
- Kubernetes 101: Was ist eigentlich Kubernetes?
- Kubernetes 101: Aufbau eines K8s-Cluster und die Möglichkeiten der API
- Kubernetes 101: Welche Installationsmöglichkeiten bietet Kubernetes?
- Kubernetes 101: So installierst und verwaltest du Anwendungen
- Kubernetes 101: Anwendungen in Kubernetes skalieren
- Kubernetes 101: Wie sichere ich Kubernetes ab?
- Kubernetes 101: Die nächsten Schritte
In meinem ersten Blogpost ging es zuerst einmal darum zu klären, was Kubernetes denn eigentlich ist. Jetzt, wo wir ergründet haben, welche Ansätze und Ideen Kubernetes verfolgt und warum diese sinnvoll sein können, gehen wir einen Schritt weiter, und schauen uns an, wie diese umgesetzt werden. Dafür wollen wir zwei Aspekte betrachten: Zum Einen der Aufbau eines Kubernetes-Clusters selbst, inklusive aller Teilbausteine, die für den reibungslosen Betrieb benötigt werden. Zum Anderen die im letzten Blogpost bereits mehrfach erwähnte API, wir als Schnittstelle nutzen und die uns eine ganze Bandbreite an API-Ressourcen anbietet, mit denen wir auf Kubernetes arbeiten können. Let’s get going!
Aufbau eines Kubernetes-Clusters
Beginnen wir mit einem sog. “Ten-Thousand Foot View“, um uns den groben Aufbau eines Clusters auf Infrastrukturebene vor Augen zu führen:
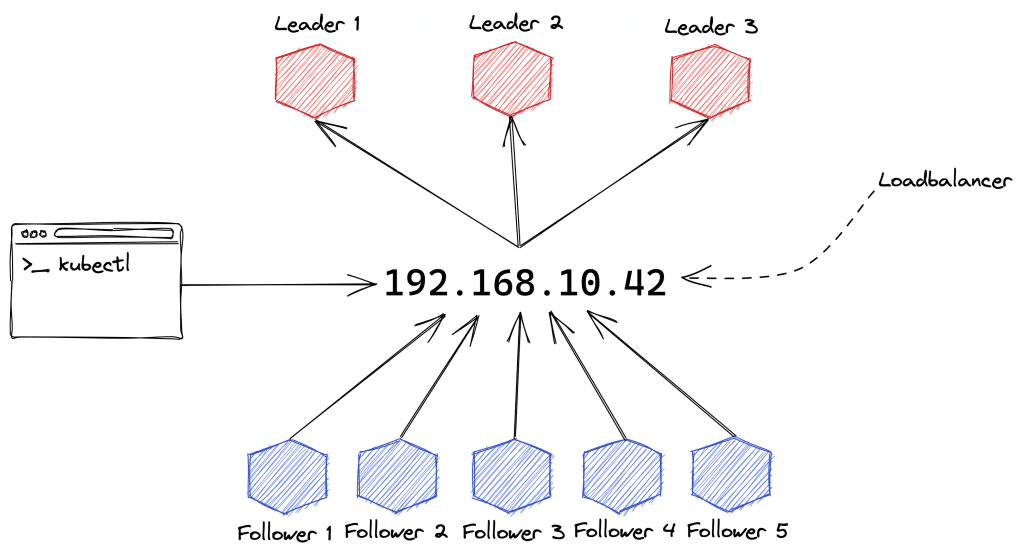
Wir sehen hier ein Cluster bestehend aus 8 Nodes – drei sog. Leader-Nodes und fünf Follower-Nodes. Die Leader-Nodes bilden zusammen die sog. Controlplane des Clusters und stellen Dienste wie clusterinternes DNS und die Kubernetes-API bereit. Um die API und damit letzten Endes das Cluster hochverfügbar zu machen, wird der Controlplane ein Loadbalancer vorgelagert. In Cloud-Umgebungen ist dies oft per Default die bereitgestellte Lösung des jeweiligen Providers, in eigenen Rechenzentren oder on-premise kann hierfür auf Lösungen wie HAProxy oder MetalLB zurückgegriffen werden. Best Practices diktieren, dass auf den Leader-Nodes möglichst keine Anwendungen deployed werden sollten, die nicht für den Betrieb des Clusters selbst benötigt werden.
Hierfür sind die fünf Follower-Nodes gedacht, die mit der Kubernetes-API ebenfalls via Loadbalancer interagieren und die für den jeweiligen Node gescheduleten Anwendungen ausführen. Auf diesen Nodes können beliebige Anwendungen entsprechend der jeweils verfügbaren Ressourcen deployed werden. Die API in der Controlplane kümmert sich hierbei um ein passendes Scheduling, damit Ressourcen auf den Follower-Nodes nicht erschöpft werden und angegebene Voraussetzungen wie bspw. spezielle benötigte Hardware (GPU, SSD, etc.) auf dem jeweiligen Node erfüllt werden.
Die letzte im Schaubild dargestellte Komponente stellt eine lokale Terminalsession auf Seiten eines Endnutzers dar. Dieser kommuniziert via kubectl mit der Softwareschnittstelle, dem de-facto Standardtool für Interaktion mit der API von außerhalb des Clusters.
Doch welche Komponenten laufen denn nun auf den jeweiligen Node-Klassen? Gehen wir doch einmal etwas weiter ins Detail:
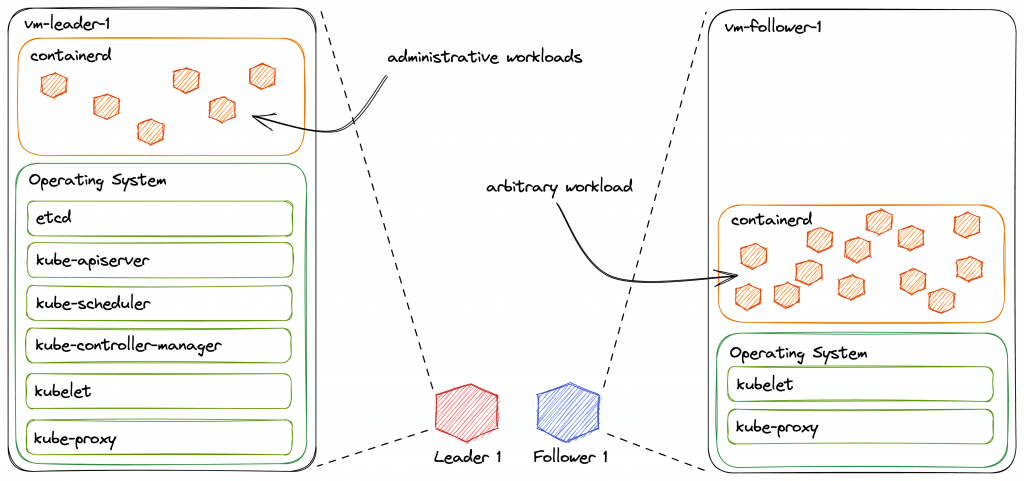
Wir sehen hier exemplarisch jeweils einen Leader und Follower-Node als VMs in der Detailansicht, mit all den Anwendungen, die auf den jeweiligen Node-Klassen typischerweise installiert sind. Gehen wir die verschiedenen Anwendungen doch einmal durch:
- etcd – Key/Value-Store für den Zustand und die Historie der Kubernetes-API; Wird normalerweise auf den Leader-Nodes installiert, kann allerdings auch auf externe Maschinen ausgelagert werden
- kube-apiserver – PI-Server des Kubernetes-Clusters; Wird für Hochverfügbarkeit auf allen Leader-Nodes installiert
- kube-scheduler – Kümmert sich um das Scheduling der in das Cluster deployten Anwendungen; Wird auf Leader-Nodes installiert
- kube-controller-manager – Ein Bündel an sog. Kubernetes-Controllern, das sich um die Verwaltung verschiedener Kubernetes-Ressourcen kümmert; Wird auf Leader-Nodes installiert
- kubelet – Kommuniziert mit der API und der lokalen Container-Runtime, um Container auf den Nodes auszuführen; Wird auf allen Nodes installiert
- kube-proxy – Routet Netzwerk-Traffic zu Containern, sobald dieser auf den jeweiligen Nodes ankommt; Wird auf allen Nodes installiert
- Container Runtime – Im Beispiel containerd; andere Implementierungen sind möglich, bspw. CRI-o; Wird auf allen Nodes installiert
Zu erwähnen ist, dass nicht alle Cluster so aussehen müssen. Beispielsweise ließe sich auch eine Controlplane umsetzen, auf der keinerlei Container ausgeführt werden – in diesem Fall könnte man auf die Installation von kubelet, kube-proxy und containerd auf Leader-Nodes verzichten (für eine Referenzinstallation s. Kubernetes the Hard Way auf GitHub). Auf Clustern in der Cloud wird man außerdem fast immer einen sog. cloud-controller-manager auf Leader-Nodes finden, der gewisse Funktionalitäten im Cloud-Bereich integriert, bspw. automatische Provisionierung benötigter Loadbalancer in der hostenden Cloud.
Auch können sich die genauen Ausprägungen einer Kubernetes-Installation je nach Kubernetes-Distribution unterscheiden – momentan listet die CNCF 59 zertifizierte Distributionen. K3s bspw. bündelt die verschiedenen Komponenten in eine Binary, was den Betrieb im Alltag etwas erleichtern kann und den Ressourcen-Fußabdruck des Clusters senkt.
Die Kubernetes’ API – endlose Weiten
Haben wir unser Cluster nun wie oben skizziert (oder ganz anders) installiert, möchten wir natürlich mit ihm interagieren – hierfür gibt es verschiedene Möglichkeiten, angefangen bei cURL über das offizielle Kubernetes Dashboard bis zu Wrappern für das lokale Terminal. Letzteres ist der gängigste Weg – fast alle Tutorials und technische Dokumentationen zu Kubernetes und darauf zu installierende Anwendungen erwähnen kubectl, was sich auf jedem gängigen Betriebssystem paketiert installieren lassen sollte. Haben wir kubectl lokal installiert und eingerichtet (wir benötigen eine sog. kubeconfig, die Verbindungsinformationen für unser(e) Cluster enthält), können wir uns zum ersten Mal die API anschauen:

Je nach Cluster (im Beispiel ein Rancher Desktop Cluster) scheint uns Kubernetes zwischen 60 und 70 verschiedene API-Objekte anzubieten! Wo also anfangen und wo aufhören? Oder gleich alle 70 behandeln? Fangen wir doch einfach mit der kleinsten Einheit an Workload an, die K8s für uns bereit hält – dem Pod. Ein Pod kapselt einen oder mehrere Container in einem Bündel, das sich Netzwerk- und Speicherressourcen teilt.
Daraus folgt, dass alle Container eines Pods immer auf demselben Node gescheduled werden. Ein Pod alleine profitiert allerdings noch nicht von Kubernetes’ Orchestrierungsmöglichkeiten – ist bspw. der hostende Node nicht erreichbar, können wir auch die in unserem Pod laufenden Anwendungen nicht mehr erreichen.
Wir benötigen also eine weitere Abstraktionsebene, die es uns erlaubt, mehrere identische Pods auf verschiedene Nodes zu schedulen: das sog. Deployment. Ein Deployment definiert ein Pod-Template, sowie eine Anzahl an gewünschten Repliken und weitere Konfiguration, die von Kubernetes zur Orchestrierung des Deployments genutzt wird. Unter der Haube wird dann vom API-Server ein ReplicaSet erzeugt, das die gerenderte Version des Pod-Templates enthält.
Auf diese Weise ermöglicht eine Deployment-Ressource uns nicht nur die Ausführung mehrerer Repliken eines einzelnen Pods, sondern auch eine Versionierung verschiedener ReplicaSets – wieviele genau von der API gespeichert werden, hängt von den Einstellungen des API-Servers zusammen. Hier nochmal ein Schaubild zu den Zusammenhängen:
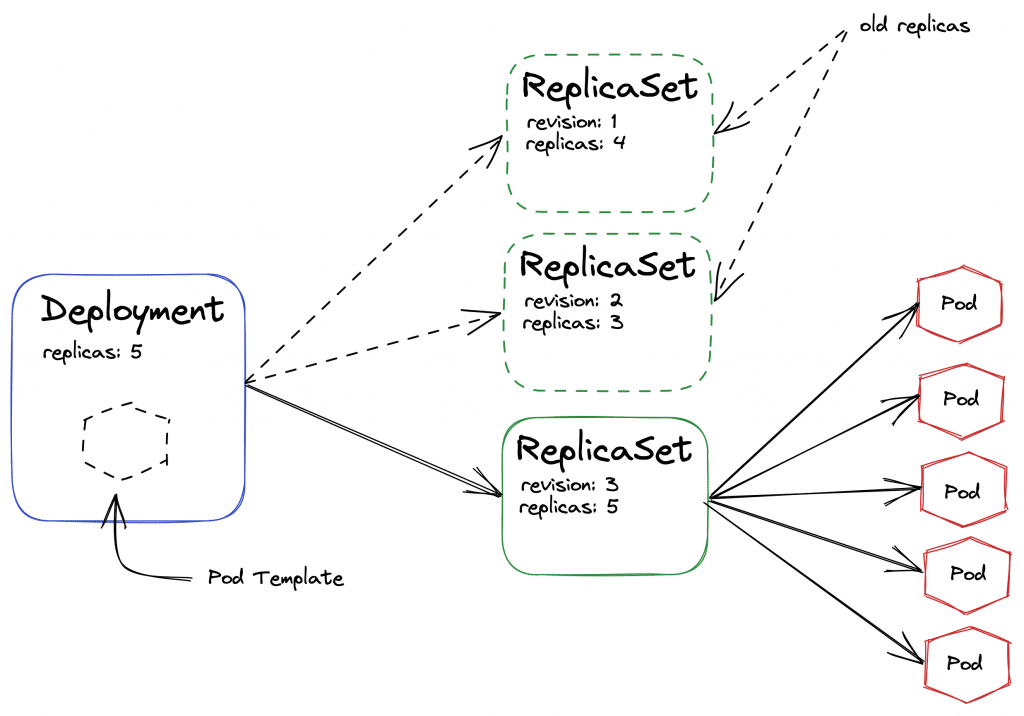
Zu sehen ist ein Deployment mit drei dazugehörigen ReplicaSets, die sich in der Anzahl der definierten Replicas unterscheiden (Kubernetes erstellt bei jeglicher Änderung eines Deployments ein neues ReplicaSet, nicht nur bei Änderung der Replicas). Das momentan aktive ReplicaSet wiederum verwaltet der Konfiguration entsprechend fünf Pods.
Möchte man seine deployten Anwendungen nun untereinander oder für Endnutzer außerhalb des Clusters verfügbar machen, kommen Services ins Spiel. Ein Service ist eine API-Ressource, die einen gewissen Pool an Pods als Endpoints definiert und für diese als Round-Robin Loadbalancer fungiert. Auf diese Weise benötigt man nur eine IP, um zuverlässig einen funktionalen Pod eines Deployments zu erreichen. Kubernetes kümmert sich hierbei automatisch darum, Traffic nur zu funktionalen Pods weiterzuleiten.
Es gibt drei Arten von Services:
- ClusterIP – der Service erhält eine innerhalb des Clusters erreichbare IP-Adresse, ist von außerhalb des Clusters aber nicht ohne Weiteres zu erreichen
- NodePort – der Service wird auf jedem Node auf einem zufälligen, hohen Port (ca. 30.000+) verfügbar gemacht
- Loadbalancer – eine Erweiterung des NodePort-Typs, wobei den Ports ein Loadbalancer vorgelagert wird; funktioniert am reibungslosesten in Public Clouds
Zusätzlich gibt es die Möglichkeit, HTTP-Traffic anstatt mittels Loadbalancer auf L4 mit einem sog. Ingress auf L7 zu routen – die Konfiguration unterscheidet sich hierbei abhängig vom genutzten IngressController.
Weitere nennenswerte, grundlegende API-Ressourcen innerhalb von Clustern wären bspw. Namespaces zur Trennung von anwendungslogisch zusammenhängenden Deployments etc. sowie zur Umsetzung von role-based access control (RBAC), Secrets zur Bereitstellung vertraulicher Daten wie bspw. Passwörtern, Zertifikaten, oder Token, und ConfigMaps für häufig genutzte Konfigurationssnippets. Wer mitgezählt hat wird merken, dass wir gerade erst bei 7 von den oben angezeigten 70 Ressourcentypen angekommen sind – und das ist noch lange nicht das Ende der Fahnenstange, da eine der Stärken der Kubernetes-API schließlich ihre Erweiterung durch sog. CustomResourceDefinitions (CRDs) ist. Für einen ersten Einblick soll der momentane Stand trotzdem fürs Erste genügen.
kubectl – das Schweizer Taschenmesser für Kubernetes
Bereits im letzten Absatz eingangs erwähnt, ist jetzt der Moment für kubectl gekommen, das offizielle Kommandozeilentool für den täglichen Umgang mit Kubernetes und seiner API. Ich könnte an dieser Stelle mehrere 1000 Wörter über den Gebrauch schreiben und trotzdem noch sehr viel unerwähnt lassen, und genau aus diesem Grund folgt nun gemäß dem Motto “Ein Bild sagt mehr als tausend Worte” lediglich eine Auflistung einiger gängiger und oft genutzter kubectl Kommandos, um einen ersten Eindruck von der Nutzung des Tools zu bekommen.
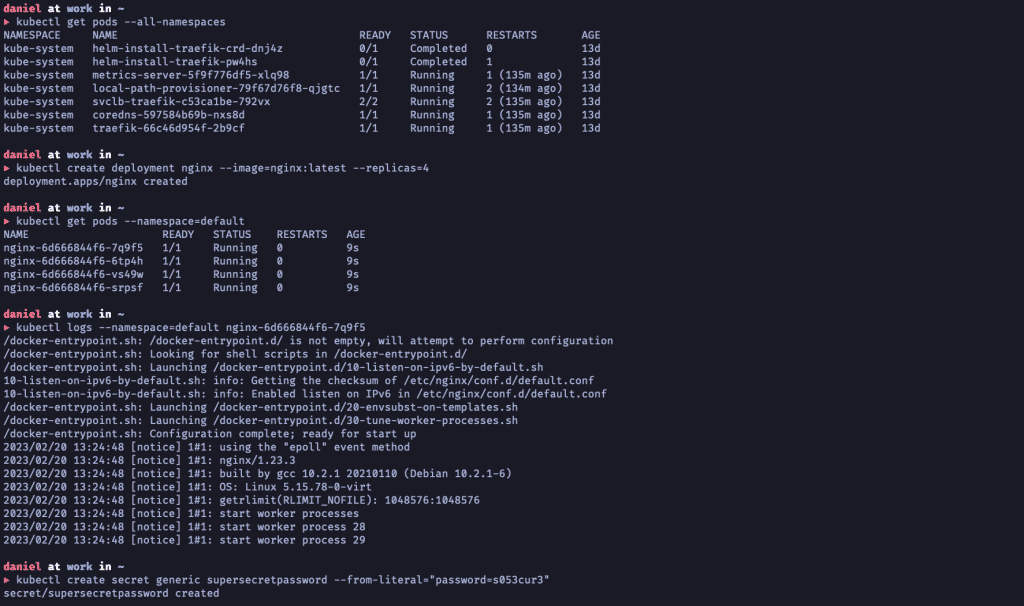
Hier zu sehen sind einige der häufigsten Kommandos, zu denen neben get und create wohl auch noch apply, logs und describe gehören dürften. Neben dem expliziten (imperativen) Erstellen von API-Ressourcen via CLI können mit kubectl auch bestehende Kubernetes-Manifeste (in YAML oder JSON) in das Cluster “gepusht” werden, was einem deklarativen Ansatz entspricht und in der Praxis der gängigere Weg ist.
Für heute war das aber genug trockene Theorie rund um Architektur, API-Aufbau und Clusterkomponenten – im nächsten Teil der Serie werden wir uns genauer anschauen, wie wir uns denn nun basierend auf der in diesem Artikel erläuterten Architektur unser eigenes Cluster installieren können, entweder auf lokaler Infrastruktur, in der Cloud (z.B. Managed Kubernetes bei NMS), oder auf deinem persönlichen Rechner! Abonniere also gerne auch den RSS-Feed unseres Blogs und sei bereit für den nächsten Artikel der Kubernetes 101 Reihe!


















0 Kommentare