The Icinga configuration format was designed to be easy to use for novice users while at the same time providing more advanced features to expert users. At first glance it might look like a simple key-value configuration format:
object Host "example.icinga.com" {
import "generic-host"
address = "203.0.113.17"
address6 = "2001:db8::17"
}
However, it features quite a bit of functionality that elevates it to the level of scripting languages: variables, functions, control flow (if, for, while) and a whole lot more.
Icinga’s scripting language is used in several places:
- configuration files
- API filter expressions
- auto-generated files used for keeping track of modified attributes
In this post I’d like to show how some of the config machinery works internally.
The vast majority of the config compiler is contained in the lib/config directory. It weighs in at about 4.5% of the entire code base (3059 out of 68851 lines of code as of July 2018). The compiler is made up of three major parts:
Lexer
The lexer (lib/config/config_lexer.ll, based on flex) takes the configuration source code in text form and breaks it up into tokens. In doing so the lexer recognizes all the basic building blocks that make up the language:
- keywords (e.g. “object”, “for”, “break”) and operators (e.g. >, ==, in)
- identifiers
- literals (numbers, strings, booleans)
- comments
However, it has no understanding of how these tokens fit together syntactically. For that it forwards them to the parser. All in all the lexer is actually quite boring.
Parser/AST
The parser (lib/config/config_parser.yy, based on GNU Bison) takes the tokens from the lexer and tries to figure out whether they represent a valid program. In order to do so it has production rules which define the language’s syntax. As an example here’s one of those rules for “for” loops:
| T_FOR '(' identifier T_FOLLOWS identifier T_IN rterm ')'
{
BeginFlowControlBlock(context, FlowControlContinue | FlowControlBreak, true);
}
rterm_scope_require_side_effect
{
EndFlowControlBlock(context);
$$ = new ForExpression(*$3, *$5, std::unique_ptr($7), std::unique_ptr($10), @$);
delete $3;
delete $5;
}
Here’s a list of some of the terms used in the production rule example:
| Symbol | Description |
|---|---|
| T_FOR | Literal text “for”. |
| identifier | A valid identifier |
| T_FOLLOWS | Literal text “=>”. |
| T_IN | Literal text “in”. |
| BeginFlowControlBlock, EndFlowControlBlock | These functions enable the use of certain flow control statements which would otherwise not be allowed in code blocks. In this case the “continue” and “break” keywords can be used in the loop’s body. |
| rterm_scope_require_side_effect | A code block for which Icinga can’t prove that the last statement doesn’t modify the program state. An example for a side-effect-free code block would be { 3 } because Icinga can prove that executing its last statement has no effect. |
After matching the lexer tokens against its production rules the parser continues by constructing an abstract syntax tree (AST). The AST is an executable representation of the script’s code. Each node in the tree corresponds to an operation which Icinga can perform (e.g. “multiply two numbers”, “create an object”, “retrieve a variable’s value”). Here’s an example of an AST for the expression “2 + 3 * 5”:

Note how the parser supports operator precedence by placing the AddExpression AST node on top of the MultiplyExpression node.
Icinga’s AST supports a total of 52 different AST node types. Here are some of the more interesting ones:
| Node Type | Description |
|---|---|
| ArrayExpression | An array definition, e.g. [ varName, "3", true ]. Its interior values are also AST nodes. |
| BreakpointExpression | Spawns the script debugger console if Icinga is started with the -X command-line option. |
| ImportExpression | Corresponds to the import keyword which can be used to import another object or template. |
| LogicalOrExpression | Implements the || operator. This is one of the AST node types which don’t necessarily evaluate all of its interior AST nodes, e.g. for true || func() the function call never happens. |
| SetExpression | This is essentially the = operator in its various forms, e.g. host_name = "localhost" |
On their own the AST nodes just describe the semantical structure of the script. They don’t actually do anything in terms of performing any real actions.
VM
Icinga contains a virtual machine (in the language sense) for executing AST expressions (mostly lib/config/expression.cpp and lib/config/vmops.hpp). Given a reference to an AST node – such as root node from the example in the previous section – it attempts to evaluate that node. What that means exactly depends on the kind of AST node:
The LiteralExpression class represents bare values (e.g. strings, numbers and boolean literals). Evaluating a LiteralExpression AST node merely yields the value that is stored inside of that node, i.e. no calculation of any kind takes place. On the other hand, the AddExpression and MultiplyExpression AST nodes each have references to two other AST nodes. These are the operands which are used when asking an AddExpression or MultiplyExpression AST node for “their” value.
Some AST nodes require additional context in order to run. For example a script function needs a way to access its arguments. The VM provides these – and a way to store local variables for the duration of the script’s execution – through an instance of the StackFrame (lib/base/scriptframe.hpp) class.
Future Considerations
All in all the Icinga scripting language is actually fairly simple – at least when compared to other more sophisticated scripting engines like V8. In particular Icinga does not implement any kind of optimization.
A first step would be to get rid of the AST and implement a bytecode interpreter. This would most likely result in a significant performance boost – because it allows us to use the CPU cache much more effectively than with thousands, if not hundreds of thousands AST nodes scattered around the address space. It would also decrease memory usage both directly and indirectly by avoiding memory fragmentation.
However, for now the config compiler seems to be doing its job just fine and is probably one of the most solid parts of the Icinga codebase.
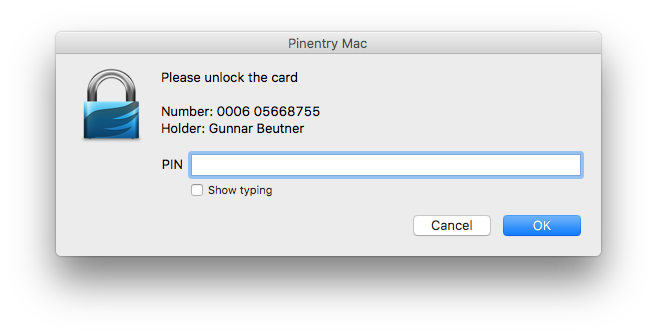
 Most system administrators know how to use key-based authentication with SSH. Some of the more obvious benefits include agent forwarding (i.e. being able to use your SSH key on a remote system) and not having to remember passwords. There are, however, a few issues with having your SSH key on a general-purpose computer: Malware can obtain an unencrypted copy of your private SSH key fairly easily. Also, while migrating your key to another system is fairly easy it’s virtually impossible to securely use your SSH key on another untrusted system (e.g. at a customer).
Most system administrators know how to use key-based authentication with SSH. Some of the more obvious benefits include agent forwarding (i.e. being able to use your SSH key on a remote system) and not having to remember passwords. There are, however, a few issues with having your SSH key on a general-purpose computer: Malware can obtain an unencrypted copy of your private SSH key fairly easily. Also, while migrating your key to another system is fairly easy it’s virtually impossible to securely use your SSH key on another untrusted system (e.g. at a customer).