Für ein Storage ist Datenintegrität natürlich eine wichtige Eigenschaft, welches in Ceph unter anderem durch das sogenannte Scrubbing umgesetzt wird. In den meisten Fällen werden Daten in Ceph repliziert gespeichert, d.h. jedes Objekt wird mehrfach gespeichert. Bei Scrubbing prüft Ceph ob die Kopien der gespeicherten Objekte gleich sind. Dabei wird in zwei verschiedene Arten von Scrubbing unterschieden. Das normale Scrubbing vergleicht (wenn möglich) täglich die Attribute und Größe der Objekte. Deep-Scrubbing hingegen berechnet wöchentlich die Prüfsummen der Objekte und vergleicht diese. Treten Unterschiede auf werden diese korrigiert.
Das prüfen der Integrität geht natürlich stark zu lasten der Festplatten, da jedes Objekt eingelesen wird. Deshalb gibt es verschiedene Parameter um die Last zu streuen. Generell versucht Ceph die Scrubs über den ganzen Tag bzw. Deep-Scrubs über die ganze Woche zu verteilen. Verwendet man aber die Standardeinstellungen kann dies schnell dazu führen, dass diese Verteilung nicht mehr funktioniert.
- osd scrub load threshold = 0.5: Dies führt dazu, dass Scrubs nur bei einer Load von weniger als 0.5 durchgeführt werden. Bei einem Storage Server ist eine Load von 0.5 sehr schnell erreicht. Dieser Wert wird nicht an die Anzahl der Kerne adaptiert.
- osd scrub min interval = 86400 (täglich): Gibt an, nach wie vielen Sekunden Scrubs durchgeführt werden können, falls die Load nicht zu hoch ist.
- osd scrub max interval = 604800 (wöchentlich): Gibt an, nach wie vielen Sekunden Scrubs spätestens durchgeführt werden müssen. Der Load Threshold wird nicht berücksichtigt.
- osd deep scrub interval = 604800 (wöchentlich): Gibt an, nach wie vielen Sekunden Deep-Scrubs durchgeführt werden müssen. Der Load Threshold wird nicht berücksichtigt
Laut Mailingliste und IRC-Logs werden Deep-Scrubs immer und ausschließlich von normalen Scrubs angestoßen, und zwar dann wenn der letzte (normale) Scrub schon länger als eine Woche vergangen ist. Hat das Storage eine Load größer von 0.5 (was im Normalbetrieb immer der Fall ist), dann ist der Parameter osd scrub min interval sinnlos und es wird nach einer Woche ein normaler Scrub durchgeführt. Diese Kombination kann dazu führen, dass Deep-Scrubs erst nach osd scrub max interval + osd deep scrub interval durchgeführt werden. Im Standard Fall somit erst nach zwei Wochen. Je nach Startzeitpunkt der Intervalle werden alle Scrubs hintereinander durchgeführt was somit alle zwei Wochen im gleichen Zeitraum Last verursacht. Im Graphite und Grafana kann man solch ein Verhalten natürlich leicht erkennen 🙂
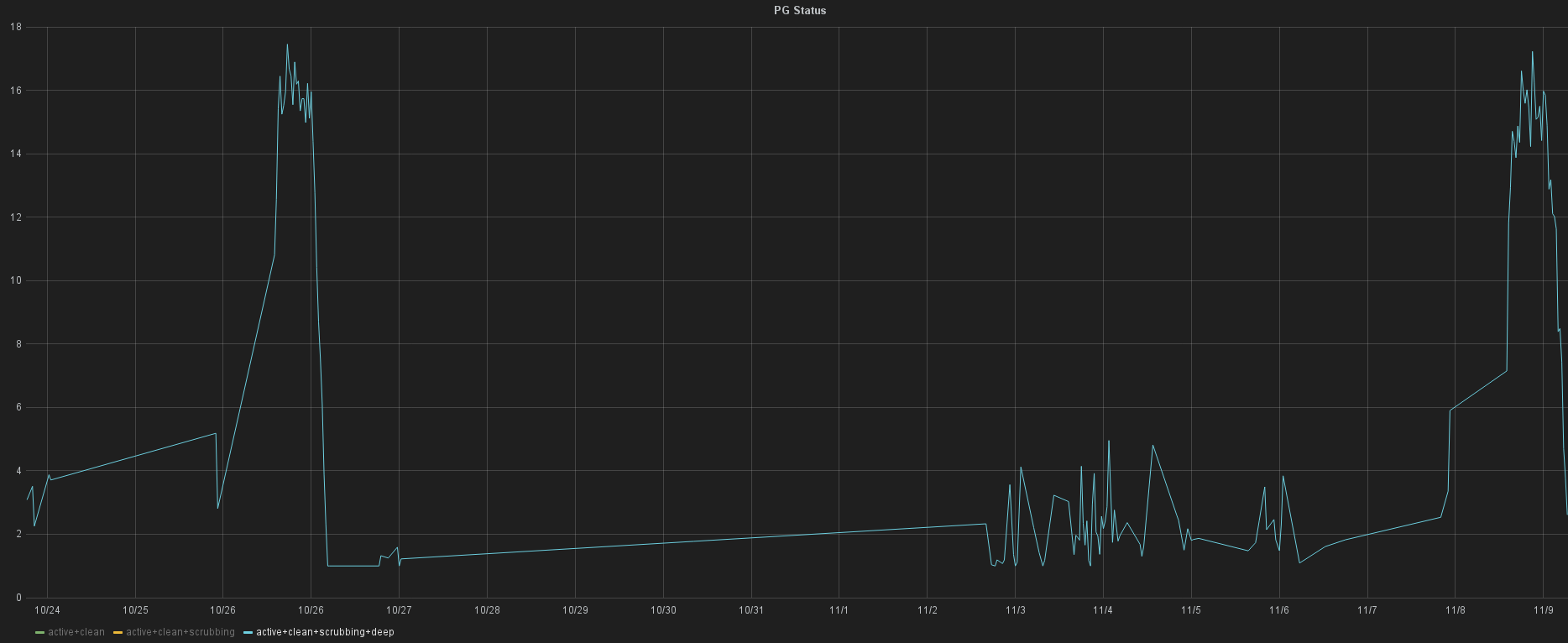
Ceph Deep Scrub
Zum Glück gibt es noch den Parameter osd max scrubs welcher mit der Standardeinstellung dazu führt, dass nur ein Scrub pro OSD zur gleichen Zeit stattfinden darf. Die Last auf den Storage hält sich somit in Grenzen und Anwender merken nichts davon.



















