 In 6 Wochen ist es soweit: Die deutschen OpenStack Tage (DOST) in München gehen in die 3. Runde!
In 6 Wochen ist es soweit: Die deutschen OpenStack Tage (DOST) in München gehen in die 3. Runde!
Die Feinschliffarbeiten sind bereits in vollem Gange und das Programm steht selbstverständlich auch schon fest! Was wird euch alles erwarten?
Die Konferenz lockt jedes Jahr ca. 300 begeisterte OpenStack Sympathisanten an, die sich in zwei Tagen über die neuesten Neuigkeiten rund um den Enterprise-Einsatz von OpenStack informieren und die Gelegenheit wahrnehmen, sich wertvolle Tipps von Profis zu holen.
Das fertige Konferenzprogramm deckt ein breites Themenspektrum ab. Zum einen wird es Vorträge von Vertretern führender, internationaler Unternehmen geben, zum anderen gibt es etliche Fachvorträge von OpenStack Experten zu Case Studies und Best Practices. Am ersten Konferenztag wird es hierzu außerdem Workshops zu den Themen „Konfigurationsmanagement mit Puppet“, „Ceph Storage Cluster“, „Administration von OpenStack“ und „Docker – Die andere Art der Virtualisierung“ geben. Informationen zu den Vorträgen und Referenten findet ihr auf der Konferenzwebseite.
Ergänzend zu den Vorträgen besteht für alle die Möglichkeit, im Foyer des Veranstaltungshotels die Sponsorenausstellung zu besuchen. Hier können die Besucher direkt mit den Referenten und Sponsoren in Kontakt treten. Euch erwarten interessante Diskussionen, aktuellstes Know-How und tolle Networkingmöglichkeiten. Unterstützt werden die 3. Deutschen OpenStack Tage von Noris Network, Fujitsu, Rackspace, Mirantis, SUSE, Nokia, Canonical, Cumulus, Netzlink, Juniper, Telekom, Vmware, Mellanox, Cisco und NetApp.
An dieser Stelle möchten wir neben den Sponsoren außerdem unseren tollen Medienpartner danken, die auch einen großen Anteil am Erfolg der OpenStack Tage haben. Unsere hochlobenden Dankeshymnen gehen dieses Jahr raus an das deutsche Linux Magazin und den IT-Administrator. Wir haben die Zusammenarbeit mit euch jederzeit genossen und würden uns freuen, euch auch nächstes Jahr wieder mit an Bord zu haben.
NETWAYS Blog
Ceph – CRUSH rules über die CLI
![]() Über die CRUSH Map ist es möglich zu beinflussen wie Ceph seine Objekte repliziert und verteilt. Die Standard CRUSH Map verteilt die Daten, sodass jeweils nur eine Kopie per Host abgelegt wird.
Über die CRUSH Map ist es möglich zu beinflussen wie Ceph seine Objekte repliziert und verteilt. Die Standard CRUSH Map verteilt die Daten, sodass jeweils nur eine Kopie per Host abgelegt wird.
Wenn nun ein Ceph Cluster andere Prioritäten voraussieht, bspw. Hosts sich ein Netz, oder ein Rack mit gleicher Stromversorgung teilen, oder im gleichen Rechenzentrum stehen, sprich die Failure Domains anders aufgeteilt sind, ist es möglich diese Abhängigkeiten in der CRUSH Map zu berücksichtigen.
Beispielsweise wollen wir unseren Cluster mit einer Replikation von 3 auf eine 2er Replikation zurücksetzen. Da sich jedoch 2 Hosts einen Rack teilen, wollen wir das auch in unserer CRUSH Map abbilden und das über die CLI:
Ausgangslage:
[root@box12 ~]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -6 0.33110 datacenter dc03 -1 0.33110 root datacenter01 -5 0.33110 datacenter datacenter02 -4 0.11037 host box14 6 0.03679 osd.6 up 1.00000 1.00000 7 0.03679 osd.7 up 1.00000 1.00000 8 0.03679 osd.8 up 1.00000 1.00000 -3 0.11037 host box13 3 0.03679 osd.3 up 1.00000 1.00000 4 0.03679 osd.4 up 1.00000 1.00000 5 0.03679 osd.5 up 1.00000 1.00000 -2 0.11037 host box12 0 0.03679 osd.0 up 1.00000 1.00000 1 0.03679 osd.1 up 1.00000 1.00000 2 0.03679 osd.2 up 1.00000 1.00000
Wir erstellen die beiden Racks:
[root@box12 ~]# ceph osd crush add-bucket rack1 rack added bucket rack1 type rack to crush map [root@box12 ~]# ceph osd crush add-bucket rack2 rack added bucket rack2 type rack to crush map
Die Racks wurden erstellt:
[root@box12 ~]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -8 0 rack rack2 -7 0 rack rack1 -6 0.33110 datacenter dc03 -1 0.33110 root datacenter01 -5 0.33110 datacenter datacenter02 -4 0.11037 host box14 6 0.03679 osd.6 up 1.00000 1.00000 7 0.03679 osd.7 up 1.00000 1.00000 8 0.03679 osd.8 up 1.00000 1.00000 -3 0.11037 host box13 3 0.03679 osd.3 up 1.00000 1.00000 4 0.03679 osd.4 up 1.00000 1.00000 5 0.03679 osd.5 up 1.00000 1.00000 -2 0.11037 host box12 0 0.03679 osd.0 up 1.00000 1.00000 1 0.03679 osd.1 up 1.00000 1.00000 2 0.03679 osd.2 up 1.00000 1.00000
Nun verschieben wir die Hosts 14 & 13 nach Rack1 und 12 nach Rack2:
[root@box12 ~]# ceph osd crush move box14 rack=rack1
moved item id -4 name 'box14' to location {rack=rack1} in crush map
[root@box12 ~]# ceph osd crush move box13 rack=rack1
moved item id -3 name 'box13' to location {rack=rack1} in crush map
[root@box12 ~]# ceph osd crush move box12 rack=rack2
moved item id -2 name 'box12' to location {rack=rack2} in crush map
Und die Racks in das Rechenzentrum(datacenter02):
[root@box12 ~]# ceph osd crush move rack1 datacenter=datacenter02
moved item id -7 name 'rack1' to location {datacenter=datacenter02} in crush map
[root@box12 ~]# ceph osd crush move rack2 datacenter=datacenter02
moved item id -8 name 'rack2' to location {datacenter=datacenter02} in crush map
Das ganze sieht dann so aus:
[root@box12 ~]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -6 0.33110 datacenter dc03 -1 0.33110 root datacenter01 -5 0.33110 datacenter datacenter02 -7 0.22073 rack rack1 -4 0.11037 host box14 6 0.03679 osd.6 up 1.00000 1.00000 7 0.03679 osd.7 up 1.00000 1.00000 8 0.03679 osd.8 up 1.00000 1.00000 -3 0.11037 host box13 3 0.03679 osd.3 up 1.00000 1.00000 4 0.03679 osd.4 up 1.00000 1.00000 5 0.03679 osd.5 up 1.00000 1.00000 -8 0.11037 rack rack2 -2 0.11037 host box12 0 0.03679 osd.0 up 1.00000 1.00000 1 0.03679 osd.1 up 1.00000 1.00000 2 0.03679 osd.2 up 1.00000 1.00000
Im nächsten Schritt lassen wir uns automatisch eine CRUSH Rule erstellen und ausgeben:
[root@box12 ~]# ceph osd crush rule create-simple ceph-blog datacenter01 rack [root@box12 ~]# ceph osd crush rule ls [ "ceph-blog", "test03" ]
‚datacenter01 rack‘ sagt hier, dass beim datacenter01 begonnen werden soll und alle Kindknoten(leaf) vom Typ rack ausgewählt werden sollen.
Wir lassen uns die CRUSH Rule ausgeben:
[root@box12 ~]# ceph osd crush rule dump ceph-blog
{
"rule_id": 0,
"rule_name": "ceph-blog",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "datacenter01"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "rack"
},
{
"op": "emit"
}
]
}
Sieht gut aus.
Der Pool rbd soll die Rule anwenden:
[root@box12 ~]# ceph osd pool set rbd crush_ruleset 0 set pool 0 crush_ruleset to 0
Funktioniert’s?
[root@box12 ~]# ceph osd map rbd test osdmap e421 pool 'rbd' (0) object 'test' -> pg 0.40e8aab5 (0.b5) -> up ([4,0], p4) acting ([4,0,6], p4)
Das test Objekt wird weiterhin über die 3 Hosts verteilt.
Wir setzen die Replikation von 3 auf 2:
[root@box12 ~]# ceph osd pool get rbd size size: 3 [root@box12 ~]# ceph osd pool set rbd size 2 set pool 0 size to 2
Ceph verteilt die Objekte. Nur Geduld:
[root@box12 ~]# ceph -s
cluster e4d48d99-6a00-4697-b0c5-4e9b3123e5a3
health HEALTH_ERR
60 pgs are stuck inactive for more than 300 seconds
60 pgs peering
60 pgs stuck inactive
27 pgs stuck unclean
recovery 3/45 objects degraded (6.667%)
recovery 3/45 objects misplaced (6.667%)
monmap e4: 3 mons at {box12=192.168.33.22:6789/0,box13=192.168.33.23:6789/0,box14=192.168.33.24:6789/0}
election epoch 82, quorum 0,1,2 box12,box13,box14
osdmap e424: 9 osds: 9 up, 9 in
flags sortbitwise
pgmap v150494: 270 pgs, 1 pools, 10942 kB data, 21 objects
150 GB used, 189 GB / 339 GB avail
3/45 objects degraded (6.667%)
3/45 objects misplaced (6.667%)
183 active+clean
35 peering
27 active+remapped
25 remapped+peering
Nach ’ner Weile ist der Cluster wieder im OK Status:
[root@box12 ~]# ceph -s
cluster e4d48d99-6a00-4697-b0c5-4e9b3123e5a3
health HEALTH_OK
monmap e4: 3 mons at {box12=192.168.33.22:6789/0,box13=192.168.33.23:6789/0,box14=192.168.33.24:6789/0}
election epoch 82, quorum 0,1,2 box12,box13,box14
osdmap e424: 9 osds: 9 up, 9 in
flags sortbitwise
pgmap v150497: 270 pgs, 1 pools, 10942 kB data, 21 objects
149 GB used, 189 GB / 339 GB avail
270 active+clean
Gucken wir uns nochmal die Verteilung der Objekte an:
[root@box12 ~]# ceph osd map rbd test osdmap e424 pool 'rbd' (0) object 'test' -> pg 0.40e8aab5 (0.b5) -> up ([4,0], p4) acting ([4,0], p4)
Sieht besser aus.
Vielleicht nur ein Zufall. Wir stoppen OSD.0 auf box12. Die Daten sollten weiterhin jeweils zwischen beiden Racks repliziert werden:
[root@box12 ~]# systemctl stop ceph-osd@0 [root@box12 ~]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -6 0.33110 datacenter dc03 -1 0.33110 root datacenter01 -5 0.33110 datacenter datacenter02 -7 0.22073 rack rack1 -4 0.11037 host box14 6 0.03679 osd.6 up 1.00000 1.00000 7 0.03679 osd.7 up 1.00000 1.00000 8 0.03679 osd.8 up 1.00000 1.00000 -3 0.11037 host box13 3 0.03679 osd.3 up 1.00000 1.00000 4 0.03679 osd.4 up 1.00000 1.00000 5 0.03679 osd.5 up 1.00000 1.00000 -8 0.11037 rack rack2 -2 0.11037 host box12 0 0.03679 osd.0 down 0 1.00000 1 0.03679 osd.1 up 1.00000 1.00000 2 0.03679 osd.2 up 1.00000 1.00000
Der Cluster verteilt wieder neu… Nur Geduld:
[root@box12 ~]# ceph osd map rbd test
osdmap e426 pool 'rbd' (0) object 'test' -> pg 0.40e8aab5 (0.b5) -> up ([4], p4) acting ([4], p4)
[root@box12 ~]# ceph -s
cluster e4d48d99-6a00-4697-b0c5-4e9b3123e5a3
health HEALTH_WARN
96 pgs degraded
31 pgs stuck unclean
96 pgs undersized
recovery 10/42 objects degraded (23.810%)
1/9 in osds are down
monmap e4: 3 mons at {box12=192.168.33.22:6789/0,box13=192.168.33.23:6789/0,box14=192.168.33.24:6789/0}
election epoch 82, quorum 0,1,2 box12,box13,box14
osdmap e426: 9 osds: 8 up, 9 in; 96 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v150626: 270 pgs, 1 pools, 10942 kB data, 21 objects
149 GB used, 189 GB / 339 GB avail
10/42 objects degraded (23.810%)
174 active+clean
96 active+undersized+degraded
Nach einer Weile:
[root@box12 ~]# ceph -s
cluster e4d48d99-6a00-4697-b0c5-4e9b3123e5a3
health HEALTH_OK
monmap e4: 3 mons at {box12=192.168.33.22:6789/0,box13=192.168.33.23:6789/0,box14=192.168.33.24:6789/0}
election epoch 82, quorum 0,1,2 box12,box13,box14
osdmap e429: 9 osds: 8 up, 8 in
flags sortbitwise,require_jewel_osds
pgmap v150925: 270 pgs, 1 pools, 14071 kB data, 22 objects
132 GB used, 168 GB / 301 GB avail
270 active+clean
Wir testen erneut:
[root@box12 ~]# ceph osd map rbd test osdmap e429 pool 'rbd' (0) object 'test' -> pg 0.40e8aab5 (0.b5) -> up ([4,1], p4) acting ([4,1], p4)
Das Objekt liegt einmal in Rack1 und einmal in Rack2. Passt!
Noch nicht genug? Ihr habt Interesse noch mehr über Ceph zu erfahren? Dann besucht doch unsere Schulung: Ceph Schulung 😉
Weiterführendes: http://www.crss.ucsc.edu/media/papers/weil-sc06.pdf
S3 und Swift mit dem Ceph Object Gateway (radosgw)
![]() Object Gateway ist eine Objektspeicher-Schnittstelle, welche Anwendungen eine RESTful HTTP Schnittstelle zum Ceph Object Store zur Verfügung stellt.
Object Gateway ist eine Objektspeicher-Schnittstelle, welche Anwendungen eine RESTful HTTP Schnittstelle zum Ceph Object Store zur Verfügung stellt.
Es werden 2 Schnittstellen unterstützt:
- S3-Kompatibilität: Stellt eine Objektspeicherfunktionalität mit einer Schnittstelle bereit, die zum größtenteils mit der Amazon S3 RESTful API kompatibel ist.
- Swift-Kompatibilität: Stellt die Objektspeicherfunktionalität mit einer Schnittstelle bereit, die zum größtenteils der OpenStack Swift API kompatibel ist.
Das Ceph Object Storage verwendet den RadosGW Daemon für die Interaktion mit dem Ceph Storage-Cluster. Als Backend kann hierfür das gleiche Ceph Storage Cluster verwendet werden wie für das Ceph Filesystem oder das Ceph Block Device.
Seit dem Ceph Release Jewel ist es nun auch möglich in einer MultiSite Konfiguration in die Nicht-Master-Zonen zu schreiben. Die Synchronisation der einzelnen Zonen funktioniert Out-of-the-box. Auf zusätzliche Agenten wird seit dem Jewel Release verzichtet.
Eine ausführliche Dokumentation für die Einrichtung eines MultiSite RADOSGateway findet man natürlich in der offiziellen Dokumentation oder auch bei uns in der Ceph Schulung.

Martin Schuster
Senior Systems Engineer
Martin gehört zu den Urgesteinen bei NETWAYS. Wenn keiner mehr weiss, warum irgendwas so ist, wie es ist, dann wird Martin gefragt. Er hat es dann eigentlich immer mal schon vor Jahren gesehen und kann Abhilfe schaffen :). Vorher war er bei 100world als Systems Engineer angestellt. Während er früher Nürnbergs Partykönig war, ist er nun stolzer Papa und verbringt seine Freizeit damit das Haus zu renovieren oder zieht einfach um und fängt von vorne an.
OSDC 2015: Der Countdown läuft – nur noch 50 Tage
Martin Gerhard Loschwitz präsentiert „What’s next for Ceph?“
OSDC? Noch nie gehört…
Das ist aber schade und fast schon ein unentschuldbares Versäumnis!
Aber wir holen das nach:
Die Open Source Data Center Conference (kurz OSDC) ist unsere internationale Konferenz zum Thema Open Source Software in Rechenzentren und großen IT-Umgebungen. 2015 findet sie zum siebten Mal statt und bietet mit dem Schwerpunktthema Agile Infrastructures ganz besonders erfahrenen Administratoren und Architekten ein Forum zum Austausch und die Gelegenheit zur Aneignung des aktuellsten Know-Hows für die tägliche Praxis. Diesmal treffen wir uns dafür in Berlin!
Workshops am Vortag der Konferenz und das im Anschluss an die Veranstaltung stattfindende Puppet Camp komplettieren dabei das Rundum-sorglos-Paket für Teilnehmer, die gar nicht genug Wissen in sich aufsaugen können.
What's next in Open Source Datacenter
Over here at NETWAYS last week was an ENGLISH WEEK and that means that all the meetings, standups, personal discussions and last but not least this blogpost (cause i wrote it last week) took place in English. Ok, to be honest there where some discussions at the restrooms and the smoking area that where still in German, but let’s say everywhere.
For most of the people over here Christmas holidays starts today and therefore I think this is a good moment to have a look on the things that will become important next year. To make it easier, I focus on a couple of things I see trending for us. Everything I write here is not the result of a survey or some official studies; it is just my personal opinion. You want to know why? Cause I can!
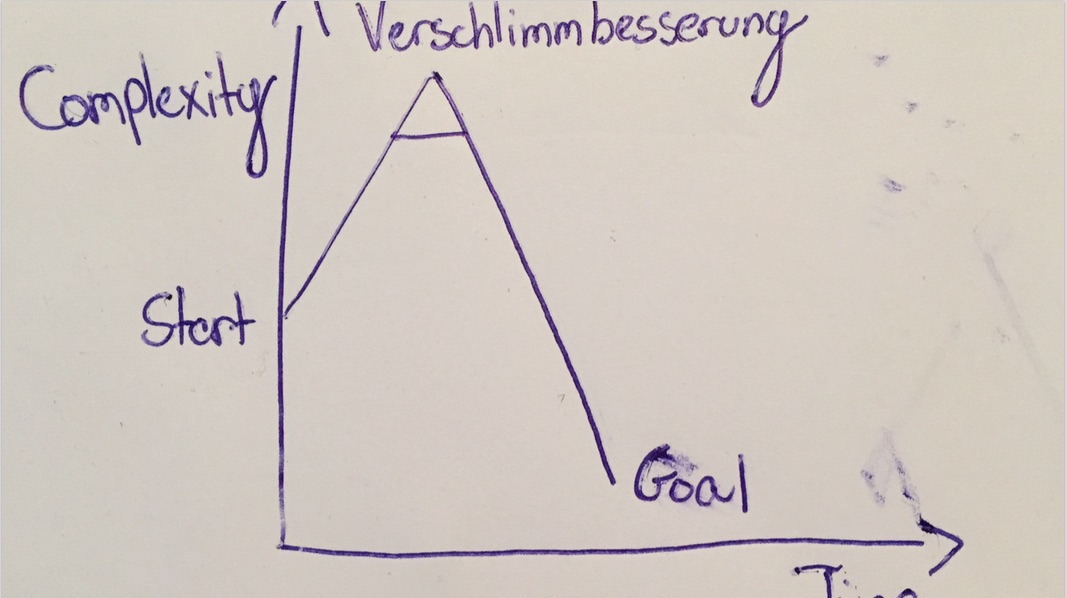
IaaS and Virtualization
A couple of years ago, XEN, KVM and tools to manage a bunch of hosts where really hot shit in IT. Nowadays, „nobody“ cares about the basic technology anymore and if somebody has more than four Raspberry Pis‘ he thinks about an OpenStack installation. It is straight forward, just install Nova, Neutron, Cinder, Glance, Swift and Ceilometer and you are ready to rumble. But the question is: do you really need it? Don’t get me wrong, I am not an OpenStack expert and I think if you want to provide public cloud service or if you have hundreds or thousands of machines it is definitely the way to go. But for 50 hosts in a heterogeneous environment? Really?
Since a couple of years, we have been using OpenNebula and I think it was one of the best decisions we made because it is flexible, stable, updates work like a charm and we normally don’t care about it. And last but not least, I think it is really important that solutions like OpenNebula, CloudStack or similar survive to provide an alternative.
Do I really talk about virtualization over here? Virtualization is something from the good old days. The thing you have to do today is container based virtualization. You HAVE to use Docker and if you are a real IT hipster you can have a look on Rocket. Don’t ask for the WHY, just use it. Move everything to a container, bring it to production and think about persistence later.
I am afraid you could missunstand me and I want to clarify that. I think Docker and the idea of container based virtualization is absolutely fantastic and there is and will be a big market in the future. But it is not for sure, that Docker is the right solution for you. I listened to an interesting talk from Simon Eskildsen at DevOpsDays Berlin 2014 about their experience of moving everything to Docker. His final statement: „We had problems before, but now it is even worse“.
Shopify is well known for their very modern IT and open source contributions, which tells me it makes sense to wait and see what will be next year. We (mainly Sebastian) invested a couple of weeks into Docker and Mesos and provide a one day workshop about it, because we think this is a technology of the future. But it is still very volatile and should be treated with caution. Perhaps Docker is dead next year and some other Rocket will leave our atmosphere.
Storage
We are working on kicking our NetApp out of the datacenter by the end of the month. We bought the first filer in 2008 and it really helps us to rely on a failure safe and robust architecture. A couple of months later, we added a shelf and life was great. But the demand for storage increased and therefore we needed to buy another shelf and learned the most important NetApp lesson: You „can“ add another shelf, but the CPU of the head is not strong enough (I think my first Nintendo had a stronger CPU) and the maintenance renewal would be so expensive that it makes sense to buy a new one. We did it three years ago and the migration worked out well. But time flies by and we had to renew our support again. And because of the growing demand for space and high availability, we need a second and a new one (because it is out of lifetime).
I am done with it and we started to find a replacement late last year. Our first choice was GlusterFS, because at this point it seems to be the best alternative for a NFS-Style replacement, which most of our customers need and Ceph(FS) was not good and stable enough in our opinion. So we gave GlusterFS a try and the first tests and production examples worked out well. With the increasing number of clients and GB on the storage our problems increased as well. We had a couple of situations with out-of-sync files and heavy load after an outage. At the end it was not possible to add additional nodes because the whole systems went crazy after that. We tried a lot. I had contact with developers but nobody was able to help us. This led us to Ceph this year and because of two reasons the decision was not so hard:
- We use OpenNebula and Bareos for backup and both support Ceph
- We were not able to find a real competitor
We have been running Ceph in production for months now and I think all the great (software) storage solutions out there will result in a dramatic change of the market. More and more service providers are specialized on open source storage solutions as well and it will be hard for NetApp, EMC and others to sell their products. They recognize this and provide cloud adapters and multi-tiered storage as well but they still trust in their original USP and their partners and I don’t think this will work out. Nobody is too big to fail and the named brands are far away from that. But buying racks of storage and throw them away a couple of years later is not the future. Storage is commodity and that will change the business model of selling fixed boxes.
Systems Management
This is definitely my area and probably also a danger zone, because I am not really objective. I think the Icinga project is awesome and with the new core and the upcoming web interface many things become possible. I think one of the major mind shifts the industry did in the last years is, that system management with all the „small“ things like monitoring and configuration management is not an additional component to provide IT. Now it is the foundation to provide fast, reliable and scalable services. This results in a dramatic change for monitoring as well. Monitoring is „no longer“ a subsequent IT discipline, but core services which need attention from day 1.
Taking this as fact, it is also important to understand a fundamental change in the architecture of a monitoring system. Nobody or let’s say hardly nobody needs an unified box to combine all monitoring fields like logging, event management, notification, altering, reporting and management. We need tools that integrate in the current architecture and provide interfaces to other tools specialized for certain things.
This has also a massive impact on our solutions and our service portfolio. We are confident, that it doesn’t make sense to reinvent the wheel again and again. It totally makes sense to provide an open solution and try to connect with as many tools as possible. We did and we will do so with Icinga and the current success speaks for itself. Providing an interface to Logstash, Graphite, Graylog2 and the „traditional“ monitoring add-ons like PNP4Nagios is the way to go and we’ll follow that road. Loosely coupled systems with specialization on metrics, logs or anything else, are the best and most flexible answer for high frequent changes in modern IT.
People
The biggest value you can have, and this counts more in an open source company, are the people driving your company. DevOps, DevOps, DevOps (just trying to make this SEO friendly) is a very good cultural movement in that direction and changes the way people interact and work together. DevOps is not about tools (sorry software vendors), it is about the people and their daily interaction and common way to solve problems reach the impossible and stay motivated. Putting Dev and Ops together is not the end and we’ll see more and more Q&A, project management and sales working together in teams in the future.
And if you think the idea of the cultural movement is overhyped, you might be right because of the buzzword, but not regarding the movement. Visiting traditional companies from time to time makes it clear to me, that there is a lot of work to do.
Conclusion
There is none. Pick something out if you want to or forget about it. Perhaps you think this post must be 5 years old, because you still have everything in AWS and the Senior DevOps Engineers in your company only do ChatOps with Hubot or Lita. And maybe this post doesn’t help you, but there are people out there who need more than help, they need a revolution.
Thanks to Sirupsen for the Verschlimmbesserung.

Bernd Erk
CEO
Bernd ist Geschäftsführer der NETWAYS Gruppe und verantwortet die Strategie und das Tagesgeschäft. Bei NETWAYS kümmert er sich eigentlich um alles, was andere nicht machen wollen oder können (meistens eher wollen). Darüber hinaus startete er früher das wöchentliche Lexware-Backup, welches er nun endlich automatisiert hat. So investiert er seine ganze Energie in den Rest der Truppe und versucht für kollektives Glück zu sorgen. In seiner Freizeit macht er mit sinnlosen Ideen seine Frau verrückt und verbündet sich dafür mit seinen beiden Söhnen und seiner Tochter.
















