
Christoph hat euch ja bereits in einem früheren Blogpost vor ca. einem Jahr näher gebracht wie man Icinga 2 und InfluxDB 2 miteinander “zum Reden” bringt. Seit Icinga 2.13 steht nun auch der Influxdb2Writer zur Verfügung, welchen Afeef in seinem Blogpost benützt.
Ich möchte euch heute darauf basierend zeigen wie man nun das Setup erweitert und Grafana mit InfluxDB 2 konnektiert. Da InfluxDB 2 zum aktuellen Zeitpunkt sowohl die neue Flux Open Source Query Language (Flux) als auch noch die ältere Influx Query Language (InfluxQL) unterstützt, gibt es dafür grundsätzlich zwei verschiedene Möglichkeiten.
Zuerst stellen wir jedoch sicher das bereits ein Bucket für Icinga existiert und kopieren die ID für später:
$ influx bucket list
b860eefe6e38c504 icinga infinite 168h0m0s 6533ea60dddd2193 implicit
InfluxQL
Fangen wir mit der etwas aufwändigeren Methode an. Diese ist nötig wenn man InfluxDB 2 mittels InfluxQL abfragen möchte und geht nur auf CLI-Ebene. Dafür erstellen wir eine v1-Authentifizierung namens “grafana” mit lesendem Zugriff auf das Icinga-Bucket:
$ influx v1 auth create --username grafana --password ****** --read-bucket b860eefe6e38c504
$ influx v1 auth list
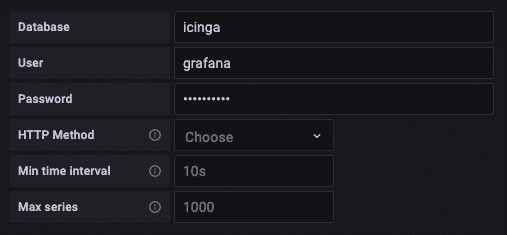
Genau dieser “username” und das zugehörige “password” wird dann bei Grafana in der jeweiligen Data Source mit der Query Language “InfluxQL” als “User” bzw. “Password” eingetragen. Zusätzlich geben wir bei “Database” den Namen des Buckets, in unserem Fall “icinga”, an.
Flux
Für Flux gestaltet sich das Ganze etwas einfacher, da hier die native Authentifizierung verwendet werden kann:
$ influx auth create --description grafana --read-bucket b860eefe6e38c504
$ influx auth list
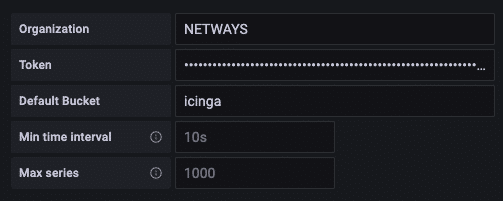
Bei der Data Source mit der Query Language “Flux” ist dann in Grafana der soeben erstellte lange und kryptische “Token” einzutragen. Außerdem wird das Bucket, beispielhaft “icinga”, und die Organisation benötigt. Diese wird beim initialen Setup von InfluxDB generiert und lässt sich wie folgt herausfinden:
$ influx org list
Wem das jetzt etwas zu Trocken war, dem kann ich gerne unsere Schulung zum Thema InfluxDB & Grafana nahe legen. Dort wird das im Kontext nochmal anschaulicher erklärt und auch Rückfragen sind natürlich gestattet.


















0 Kommentare