Icinga hat in seinem Blogpost mitgeteilt, dass es mit Icinga for Windows v1.10.0 einige Änderungen an den Performance Metriken geben wird. Hier wollen wir einmal grob zusammenfassen, worum es geht und welche Auswirkungen diese Änderungen haben. Für alle Details ist der Original-Post aber sehr zu empfehlen!
Das Label-Problem
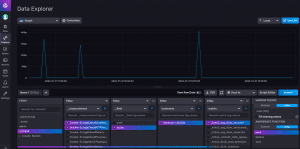
Ein grundlegendes Problem in aktuellen Icinga for Windows Versionen ist die Tatsache, dass die Labels für Performance Metriken zwar automatisch vom Icinga PowerShell Framework generiert werden, jedoch eine Filterung auf diese Werte innerhalb von Grafana nicht so einfach möglich ist. Nimmt man sich einmal das Partition-Space Plugin zur Hand, sehen die Metriken wie folgt aus:
‚free_space_partition_c’=10328260000B;;;0;491811100000
‚used_space_partition_c’=481483000000B;;;0;491811100000
Das Label ändert sich dabei, je nachdem ob das Plugin den Free- oder Used-Space der Partitionen überwacht. An sich wäre das nicht schlimm, da Grafana ja das Filtern über mehrere Metriken hinweg erlaubt. Jedoch ergeben sich Probleme bei komplexen Plugins oder wenn verschiedene Plugins eine ähnliche Struktur der Performance Metriken liefern – dann ist nicht mehr abzugrenzen, woher eine Metrik kommt.
Check_Multi Label
Um diesem Problem entgegenzuwirken, gibt es mit Icinga for Windows v1.10.0 im August einen Breaking Change: Alle Performance Metriken werden künftig im check_multi Format geschrieben. Dadurch ergeben sich eine Vielzahl von Vorteilen, da im Vorfeld schon während der Label Generierung ein Index, ein Template sowie ein Metrik Name definiert werden kann. Im Beispiel der oberen Performance Werte, sieht das Ergebnis dann wie folgt aus:
‚c::ifw_partitionspace::used’=480627800000B;;;0;491811100000
‚c::ifw_partitionspace::free’=11178000000B;;;0;491811100000
In diesem Beispiel wäre der Index unsere Partition c, das Template für die Visualisierung ifw_partitionspace und der Name der Metrik used oder free. Sowohl der Index als auch der Metrik Name müssen innerhalb der Plugins mittels der Funktion New-IcingaCheck gesetzt werden. Hierfür gibt es dann neue Argument, -MetricIndex und -MetricName. Das Template, in unserem Beispiel ifw_partitionspace, wird dabei automatisch je nach Name des Check-Plugins gesetzt.
Natürlich ergibt sich hierdurch ein kleiner Mehraufwand für Entwickler während des Bauens der Plugins, jedoch sind die Daten in der Regel sowieso vorhanden und werden in bisherige Labels eingearbeitet, weshalb dieser überschaubar ist.
Metriken Visualisieren
Da es sich hierbei um einen Breaking Change handelt und deshalb vorhandene Grafana Dashboards nicht mehr funktionieren, gibt es eine gute Nachricht: Icinga liefert ab Tag 1 der Icinga for Windows v1.10.0 für alle Plugins Grafana Dashboards aus!
Aufgrund technischer Gründe ist ein Parallelbetrieb von alten und neuen Performance Metriken nicht möglich, daher wurde dies zum Anlass genommen, standardisierte und von Icinga gepflegte Dashboards bereitzustellen. Hierfür wird lediglich InfluxDB 2 sowie Grafana benötigt. Wer bereits eigene Dashboards erstellt hat, kann sich die vorgefertigten Dashboards als Basis hernehmen und seine Ansichten anpassen, während neue User sich direkt aus dem Portfolio bedienen können.
Icinga Web 2 CPU Metriken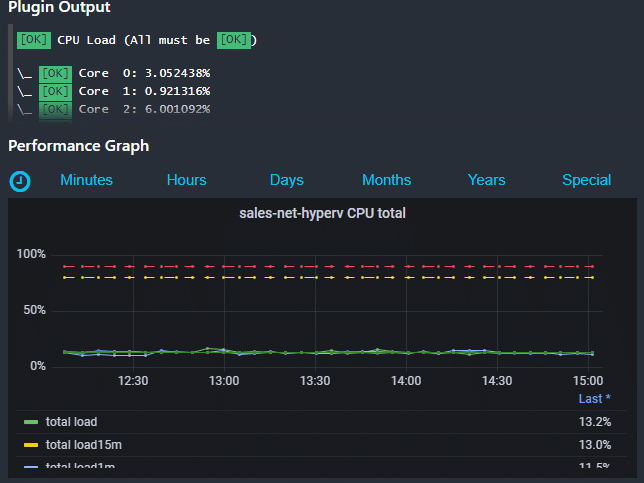
Icinga Web 2 Disk Metriken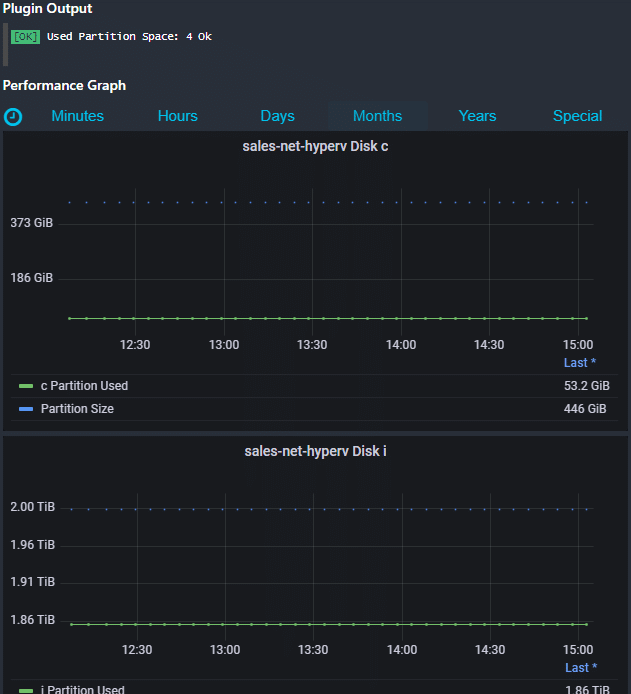
Grafana Basis-Dashboard für Icinga for Windows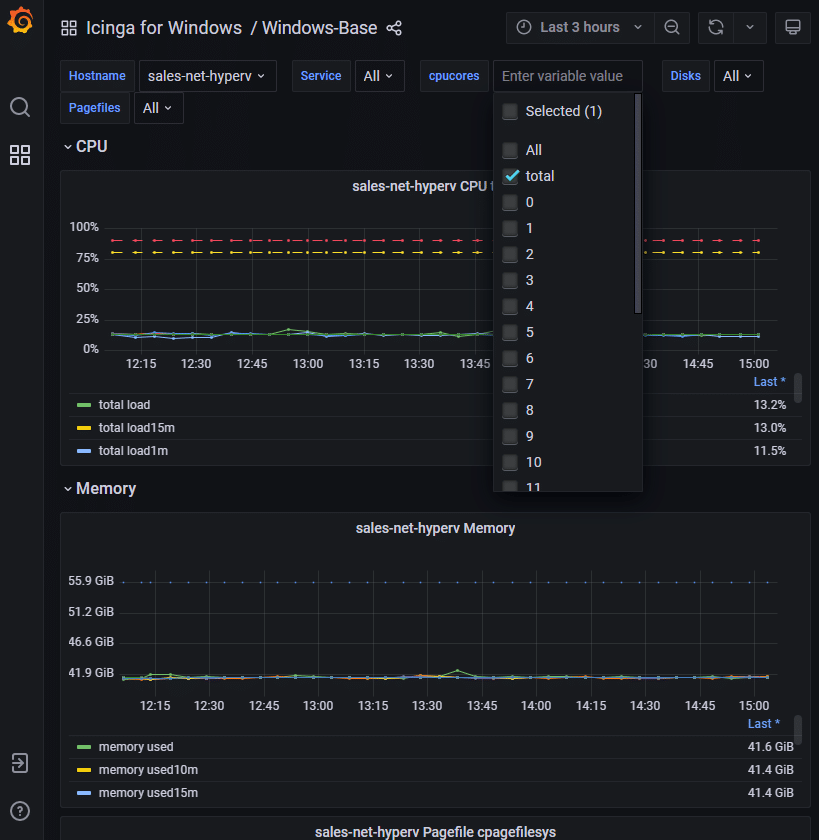
Wir freuen uns bereits sehr auf den Release von Icinga for Windows v1.10.0 im August und helfen gerne beim Update, der Implementierung oder Erweiterung. Hierzu könnt Ihr gerne mit uns Kontakt aufnehmen!