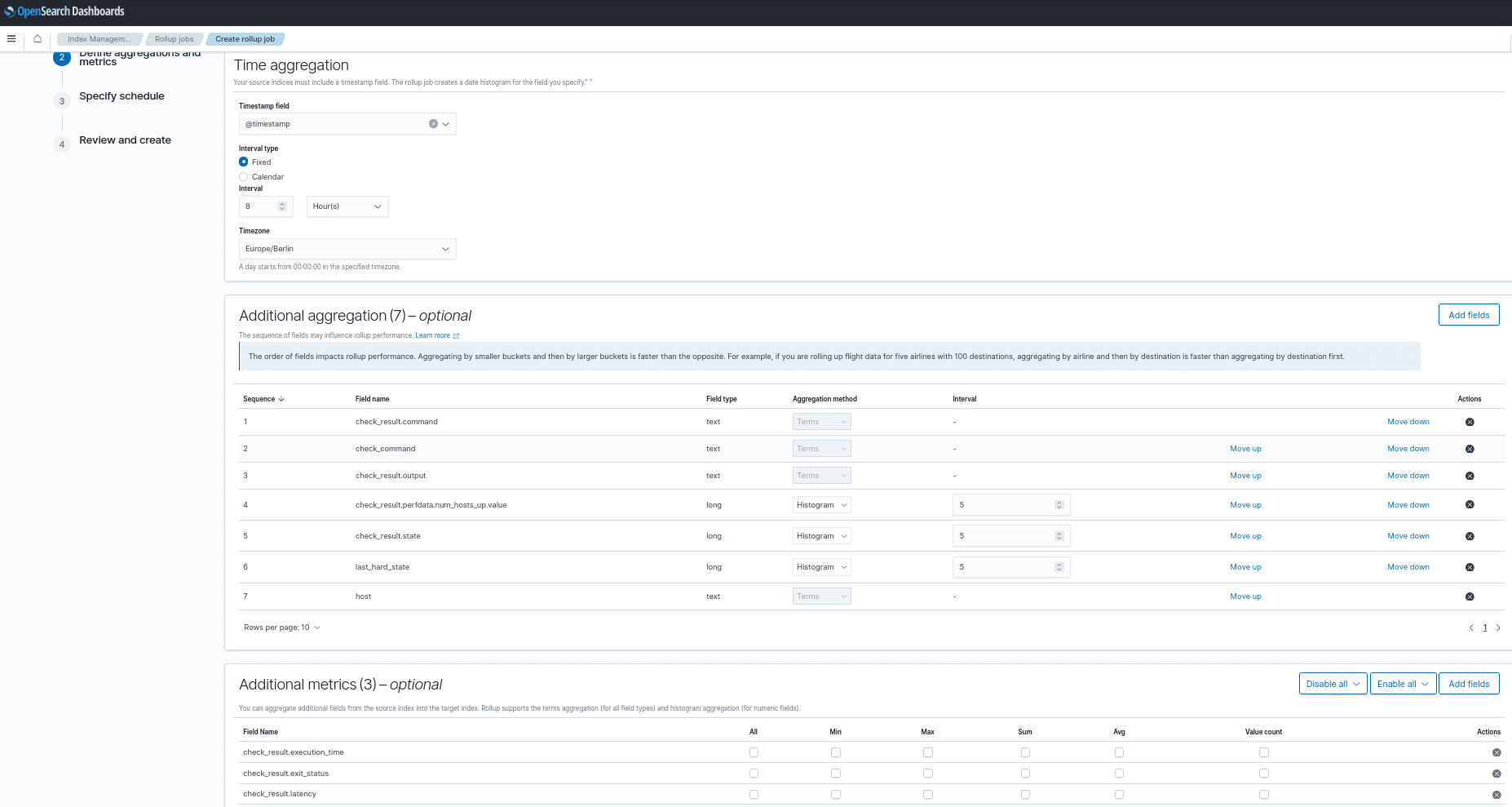
Index Management & Snapshot Management:
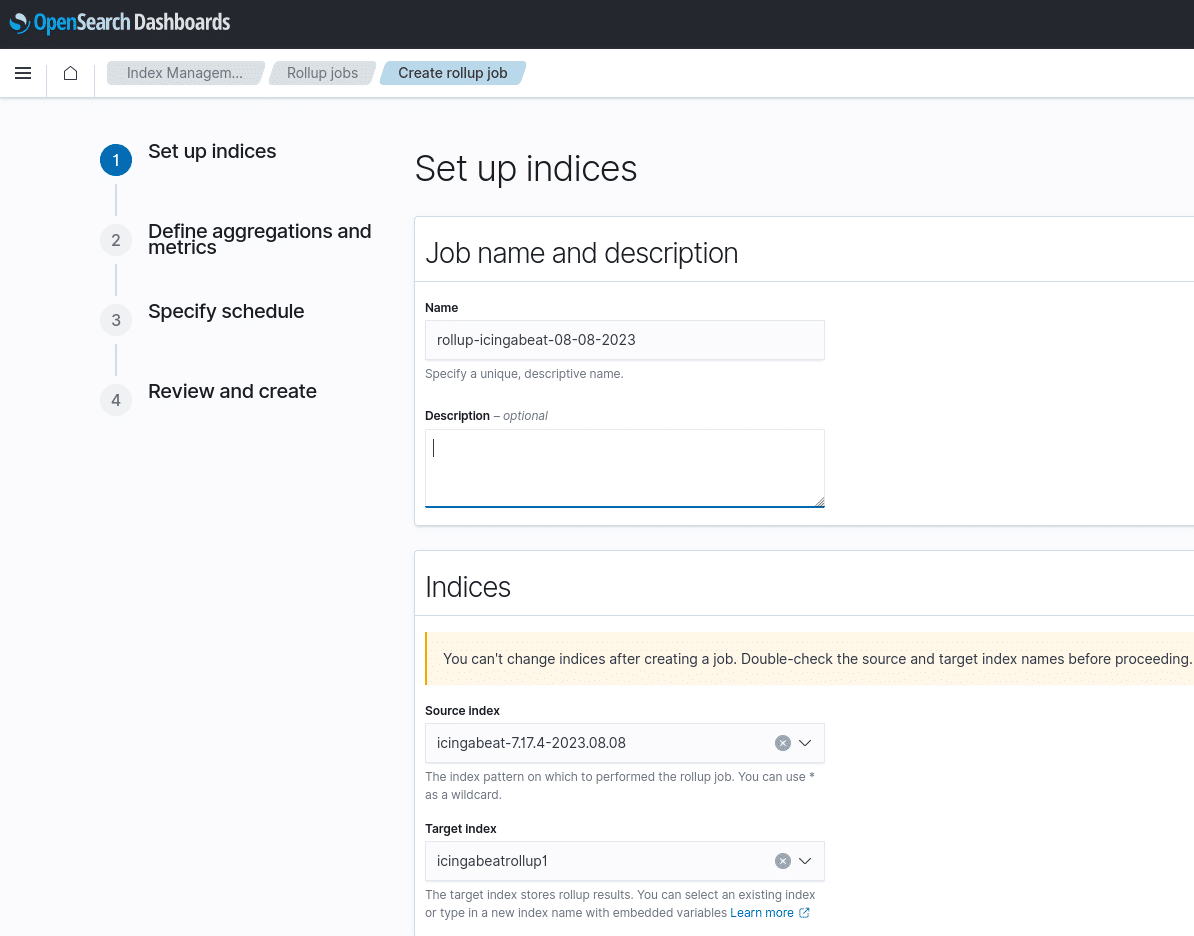
Snapshots sind für viele Admins und Entwickler wichtig. Ebenso wichtig sind Rollups mit denen man abbilden kann, wie lange die Daten der einzelnen Indizes verwahrt werden sollen.
In meinem Anwendungsbeispiel lege ich mir einfach einen neuen Index an und schiebe den alten dort hinein. Das Feld ist zusätzlich noch zeitgesteuert, womit man sehr viel Customization erhält:


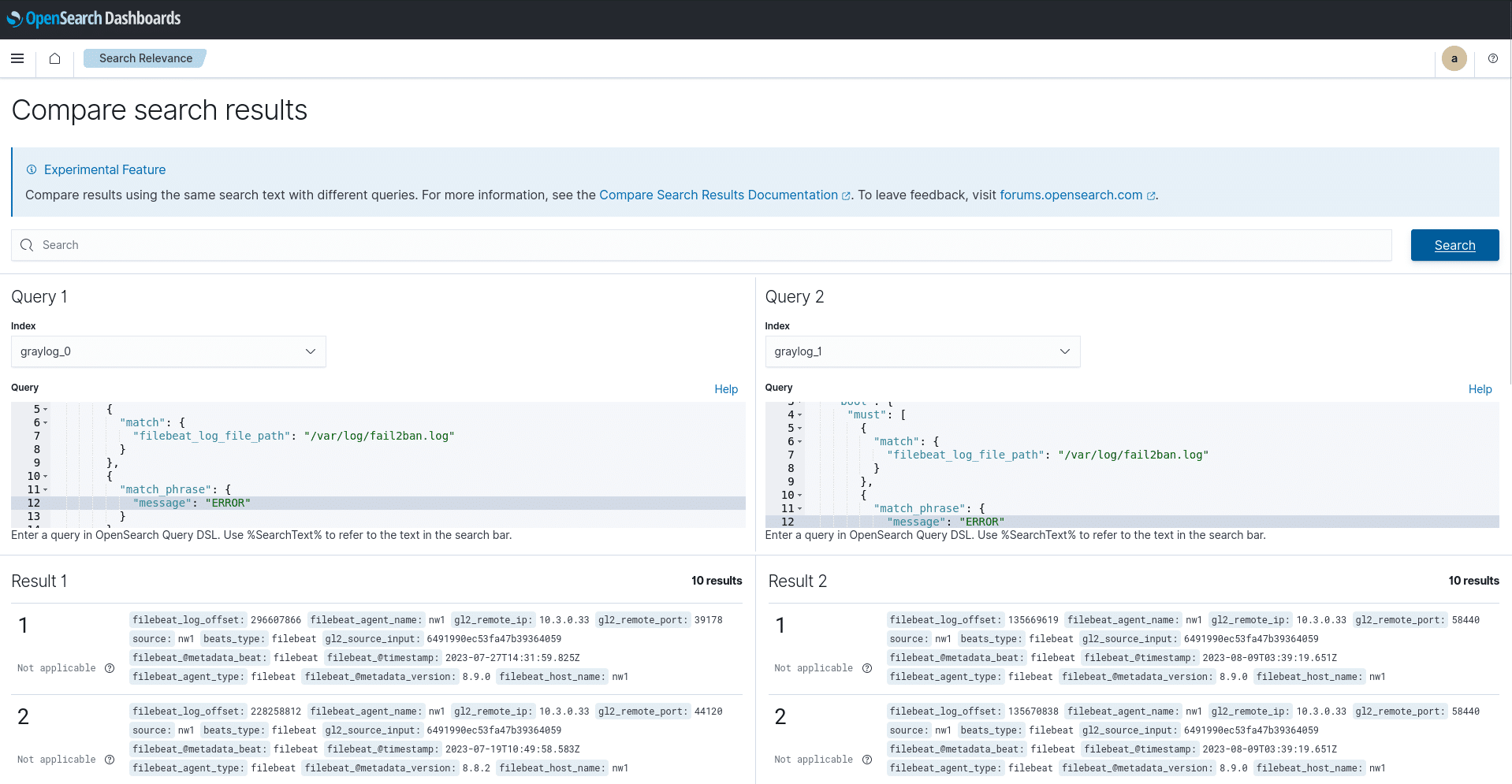
Search Relevance:
Mit diesem Plugins sich verschiedene Suchen vergleichen. Ziemlich hilfreich, um schnell Daten, etwas Felder aus verschiedenen Indizes miteinander zu vergleichen. Das setzt natürlich voraus, sich einmal mit der OpenSearch Query DSL auseinanderzusetzen.
Maschine Learning:
Um dieses Plugin einzusetzen, willst du genug Cluster haben, mit genug CPU & GPU Power. Dabei ist auch die Frage, wo du die Arbeit verrichten lassen willst, denn Logging braucht so schon genug Leistung und du brauchst auch extra Libraries.
Den Einsatz dieses OpenSearch Dashboard Plugins solltest du also etwas genauer planen. Auch Maschine Learning Modell-Deployments habe ich im Rahmen meiner OpenSearch Analyse genauer unter die Lupe genommen. Dieser Abschnitt würde jedoch den Rahmen dieses Blogbeitrags sprengen. Deshalb werde ich zum Thema OpenSearch Machine Learnung einen gesonderten Blogpost schreiben.
Ich hoffe, ich konnte dir mit diesem Blogpost ein paar Beispiele für die vielfältigen Plugins in OpenSearch zeigen und freue mich auf dein Feedback!




















