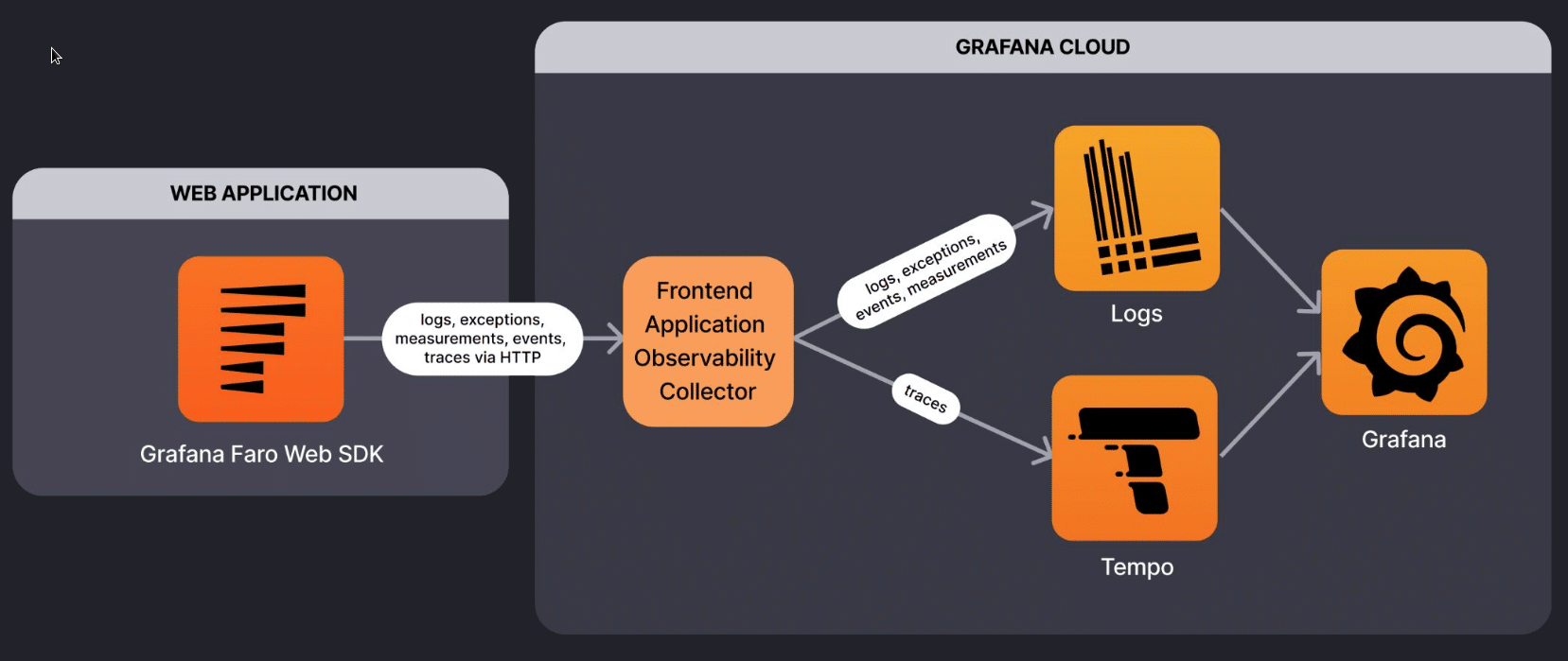
In his talk at the Open Source Monitoring Conference 2022 (OSMC) Jonah Kowall – having more than 15 years of experience in the fields Ops, network, security, and performance engineering under his belt – tells us a lot about observability in the open source market. He also focusses on possible problems regarding licensing.
In the following I will give you a brief overview of the topics and concepts behind.
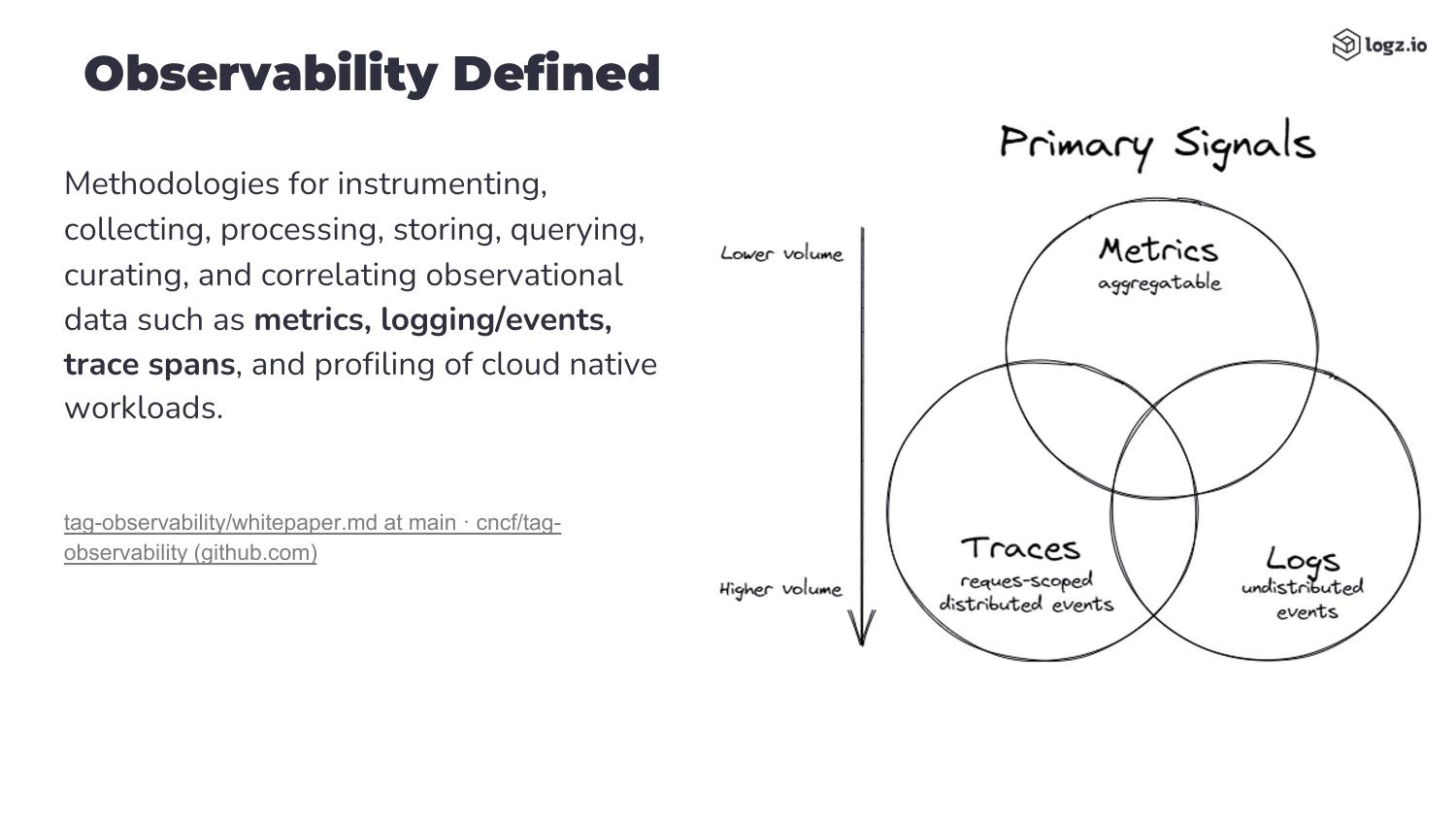
What is Observability?
First things first, what is observability? And how does it differ from monitoring?
To greatly simplify:
- Monitoring is used to track specific criteria of given hosts/devices across your infrastructure. Thus, monitoring means having an eye on specific metrics such as CPU load or RAM usage. This enables you to notice problems as they occur and act accordingly.
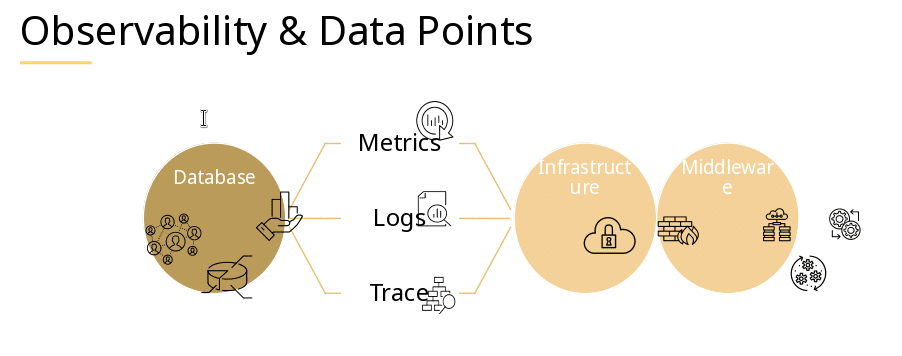
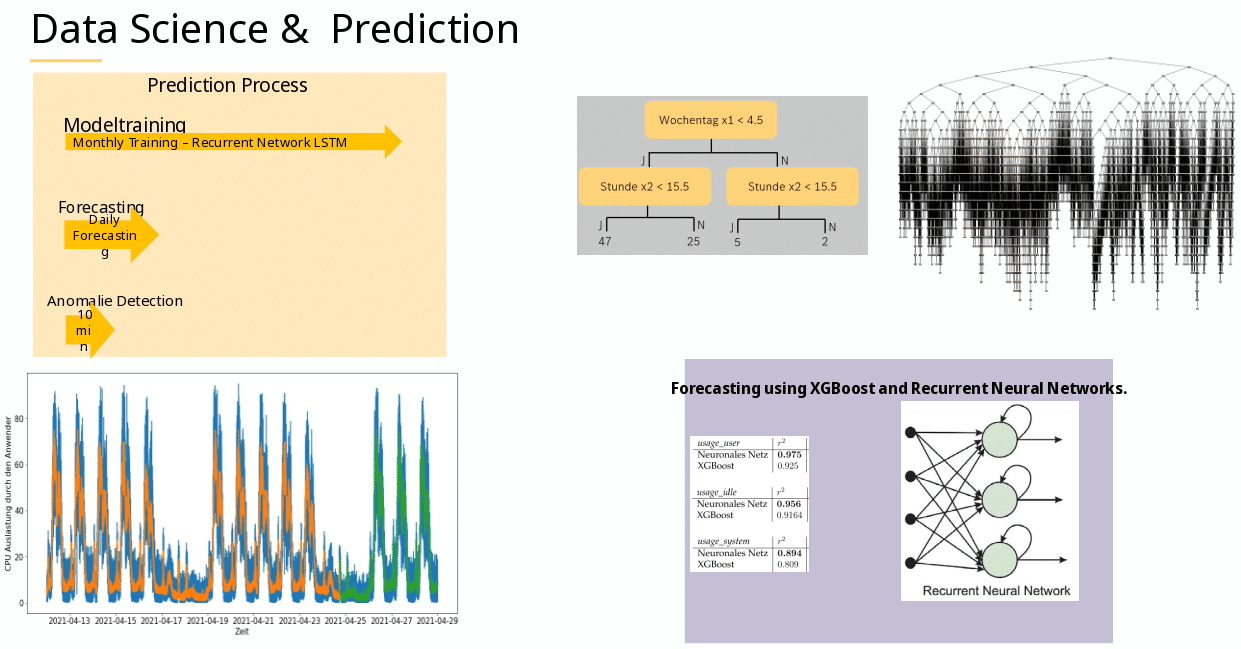
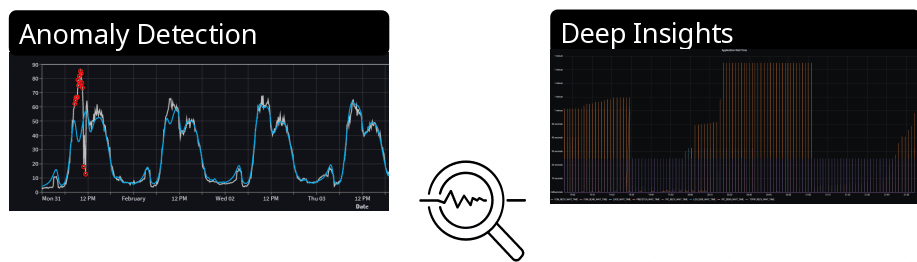
- Observability on the other hand means collecting “all” data. Based on the inputs a system receives and its respective outputs you are meant to be able to draw conclusions about your system’s state.
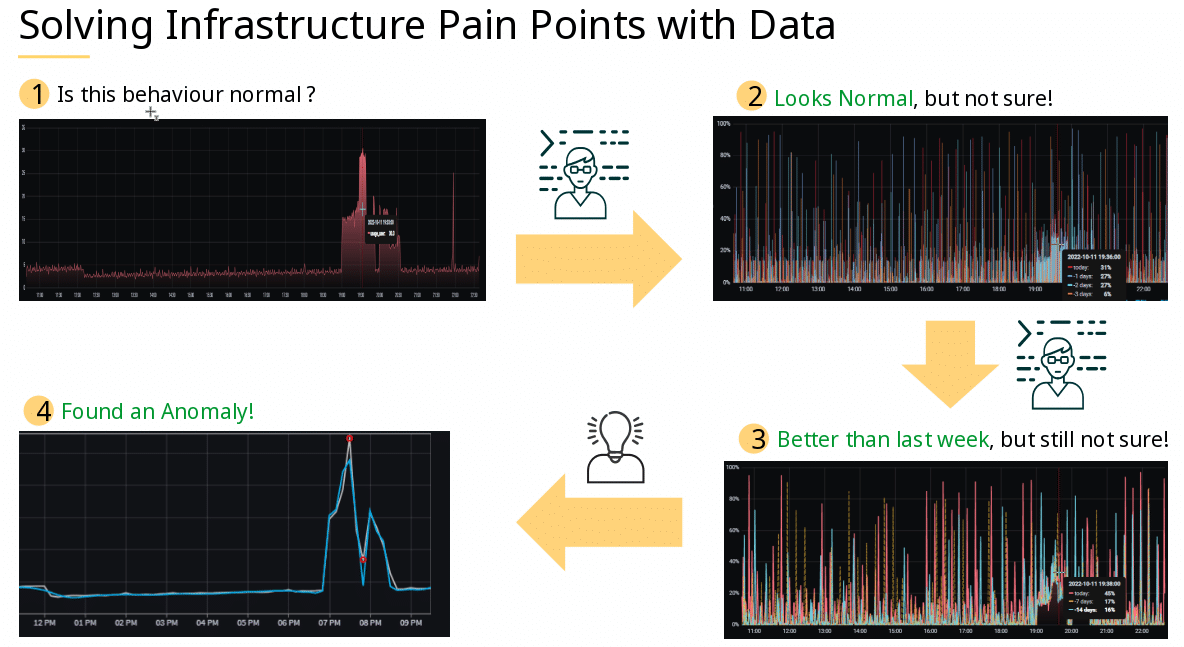
Sticking with the RAM example, monitoring can show you that your system runs low on memory, while observability can tell you why that is. This “why” is also helpful in order to act appropriately before the “that” happens. So, monitoring effectively follows a reactive approach and observability follows a proactive one.
Now let’s let his presentation give us an explanation.
Commercial vs. Open Source solutions
As Jonah goes on to explain, commercial tools for observability tend to be more coherent and complete out of the box when it comes to the user interface (UI).
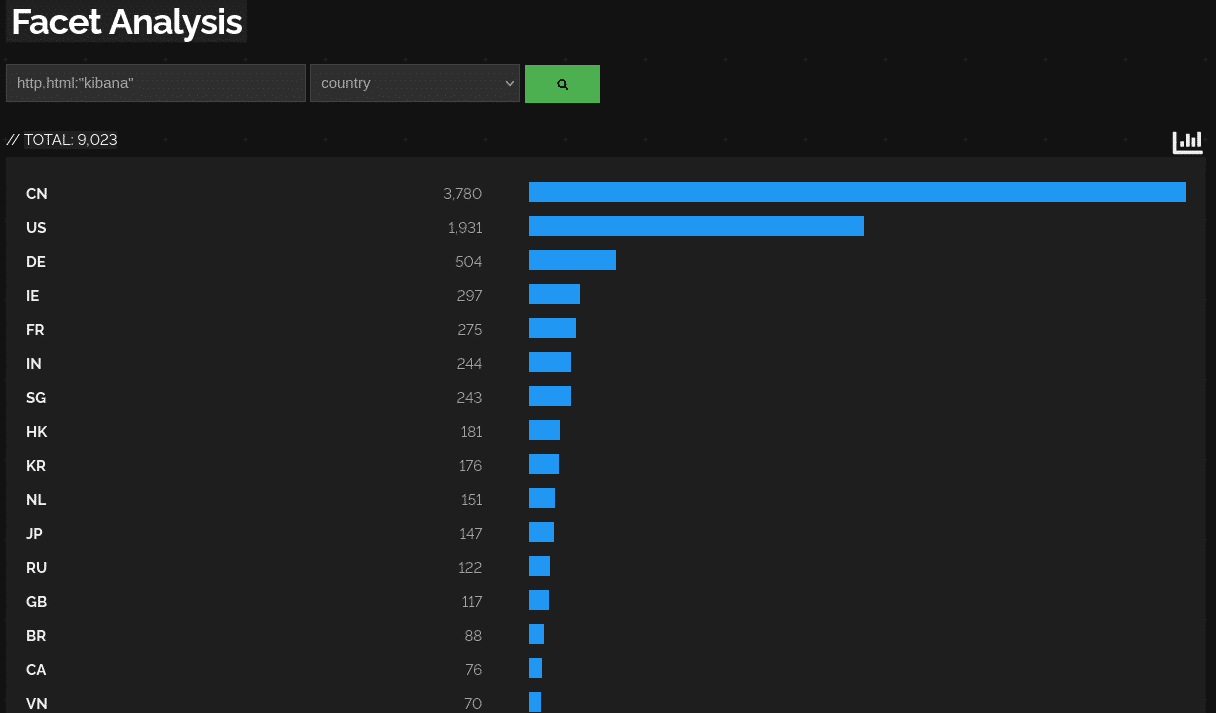
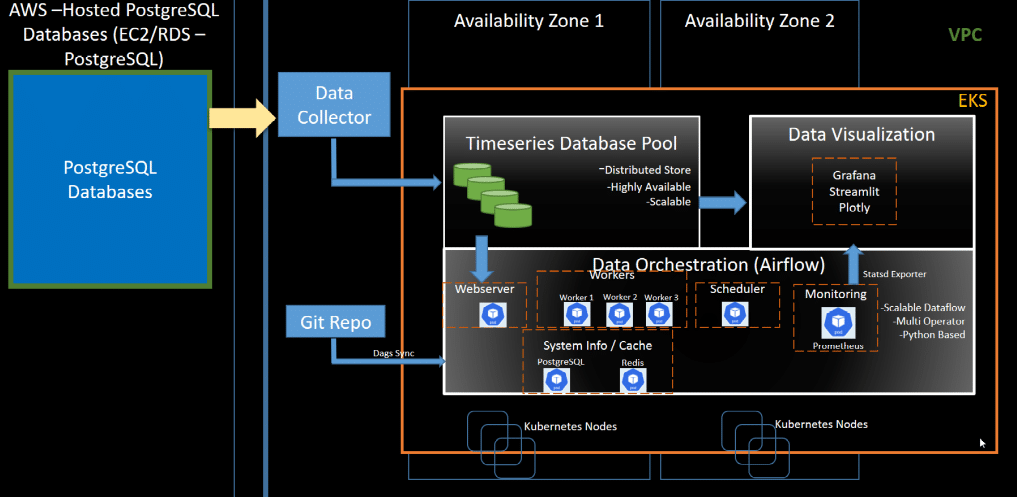
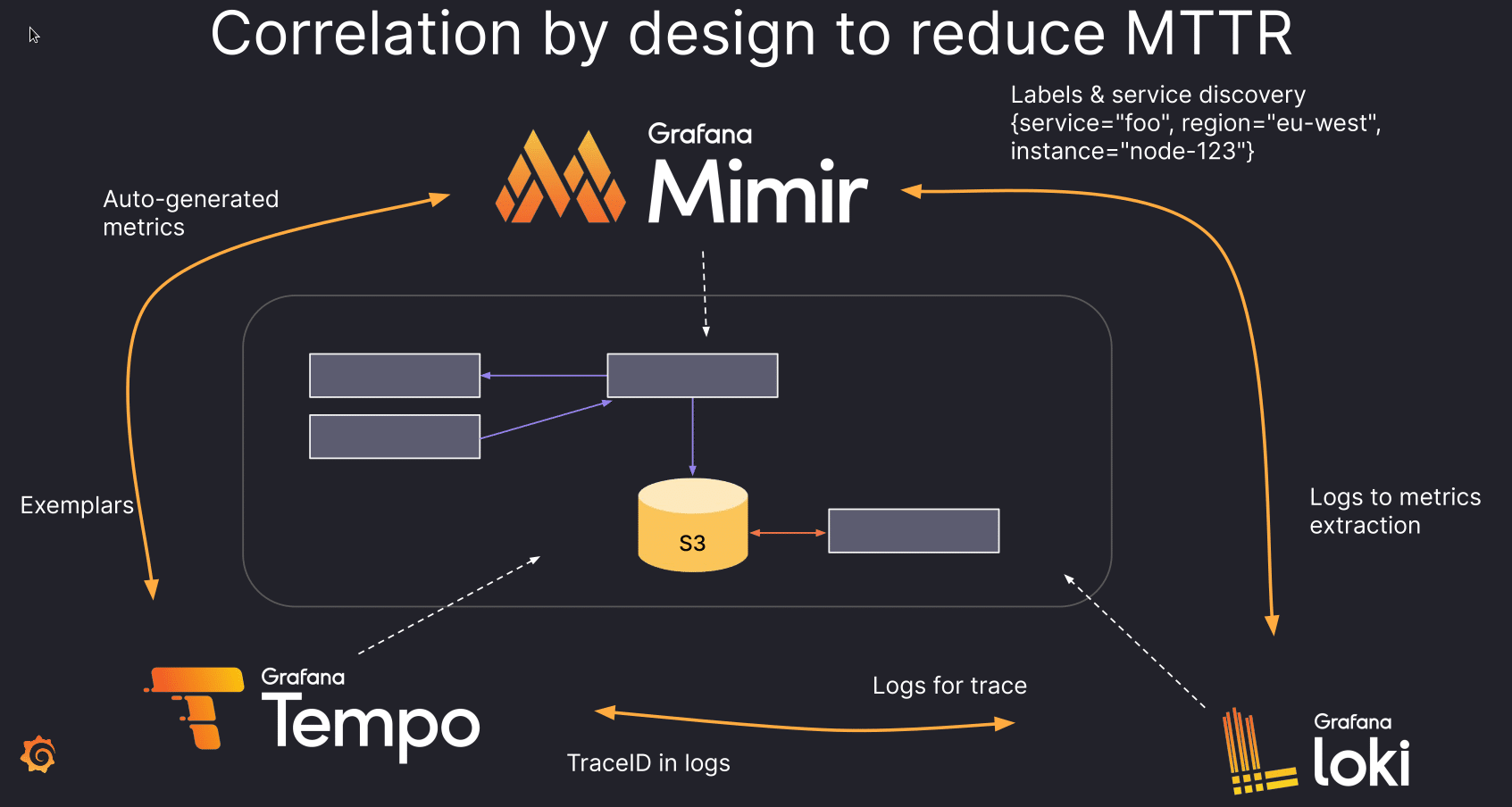
Meanwhile – due to the nature of the open source world – open source solutions are oftentimes highly fragmented requiring a combination of multiple tools to fill in the complete picture. This in turn leads to more complexity due to multiple different underlaying architectures. As an example he brings up the ELK stack (Elasticsearch + Logstash + Kibana) which is just three parts of a more extensive system.
But even though probably nobody likes complexity itself open source solutions still seem to be vastly popular with companies and make up the majority of the observability landscape. In Jonah’s opinion this trend is also “the future of where things are going”.

Licensing
Many of us are used to at least seeing a license every once in a while. MIT, Apache and GPL are common terms to encounter when dealing with open source products.
You yourself might not have to deal with licenses directly but in one way or another you could be affected as well.
Imagine finding a new open source project or code snippets that help you with building your own project. Maybe those fix something that you just could not do or didn’t have time to do. Now licensing is important. Can I use this code? In what way can I use it? Could it backfire? The last question is especially important, according to Jonah.
There seems to be a trend with so called “copyleft licenses”. In this context copyleft effectively means: If you use that code in your own project, you need to open source your own code within that project as well. This is certainly something most companies don’t want to or simply cannot afford to do. After all, companies are still about making money.
But not only do companies have to deal with such issues. Communities surrounding open source projects also have to be careful what they bring into projects. Amongst other disagreements – for example about the current path of a project – licensing is also a contributing factor when it comes to forks popping up.
If you want to know a bit more about a certain fork in the open source observability world that might potentially achieve unified observability, be sure to give Jonah Kowall a few minutes of your time.
The recording and slides of this talk and all other OSMC talks can be found in our Archives. Check it out!
The next OSMC takes place from November 7 – 9, 2023 in Nuremberg. Early Bird tickets are already on sale!