![]() A while back I’ve already looked into the Elastic Stack 5 Beta release and the beats integration. Time flies and the stable release is here. Blerim announced the icingabeat 1.0.0 release last week, and so I was looking into a smooth integration into a Vagrant box here.
A while back I’ve already looked into the Elastic Stack 5 Beta release and the beats integration. Time flies and the stable release is here. Blerim announced the icingabeat 1.0.0 release last week, and so I was looking into a smooth integration into a Vagrant box here.
The provisioner uses Puppet, which Puppet modules could be used here? I’m always looking for actively maintained modules, best by upstream projects which share the joy of automated setups of their tools with their community.
Elastic and Kibana Puppet Module
The Elastic developers started writing their own Puppet module for Kibana 5.x. Previously I’ve used community modules such as puppet-kibana4 or puppet-kibana5. puppet-elasticsearch already supports 5.x for a while, that works like a charm.
Simple example for a low memory Elasticsearch setup:
class { 'elasticsearch':
manage_repo => true,
repo_version => '5.x',
java_install => false,
jvm_options => [
'-Xms256m',
'-Xmx256m'
],
require => Class['java']
} ->
elasticsearch::instance { 'elastic-es':
config => {
'cluster.name' => 'elastic',
'network.host' => '127.0.0.1'
}
}
Note: jvm_options was released in 5.0.0.
Default index pattern
If you do not define any default index pattern, Kibana greets you with a fancy message to do so (and I have to admit – i still need an Elastic Stack training to fully understand why). I wanted to automate that, so that Vagrant box users don’t need to care about it. There are several threads around which describe the deployment by sending a PUT request to the Elasticsearch backend.
I’m using a small script here which waits until Elasticsearch is started. If you don’t do that, the REST API calls will fail later on. This is also required for specifying index patterns and importing dashboards. A Puppet exec timeout won’t do the trick here, because we’ll have to loop and check again if the service is available.
$ cat/usr/local/bin/kibana-setup
#!/bin/bash
ES_URL="http://localhost:9200"
TIMEOUT=300
START=$(date +%s)
echo -e "Restart elasticsearch instance"
systemctl restart elasticsearch-elastic-es
echo -e "Checking whether Elasticsearch is listening at $ES_URL"
until $(curl --output /dev/null --silent $ES_URL); do
NOW=$(date +%s)
REAL_TIMEOUT=$(( START + TIMEOUT ))
if [[ "$NOW" -gt "$REAL_TIMEOUT" ]]; then
echo "Cannot reach Elasticsearch at $ES_URL. Timeout reached."
exit 1
fi
printf '.'
sleep 1
done
If you would want to specify the default index pattern i.e. for an installed filebeat service, you could something like this:
ES_INDEX_URL="$ES_URL/.kibana/index-pattern/filebeat"
ES_DEFAULT_INDEX_URL="$ES_URL/.kibana/config/5.2.2" #hardcoded program version
curl -XPUT $ES_INDEX_URL -d '{ "title":"filebeat", "timeFieldName":"@timestamp" }'
curl -XPUT $ES_DEFAULT_INDEX_URL -d '{ "defaultIndex":"filebeat" }'
One problem arises: The configuration is stored by Kibana program version. There is no symlink like ‚latest‘, but you’ll need to specify ‚.kibana/config/5.2.2‘ to make it work. There is a certain requirement for pinning the Kibana version, or finding a programatic way to automatically determine the version.
Kibana Version in Puppet
Fortunately the Puppet module allows for specifying a version. Turns out, the class validation doesn’t support package revision known from rpm („5.2.2-1“). Open source is awesome – you manage to patch it, apply tests and after review your contributed patch gets merged upstream.
Example for Kibana with a pinned package version:
$kibanaVersion = '5.2.2'
class { 'kibana':
ensure => "$kibanaVersion-1",
config => {
'server.port' => 5601,
'server.host' => '0.0.0.0',
'kibana.index' => '.kibana',
'kibana.defaultAppId' => 'discover',
'logging.silent' => false,
'logging.quiet' => false,
'logging.verbose' => false,
'logging.events' => "{ log: ['info', 'warning', 'error', 'fatal'], response: '*', error: '*' }",
'elasticsearch.requestTimeout' => 500000,
},
require => Class['java']
}
->
file { 'kibana-setup':
name => '/usr/local/bin/kibana-setup',
owner => root,
group => root,
mode => '0755',
source => "puppet:////vagrant/files/usr/local/bin/kibana-setup",
}
->
exec { 'finish-kibana-setup':
path => '/bin:/usr/bin:/sbin:/usr/sbin',
command => "/usr/local/bin/kibana-setup",
timeout => 3600
}
Icingabeat integration
That’s fairly easy, just install the rpm and put a slightly modified icingabeat.yml there.
$icingabeatVersion = '1.0.0'
yum::install { 'icingabeat':
ensure => present,
source => "https://github.com/Icinga/icingabeat/releases/download/v$icingabeatVersion/icingabeat-$icingabeatVersion-x86_64.rpm"
}->
file { '/etc/icingabeat/icingabeat.yml':
source => 'puppet:////vagrant/files/etc/icingabeat/icingabeat.yml',
}->
service { 'icingabeat':
ensure => running
}
I’ve also found the puppet-archive module from Voxpupuli which allows to download and extract the required Kibana dashboards from icingabeat. The import then requires that Elasticsearch is up and running (referencing the kibana setup script again). You’ll notice the reference to the pinned Kibana version for setting the default index pattern via exec resource.
# https://github.com/icinga/icingabeat#dashboards
archive { '/tmp/icingabeat-dashboards.zip':
ensure => present,
extract => true,
extract_path => '/tmp',
source => "https://github.com/Icinga/icingabeat/releases/download/v$icingabeatVersion/icingabeat-dashboards-$icingabeatVersion.zip",
checksum => 'b6de2adf2f10b77bd4e7f9a7fab36b44ed92fa03',
checksum_type => 'sha1',
creates => "/tmp/icingabeat-dashboards-$icingabeatVersion",
cleanup => true,
require => Package['unzip']
}->
exec { 'icingabeat-kibana-dashboards':
path => '/bin:/usr/bin:/sbin:/usr/sbin',
command => "/usr/share/icingabeat/scripts/import_dashboards -dir /tmp/icingabeat-dashboards-$icingabeatVersion -es http://127.0.0.1:9200",
require => Exec['finish-kibana-setup']
}->
exec { 'icingabeat-kibana-default-index-pattern':
path => '/bin:/usr/bin:/sbin:/usr/sbin',
command => "curl -XPUT http://127.0.0.1:9200/.kibana/config/$kibanaVersion -d '{ \"defaultIndex\":\"icingabeat-*\" }'",
}
The Puppet code is the first working draft, I plan to refactor the upstream code. Look how fancy 🙂
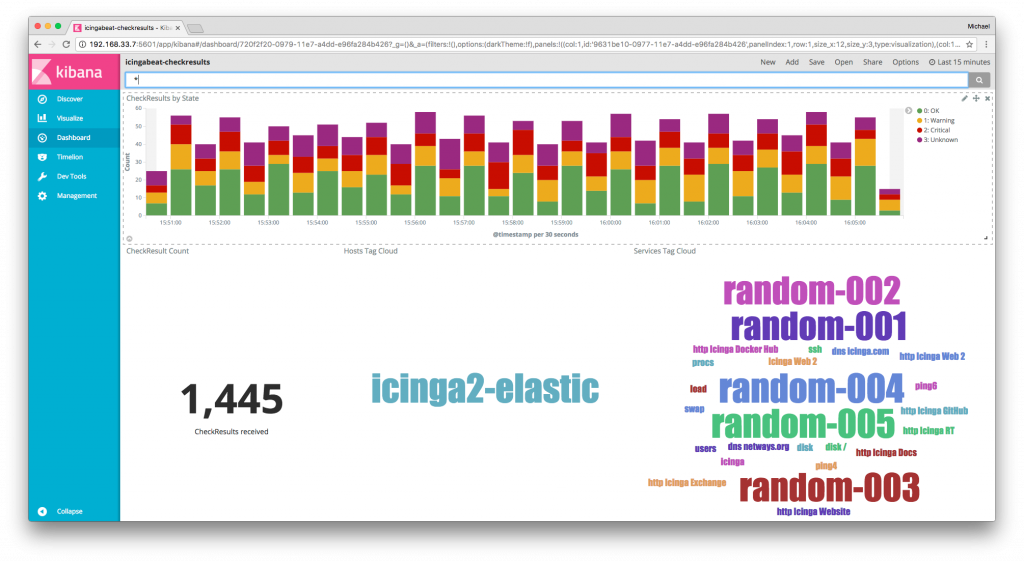
Conclusion
Managing your Elastic Stack setup with Puppet really has become a breeze. I haven’t tackled the many plugins and dashboards available, there’s so much more to explore. Once you’ve integrated icingabeat into your devops stack, how would you build your own dashboards to correlate operations maintenance with Icinga alerts? 🙂
If you’re interested in learning more about Elastic and the awesome Beats integrations, make sure to join OSDC 2017. Monica Sarbu joins us with her talk on „Collecting the right data to monitor your infrastructure“.
PS: Test-drive the integration, finished today 🙂
Test-drive #icingabeat inside the #icinga vagrant box 'icinga2x-elastic' 🙂 https://t.co/DJuThyy6uu #elastic pic.twitter.com/qH1Kt8NB1l
— Icinga (@icinga) March 30, 2017

 „Machine Learning“ ein Kibana Feature, das aus „Prelert“ entstanden ist, nur für Nutzer von X-Pack erhältlich sein. Ob „Canvas“, ein Feature, mit dem Reports und Präsentationen aus Kibana heraus erstellt werden können, frei verfügbar sein wird, wird noch entschieden. Auf jeden Fall würde das vielen Usern sehr weiterhelfen, nach dem, was wir an Nachfragen erhalten.
„Machine Learning“ ein Kibana Feature, das aus „Prelert“ entstanden ist, nur für Nutzer von X-Pack erhältlich sein. Ob „Canvas“, ein Feature, mit dem Reports und Präsentationen aus Kibana heraus erstellt werden können, frei verfügbar sein wird, wird noch entschieden. Auf jeden Fall würde das vielen Usern sehr weiterhelfen, nach dem, was wir an Nachfragen erhalten.

 gfall eines Knotens der restliche Cluster beginnt, Shards und ihre Repliken (Daten in Elasticsearch werden in Indices aufgeteilt, die wiederum in Shards unterteilt werden, die ihrerseits in Repliken kopiert werden – so erreicht Elasticsearch mit beliebigen Daten Lastverteilung und Redundanz) umzuverteilen, um den „Verlust“ des Knotens auszugleichen. Dazu werden die Daten, die auf diesem Knoten waren, sofort auf andere Knoten kopiert – das ist möglich weil Elasticsearch per default jeden Datensatz mindest zweimal vorhält. Nachdem die Redundanz wieder hergestellt ist, werden die Shards und Repliken nochmal verschoben, jedoch langsamer, um die Last im Cluster gleichmässig zu verteilen.
gfall eines Knotens der restliche Cluster beginnt, Shards und ihre Repliken (Daten in Elasticsearch werden in Indices aufgeteilt, die wiederum in Shards unterteilt werden, die ihrerseits in Repliken kopiert werden – so erreicht Elasticsearch mit beliebigen Daten Lastverteilung und Redundanz) umzuverteilen, um den „Verlust“ des Knotens auszugleichen. Dazu werden die Daten, die auf diesem Knoten waren, sofort auf andere Knoten kopiert – das ist möglich weil Elasticsearch per default jeden Datensatz mindest zweimal vorhält. Nachdem die Redundanz wieder hergestellt ist, werden die Shards und Repliken nochmal verschoben, jedoch langsamer, um die Last im Cluster gleichmässig zu verteilen.
















