Wer nach einer Open Source Monitoring Lösung zur System- und Netzwerküberwachung sucht, kommt an Icinga (auch als Icinga 2 bekannt) nicht vorbei. Es hilft dir dabei Verfügbarkeit, Leistung und Trends der gesamten IT-Infrastruktur zu überwachen. Dank individualisierbarer Benachrichtigungseinstellungen kommen die Informationen immer genau an der gewünschten Stelle an.
Mit diesem Guide wollen wir dir dabei helfen, einen leichten Einstieg ins Icinga Monitoring zu finden und Icinga, Icinga DB und Redis erfolgreich installierst.
In diesem Guide spielt die IDO keine Rolle mehr, da diese von Icinga DB als Datenbackend abgelöst wurde. Die neue Komponente sorgt für eine bessere Performance und Skalierbarkeit von Icinga.
Voraussetzungen für die Icinga und Icinga DB Installation
Damit dieser Guide erfolgreich umgesetzt werden kann, gibt es einige wichtige Voraussetzungen:
- Einen Ubuntu 20.04 / 22.04 Server mit mindestens 2 GB RAM und 20 GB freiem Speicherplatz
- Der sudo – Benutzer ist auf dem Server eingerichtet und du hast das Recht, ihn zu nutzen
- Zugriff auf eine SQL-Datenbank (in diesem Guide wird MariaDB verwendet)
- Die aktuellste PHP-Version ist auf dem Server installiert
- Eine Internetverbindung auf den Server
- Optional: Ein Webserver (Apache, Nginx, etc.) ist auf dem Server installiert (als Teil des LAMP-Stack)
Du kannst hinter alle diese Punkte einen Haken setzen? Dann legen wir los!
Anmerkung: Alle nachfolgende Schritte werden als root-User durchgeführt. Überprüfe, ob du den richtigen Benutzer verwendest!
Schritt 1: Icinga Repository hinzufügen
Um die aktuelle Version von Icinga zu installieren, wird das offizielle Icinga-Repository zu unserem System hinzugefügt. Dazu führst du in deinem Terminal die folgenden Befehle aus:
apt update
apt -y install apt-transport-https wget gnupg
wget -O - https://packages.icinga.com/icinga.key | gpg --dearmor -o /usr/share/keyrings/icinga-archive-keyring.gpg
. /etc/os-release; if [ ! -z ${UBUNTU_CODENAME+x} ]; then DIST="${UBUNTU_CODENAME}"; else DIST="$(lsb_release -c| awk '{print $2}')"; fi; \
echo "deb [signed-by=/usr/share/keyrings/icinga-archive-keyring.gpg] https://packages.icinga.com/ubuntu icinga-${DIST} main" > \
/etc/apt/sources.list.d/${DIST}-icinga.list
echo "deb-src [signed-by=/usr/share/keyrings/icinga-archive-keyring.gpg] https://packages.icinga.com/ubuntu icinga-${DIST} main" >> \
/etc/apt/sources.list.d/${DIST}-icinga.list
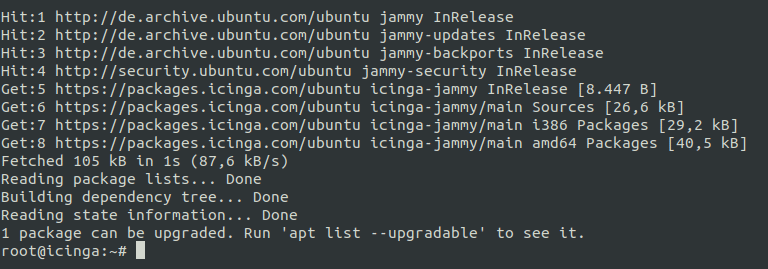
apt update
Sobald dieser Befehlsblock erfolgreich durchgelaufen ist, siehst du in deinem Terminal, dass die neuen Repos nun in deiner Liste zu finden sind. Es sollte in etwa so aussehen:
Schritt 2: Icinga-Paket auf Ubuntu 20.04 oder Ubuntu 22.04 installieren
Da du nun Zugriff auf das Icinga-Repository hast, kannst du direkt damit weiter machen und das Icinga Paket installieren. Dafür nutzt du:
apt install -y icinga2
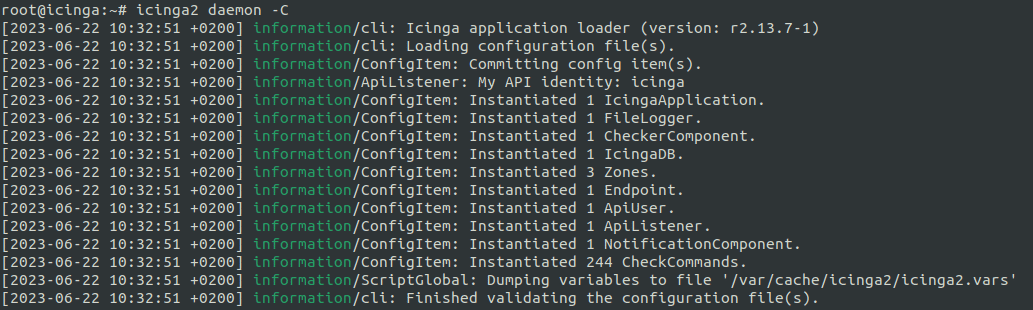
Dieses Paket ist die Basis der gesamten Icinga 2 Monitoring Installation. Um zu überprüfen, ob die Installation erfolgreich war, nutzt du
icinga2 daemon -C
Mithilfe dieses Befehls kannst zukünftige Konfigurationsanpassungen mit einem Terminalbefehl überprüfen.
Schritt 3: Aktivieren der Icinga API und Installieren der Monitoring Plugins
Ein Monitoringsystem ist nur so gut wie die Daten, die es sammelt und die Checks, die ausgeführt werden.
Für moderne, aus Nagios hervorgegangene Open Source Monitoring Systeme haben sich die bereits am Anfang angesprochenen Monitoring Plugins etabliert. Diese installierst du im nächsten Schritt.
Damit kannst du direkt nach Abschluss dieses Icinga Installationsguides die ersten Checks anlegen und mit deinem System Monitoring oder Netzwerk Monitoring starten. Dafür nutzt du im Terminal den folgenden Befehl:
apt install monitoring-plugins
Um die Ergebnisse der Check Plugins abzurufen oder mit Icinga zu interagieren, muss die Icinga API eingerichtet werden. Das machst du ganz einfach mit diesen beiden Befehlen:
icinga2 api setup systemctl restart icinga2
Damit legst du in der Konfigurationsdatei /etc/icinga2/conf.d/api-users.conf einen API-User (inkl. zufallsgeneriertem Passwort) an.
(Die hier erzeugten Zugangsdaten benötigst du im weiteren Verlauf bei der Einrichtung von Icinga Web. Du wirst im entsprechenden Schritt noch einmal darauf hingewiesen!)
Falls du bestimmte Vorgaben erfüllen musst oder generell mehr über die Icinga API erfahren willst, lege ich dir entsprechende Seite in den Icinga Docs ans Herz.
Weiter geht es mit der Einrichtung von Icinga DB.
Schritt 4: Icinga DB einrichten
Icinga DB ist keine, wie der Name vielleicht vermuten lässt, eigenständige Datenbank.
Vielmehr handelt es sich hierbei um eine Sammlung von Komponenten zur Veröffentlichung, Synchronisierung und Visualisierung von Überwachungsdaten im Icinga-Ökosystem. Dazu gehören Redis, das IcingaDB-Feature des Icinga Core und der Icinga DB-Daemon.
Schritt 4.1: Redis Server installieren
Um Icinga DB zu nutzen, benötigst du einen Redis Server. Für einen reibungslosen Installations- und Konfigurationsprozess bietet das Icinga Team ein eigenes Redis-Paket an, das speziell auf Icinga zugeschnitten ist.
icindadb-redis umfasst deshalb eine aktuelle Version von Redis und kommt out of the box mit Anpassungen der Freigabe auf Port 6380 statt dem sonst für Redis üblichen Port 6379.
Das Paket installierst du mit:
apt install icingadb-redis
Hinweis: Der Redis Server kann grundsätzlich überall in deiner Icinga Umgebung installiert werden. Es ist jedoch sinnvoll, diesen auf dem zentralen Icinga-Node zu installieren, um die Latenz so niedrig wie möglich zu halten.
Ein bereits vorhandener und selbst konfigurierter Redis Server kann ebenso verwendet werden. Hier sind jedoch entsprechende Anpassungen notwendig, weshalb die Nutzung des entsprechenden Icinga-Pakets empfohlen wird.
Schritt 4.2: Aktivieren von Redis
Die Installation von icingadb-redis installiert automatisch alle systemd Dateien, die Icinga DB Redis braucht. Der Service kann also direkt aktiviert und gestartet werden:
systemctl enable --now icingadb-redis-server
Standardmäßig lauscht icingadb-redis nur auf 127.0.0.1, also deinem localhost. Wenn Icinga Web 2 oder Icinga 2 auf einer anderen Node laufen als Redis, dann muss das in der Konfigurationsdatei
/etc/icingadb-redis/icingadb-redis.conf
angepasst werden.
Auch wenn in diesem Guide alle Schritte auf einer Icinga-Node durchgeführt werden, wird die Konfigurationsdatei so angepasst, dass das Aufsetzen weiterer Nodes in der Zukunft kein Problem darstellen.
Dafür sind innerhalb der Konfigurationsdatei zwei kleine Anpassungen notwendig:
- protected-mode von yes auf no
- bind von 127.0.0.1 auf 0.0.0.0 –> Dadurch können alle Interfaces auf Redis zugreifen
Um die Änderungen zu aktivieren, muss der Service neu gestartet werden:
systemctl restart icingadb-redis
Damit Icinga über Icinga DB später Daten an Redis weitergibt, muss das entsprechende Feature aktiviert und Icinga anschließend neu gestartet werden:
icinga2 feature enable icingadb systemctl restart icinga2
Sicherheitshinweis:
Redis hat standardmäßig KEINE Authentifizierung aktiviert!
Mit der Änderung von bind auf 0.0.0.0 wird dringend, um unbefugten Zugriff zu verhindern, empfohlen, einige Sicherheitsmaßnahmen durchzuführen. Dazu gehören: Einrichten eines Passworts, Aufstellen von Firewall-Regeln oder Einrichten von TLS.
Zur einfacheren Installation wird in diesem Guide jedoch auf diese Schritte verzichtet! Diese Anpassungen lassen sich ebenfalls nachträglich durchführen.
Schritt 4.3: Installieren von Icinga DB und einrichten der Datenbank
Nachdem im gerade abgeschlossenen Schritt die Schnittstelle von Icinga 2 zu Icinga DB aktiviert wurde, wird nun Icinga DB selbst installiert:
apt-get install icingadb
Damit das gerade installierte Paket die verarbeiteten Daten auch speichern kann, muss eine Datenbank für Icinga DB angelegt und Zugriff dazu gewährt werden. (In diesem Guide wird MariaDB 10.6.12 verwendet. Die Einrichtung von MySQL ist mit den gleichen Befehlen möglich. Nutzt du PostgreSQL findest du die entsprechenden Befehle in den offiziellen Icinga Docs.)
mysql -u root -p CREATE DATABASE icingadb; CREATE USER 'icingadb'@'localhost' IDENTIFIED BY 'SAFEPASSWORDINHERE'; GRANT ALL ON icingadb.* TO 'icingadb'@'localhost';
Damit hast du die Datenbank und den Datenbank-Nutzer erfolgreich angelegt. Icinga DB stellt zudem ein Datenbankschema zur Verfügung, dass nun importiert wird:
mysql -u root -p icingadb </usr/share/icingadb/schema/mysql/schema.sql
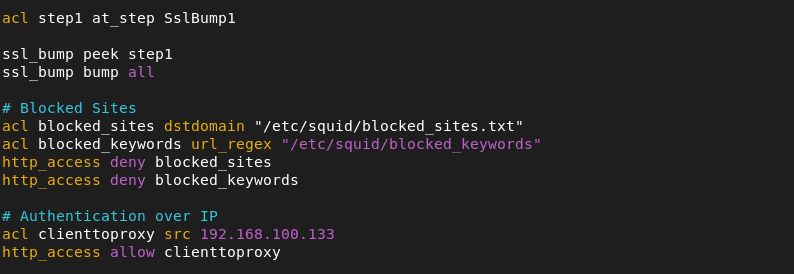
Schritt 4.3: Zugriffsberechtigungen anpassen
Während der Installation von Icinga DB wird unter /etc/icingadb/config.yml eine Konfigurationsdatei angelegt, die mit Standardwerten gefüllt ist. Damit die Verbindung von Icinga DB zu Redis und MariaDB erfolgreich stattfinden kann, müssen diese Werte überprüft und gegebenenfalls angepasst werden.
Öffne also den Pfad mit einem Texteditor deiner Wahl und passe die folgenden Parameter gegebenenfalls an.
Für die Datenbank:
host mit dem entsprechenden Hostname/Host-IP deiner Datenbank, database mit dem Namen deiner Datenbank (in diesem Guide icingadb), user mit dem Namen deines Datenbanknutzers und password mit dem Passwort, dass du für deine Datenbank vergeben hast.
Für Redis:
host mit dem entsprechenden Hostname/Host-IP deiner Redis Instanz. Wenn du während der Installation deines Redis-Servers den port geändert oder ein password gesetzt hast, musst du dies hier ebenfalls eintragen.
Sobald diese Änderungen abgeschlossen sind, kann der Icinga DB Service aktiviert werden:
systemctl enable --now icingadb
Schritt 5: Icinga Node Wizard ausführen
Nachdem die Grundkomponenten für die Nutzung von Icinga installiert und konfiguriert wurden, muss noch er Node Wizard ausgeführt werden. Dieses interaktive Skript hilft dir dabei, Zonen einzustellen und die Endpunkte deines Icinga Monitoring festzulegen.
Dafür gibst du im Terminal diesen Befehl ein:
icinga2 node wizard
Da hier einige wichtige Einstellungen vorgenommen werden, hier eine Übersicht der einzelnen Punkte:
- Is this agent/satellite setup? –> Hier ‘n’ eingeben und mit Enter bestätigen
- Specifiy common name (FQDN of your master) –> Nichts eingeben und mit Enter bestätigen
- Master zone name –> Nichts eingeben und mit Enter bestätigen
- Specify additional global zones –> Nichts eingeben und mit Enter bestätigen
- Specify API bind host/port –> Nichts eingeben und mit Enter bestätigen
- Bind Host –> Nichts eingeben und mit Enter bestätigen
- Bind Port –> Nichts eingeben und mit Enter bestätigen
- Disable inclusion of conf.d directory –> Nichts eingeben und mit Enter bestätigen

Im Anschluss verifizierst du die getätigte Konfiguration und lädst Icinga 2 neu:
icinga2 daemon -C systemctl reload icinga2
Damit hast alle wichtigen Schritte zur Icinga und Icinga DB abgeschlossen!
Wie gehts es nun weiter?
Herzlichen Glückwunsch, du hast erfolgreich ein lokales Icinga installiert und konfiguriert! Damit könntest du nun direkt loslegen und über die Icinga2 API deine ersten Objekte anlegen, Actions triggern oder Templates bauen. Welche API-Calls dir dafür zur Verfügung stehen, kannst du übersichtlich in den Icinga Docs nachlesen.
Grundsätzlich ist die Icinga Installation nun einsatzbereit. Damit eine Open Source Monitoring Lösung wie Icinga aber produktiv genutzt werden kann, müssen die gesammelten Daten noch visualisiert werden.
Dabei helfen Icinga Web und Icinga DB Web. Wie diesen beiden Tools installiert und mit der hier aufgesetzten Basis verbunden werden erfährst du im Installationsguide zu Icinga Web und Icinga DB Web auf Ubuntu 20.04 / 22.04.













 Name: Marc Rupprecht
Name: Marc Rupprecht