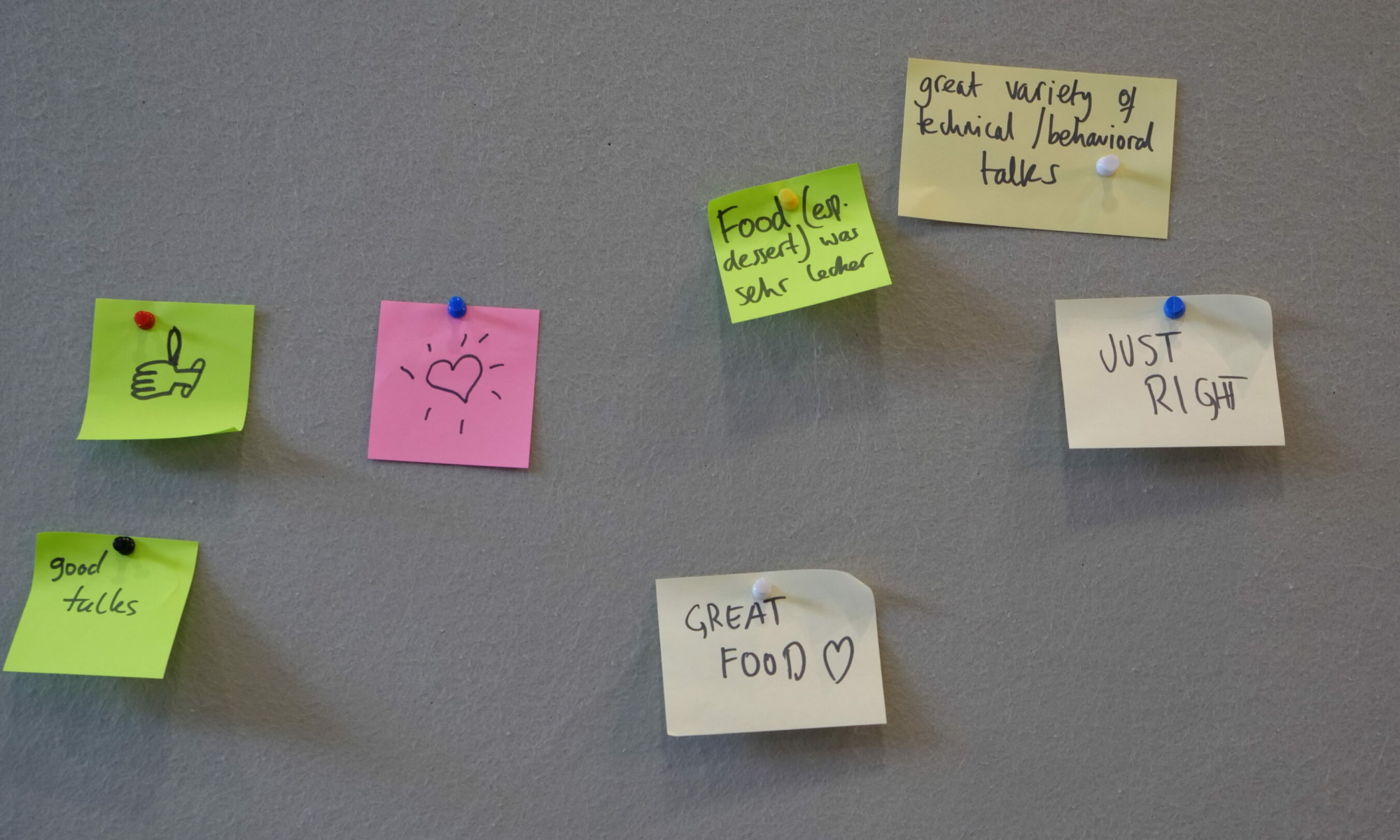Letzte Woche war es endlich so weit – Icinga Summit. Für mich war es dieses Jahr das erste Mal auf einer von Icinga direkt ausgetragenen Veranstaltung und ich muss sagen, dass das Format nicht nur bei mir sehr gut ankam.
In der Vergangenheit haben Events in Form der Icinga Camps lediglich einen Tag gedauert. Und man hat realisiert, dass das nicht so viel Zeit für einen Austausch bietet, wie man sich eigentlich wünscht. Apropos wünscht, gewünscht wurde sich in der Vergangenheit auch nicht selten, dass mehr Interaktion, Dialog beziehungsweise Diskussion stattfindet, und das wurde nicht nur abseits des Programms umgesetzt.
Community Spaces
Das Format unterscheidet sich von einer gewöhnlichen Konferenz insofern, als Zeit und Bühne für Community Spaces geboten wurde. Hier wurden zunächst Vorschläge gesammelt und je nach Thema diskutiert oder einander geholfen, Lösungen zu finden.
Natürlich ist ein Austausch unter den Mitgliedern der Icinga Community ohnehin an der Tagesordnung in den Pausen zwischen den Talks, aber der aktive Aufruf von organisatorischer Seite hat mich Sicherheit dazu beigetragen, dass sich Individuen mit ähnlichen Problemen finden, die sich sonst nie gefunden hätten.
Icinga Zertifizierung
Ebenso debütierte zum ersten Mal die Möglichkeit, sich zertifizieren zu lassen als Icinga Professional. Das Ganze wurde durch unsere Zuarbeit realisiert, um gewissenhaft als Icinga Partner zu definieren, was ein Icinga Professional sein soll. Zwar war der Icinga Summit zunächst die einzige Möglichkeit, vorab daran teilzunehmen, aber es lohnt sich Icinga auf den verschiedenen Kanälen zu folgen, falls man daran Interesse hat.
Das Programm
Selbstverständlich war ein Großteil des Programms mit interessanten und inspirierenden Talks gefüllt, die auf dem Icinga Youtube Kanal erscheinen werden. Aber Ihr müsst Euch noch ein paar Wochen gedulden. Auch wenn ich es vollkommen verstehen kann, dass Themen wie State of Icinga Notification oder State of Icinga Kubernetes schon seit der OSMC letzten Jahres auf interessante Neuigkeiten hungrig machen. Bleibt also gespannt!
Interaktive Workshops
Für mich persönlich steht fest: Zwei Tage war genau die richtige Entscheidung. Es entschleunigt den Tag und nimmt einem den Stress, dass die eigene Stimme in kurzer Zeit gehört werden will. Es hat mehr Platz für Gespräche und Entscheidungsfreiheit, in Form von Workshops gegeben, darunter nicht wenige, die von uns gehalten worden sind.
Sowohl Fans von Automatisierung/Orchestrierung sind auf ihre Kosten gekommen mit Thilos Beitrag zu Ansible, sowie Lennarts Workshop zu Puppet – welche gut besucht waren. Icinga For Windows wäre natürlich nicht Icinga For Windows, wenn Christian nicht auch einen zum Besten gegeben hätte.
Fazit
Abschließend kann ich nur sagen. Es hat sehr viel Spaß gemacht. Wirklich. Das ein oder andere Gesicht zusätzlich in der Community zu ordnen und die regen Unterhaltungen, welche neue Ideen aufflammen lassen können. Ich wäre gerne wieder dabei – beim nächsten Mal. Ansonsten hoffe ich, dass ich viele alte und neue Gesichter bei der OSMC dieses Jahr im November wieder sehen kann.

 In this
In this  Feu Mourek will cover Git fundamentals, including working directory, staging area, repository, and advanced branching strategies. You’ll learn to write effective commit messages, handle remotes, and resolve merge conflicts. They’ll also explore GitLab’s Web IDE, issue boards, and graphs to manage your workflow, track progress, and handle releases smoothly. You’ll master CI/CD by creating pipelines, using templates, and incorporating variables for flexible workflows.
Feu Mourek will cover Git fundamentals, including working directory, staging area, repository, and advanced branching strategies. You’ll learn to write effective commit messages, handle remotes, and resolve merge conflicts. They’ll also explore GitLab’s Web IDE, issue boards, and graphs to manage your workflow, track progress, and handle releases smoothly. You’ll master CI/CD by creating pipelines, using templates, and incorporating variables for flexible workflows.