Noch einmal schlafen und dann ist Weihnachten. Passend dazu haben wir von NETWAYS ein kleines Experiment zum selber Nachbauen vorbereitet.
Es handelt sich um eine kleine Weihnachtspyramide, die sich mithilfe von Python Code und ein paar Bauteilen ein wenig bewegt und außerdem noch schön leuchtet. Fast wie ein kleiner Weihnachtsbaum für jeden IT-Begeisterten da draußen.
Das braucht Ihr
Bevor wir starten, benötigen wir ein paar Dinge. Zum einen brauchen wir einen Raspberry-Pi mit Raspberry-PI OS. Das Modell spielt hierbei keine Rolle. Außerdem werden drei farbige LEDs, ein Steckbrett, ein kleiner Servo-Motor, ein Taster, sowie zehn GPIO-Verbindungskabel benötigt.
Und so funktioniert’s
Wie Ihr das Ganze verbinden müsst, seht Ihr in der Abbildung unten:
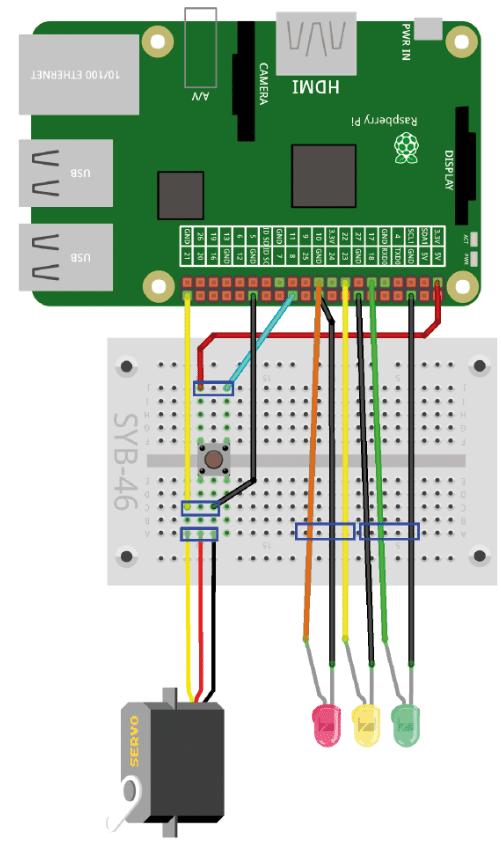
Ganz wichtig: Ihr müsst in der Raspberry Pi Konfiguration unter Schnittstellen noch den GPIO-Fernzugriff erlauben!
Der Programmcode lässt die Pyramide nach links und rechts drehen und die LEDs leuchten.
“#!/usr/bin/python
import RPi.GPIO as GPIO
import time
LED = [[17, 22, 10],[10, 22, 17]]
x = 0
t1 = 8
servoPIN = 21
GPIO.setmode(GPIO.BCM)
GPIO.setup(t1, GPIO.IN, GPIO.PUD_DOWN)
GPIO.setup(servoPIN, GPIO.OUT)
pwm = 2.5
a = 2.5
p = GPIO.PWM(servoPIN, 50)
p.start(pwm)
for i in LED[0]:
GPIO.setup(i, GPIO.OUT)
try:
while True:
p.ChangeDutyCycle(pwm)
pwm += a
if pwm==12.5 or pwm==2.5:
a = -a
time.sleep(0.2)
p.ChangeDutyCycle(0)
for i in LED[x]:
GPIO.output(i, True)
time.sleep(0.2)
GPIO.output(i, False)
if GPIO.input(t1) == True:
x = 1-x
except KeyboardInterrupt:
p.stop()
GPIO.cleanup()”
Wie Ihr Eure Pyramide, die auf den Servomotor gesetzt wird, gestaltet, ist Euch selbst überlassen.
Wie das ganze aussehen könnte, seht Ihr hier:

Viel Spaß beim Ausprobieren und fröhliche Weihnachten!
Wenn Ihr wissen wollt, wie wir bei NETWAYS unsere Weihachtsfeier gefeiert haben, lest Euch doch unseren Blogpost zur Weihnachtsfeier durch.