![]() Die Standardwerkzeuge im Mac sind alle samt schon ziemlich gut. Für mich aber eine der Ausnahmen: Der Finder! Meistens finde ich mich dann mit 10 offenen Fenstern wieder oder ich verschiebe das Zeug in andere Verzeichnisse, weil die Oberfläche nicht schnell genug reagiert (Tabs wechseln, Verzeichnisse expandieren). Entnervt erledige ich dann die Überbleibsel im Terminal.
Die Standardwerkzeuge im Mac sind alle samt schon ziemlich gut. Für mich aber eine der Ausnahmen: Der Finder! Meistens finde ich mich dann mit 10 offenen Fenstern wieder oder ich verschiebe das Zeug in andere Verzeichnisse, weil die Oberfläche nicht schnell genug reagiert (Tabs wechseln, Verzeichnisse expandieren). Entnervt erledige ich dann die Überbleibsel im Terminal.
Alfred Workflow
Standardmäßig gibt es einen “Open-Workflow” in Alfred. Dieser öffnet entweder Dateien oder Verzeichnisse. Aber es geht noch besser: “Open Finder Tab“. Dabei bleibt ein Fenster offen und es werden weitere Tabs hinzugefügt:
Yoink
Wie schaut es dann mit anderen Artefakten aus? Mails, Preview oder URL’s? Dafür bin ich vor einiger Zeit auf Yoink gestoßen. Yoink ist ein kleiner temporärer Container allgemein Dateireferenzen zwischenspeichern kann. Dies können z.B. URL’s sein, Inhalt der Zwischenablage, Dateien. Dabei integriert es sich Nahtlos in die Oberfläche mit einem kleinen Fenster, was bei “Drag and drop” Operationen eingeblendet wird.
Beide Tools, Alfred wie auch Yoink sind nicht kostenfrei sind aber definitiv den Einkauf wert. Mir erleichtern sie massiv die tägliche Arbeit mit dem Finder!

 Es gibt einen ganzen Haufen Müll im Weltraum den man praktischerweise nicht sieht und sich aus diesem Grund wenig Gedanken darum macht. Das Inter-Agency Space Debris Coordination Committee (IADC) überwacht im Moment ca. 80000 Objekte ab der Größe eines Fußballs. Nimmt man kleinere Teile inklusive Partikel in der Größe mehrerer Millimeter hinzu, gehen Schätzungen mittlerweile von mehreren Millionen Teilchen in verschiedenen Umlaufbahnen aus. Durch eine Art Domino Effekt (
Es gibt einen ganzen Haufen Müll im Weltraum den man praktischerweise nicht sieht und sich aus diesem Grund wenig Gedanken darum macht. Das Inter-Agency Space Debris Coordination Committee (IADC) überwacht im Moment ca. 80000 Objekte ab der Größe eines Fußballs. Nimmt man kleinere Teile inklusive Partikel in der Größe mehrerer Millimeter hinzu, gehen Schätzungen mittlerweile von mehreren Millionen Teilchen in verschiedenen Umlaufbahnen aus. Durch eine Art Domino Effekt (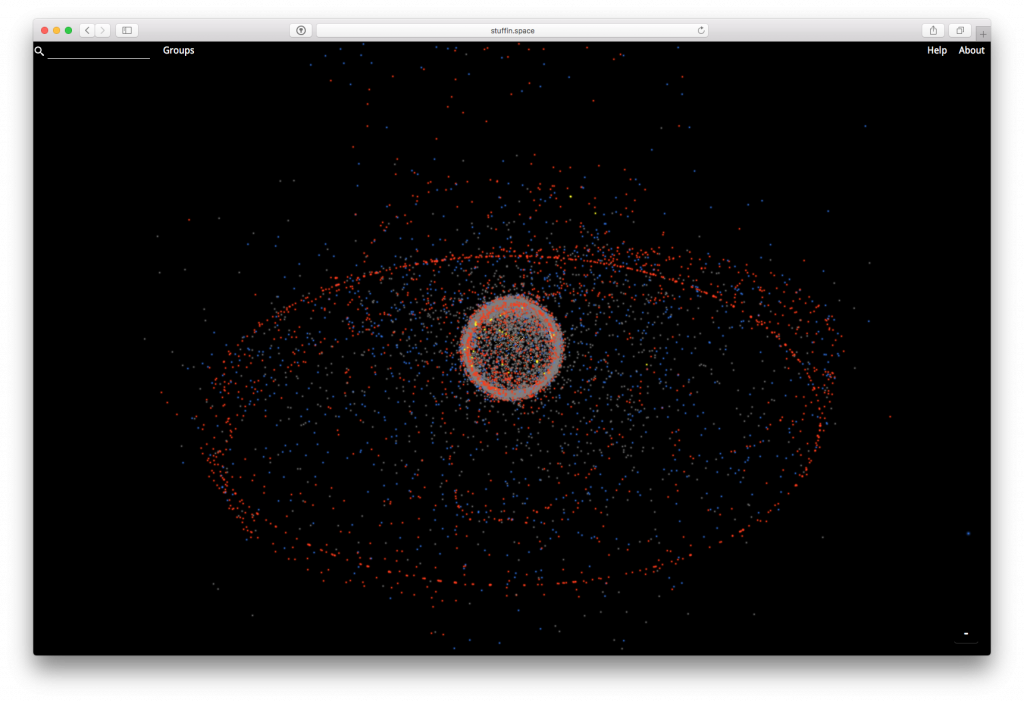
 Mal ehrlich, wer hat denn kein Facebook Profil, ist nicht bei LinkedIn, WhatsApp oder Twitter? Ich vermute: Die wenigsten! Denn ohne geht es heute kaum noch. Da werden Termine nur noch über Gruppen kommuniziert oder der Arbeitgeber macht sich ein Bild über einen potentiellen Bewerber. Man will ja dabei sein, sich gut verkaufen, nicht wahr?
Mal ehrlich, wer hat denn kein Facebook Profil, ist nicht bei LinkedIn, WhatsApp oder Twitter? Ich vermute: Die wenigsten! Denn ohne geht es heute kaum noch. Da werden Termine nur noch über Gruppen kommuniziert oder der Arbeitgeber macht sich ein Bild über einen potentiellen Bewerber. Man will ja dabei sein, sich gut verkaufen, nicht wahr?
















