Wieder einmal PostgreSQL Schlung (Fundamentals und Advanced) durchgeführt.
Wieder einmal wurde nach GUIs gefragt.
Wieder einmal haben wir uns dann letztlich doch fast auf psql beschränkt.
Warum ist das so?
GUI vs. TUI – the eternal battle
GUIs werden i. A. als “benutzerfreundlicher” dargestellt.
Ich persönlich wiederum finde es ganz schrecklich, dauernd zur Maus greifen zu müssen, um irgendeine Aktion auszulösen, für die die Entwickler keinen oder einen grauenhaften Shortcut konfiguriert haben… für mich sind GUIs also eher weniger benutzerfreundlich.
Mir ist auch klar, dass es beileibe nicht jedem Menschen so geht, und die Gewöhnung spielt dabei sicher auch eine enorme Rolle.
“The usual suspects”: die üblicherweise genannten Gründe pro GUI/TUI
GUI:
- intuitiver zu bedienen
- “gewohnte” Optik
- bessere Übersicht über Ergebnisse von Queries
TUI:
- steht vom Funktionsumfang dem GUI kaum nach
- funktioniert auch bei langsamer Verbindung (“Zug”)
- kann gescriptet werden
Es gibt aber einige durchaus schwerwiegende Gründe, warum ich bei Trainings so einen großen Wert auf psql lege.
“The killer arguments”: warum psql elementar ist
Die Lernschwelle ist bei GUIs unnötig hoch
- Jedes GUI sieht letztlich (ein wenig) anders aus und es gibt einfach zu viele
- Um eine erste Verbindung herzustellen, muss im GUI erst ein Server definiert werden, mit jeder Menge Parametern, u.a. einer Netzwerkverbindung
- dafür muss aber erst ein Konfigurationsparameter (
listen_addresses=) gesetzt werden, was wiederum erst deutlich nach dem ersten “Reinschnuppern” behandelt wird… - Im Terminal hingegen (wo ich ja gerade den DB-Server installiert habe) komme ich per
psqldirekt an die DB (wenn ich der OS-Userpostgresbin…)
- dafür muss aber erst ein Konfigurationsparameter (
- Objekte anschauen (“Erste Schritte”):
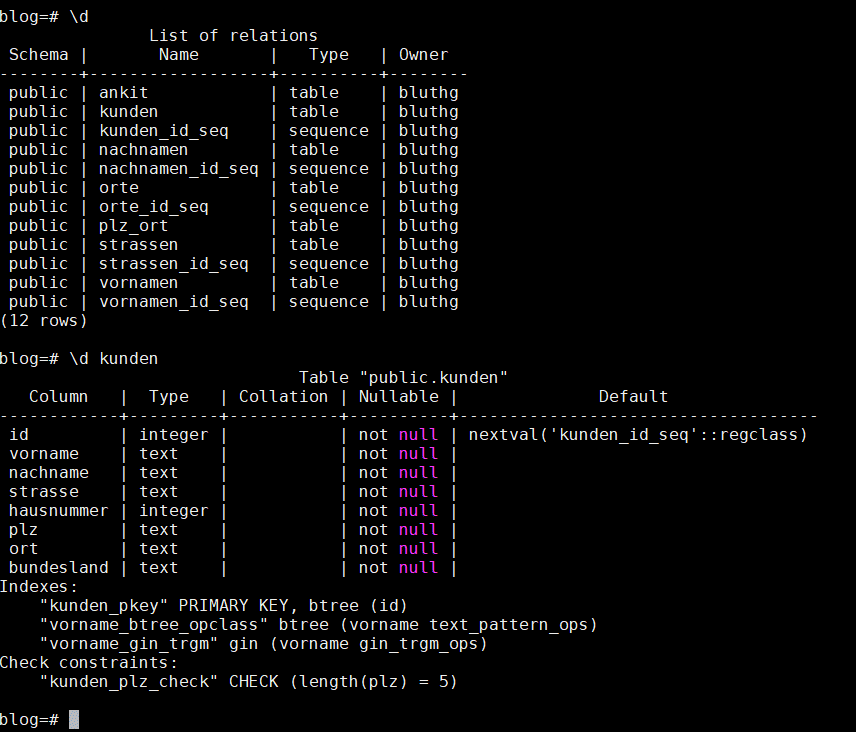
- TUI: nach Eingabe von
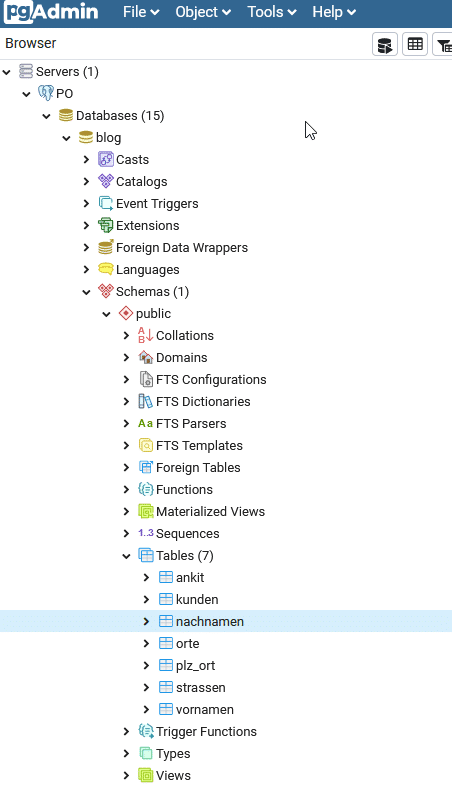
psqlkann ich einfach z.B.\dteingeben und bekomme alle Tabellen gelistet,\d nachnamenzeigt mir instant die Tabellenstruktur, dazu Indexe, Primär-/Fremdschlüssel etc. an - in allen GUIs muss ich dafür erst durch einen Baum klicken, in pgAdmin4 z.B. Servergruppe -> Server -> Datenbank -> Schemas -> ‘public’ -> Tabellen
- TUI: nach Eingabe von
Die (online-)Trainings-VMs sind nur per ssh und Webinterface erreichbar
- um da per GUI dranzukommen, müssten also die Teilnehmer erstmal Software auf ihren (privaten oder dienstlichen) PCs installieren…
Viel entscheidender ist aber m.E.:
psql ist für den PostgreSQL-DBA, was vi für den U\*\*X-Admin ist:
- auf jeder PostgreSQL-Maschine verfügbar
- minimalistisch, aber gleichzeitig unglaublich leistungsfähig
- ich muss das sowieso zu nennenswerten Teilen beherrschen, z.B.
- für den Fall, dass mir die Firewall einen Streich spielt
- wenn ich mal als Superuser in die DB will/muss (
max_connections=ausgeschöpft) - um Dinge zu scripten
Wenn mir jemand erzählt, er oder sie sei UNIX-Admin, dann aber einen nano benutzt, bin ich sofort (zurückhaltend ausgedrückt) skeptisch.
Ähnlich ist es mit psql. Ich muss (als DBA) sowieso wissen, wie ich damit z.B. Objekte anzeigen, DDL einspielen, ggfs. mal eine Stored procedure umschreiben etc. pp. kann. Wenn ich die Software also sowieso (halbwegs) beherrschen muss, kann ich sie doch auch gleich benutzen? Ich sehe nur wenige Szenarien, in denen ein(e) DBA von einem GUI profitieren würde.
Ein(e) AnalystIn hingegen wird die DB wahrscheinlich eher direkt an ein Reporting-Tool oder M$ Excel anbinden wollen.
Bleibt der/die (SQL-) EntwicklerIn. Ja, fair enough, da sehe auch ich gewissen Charme (üblicherweise F5 drücken, um das SQL im Fenster (erneut) laufen zu lassen). Auf der anderen Seite ist derselbe Effekt in psql durch Eingabe von \e zu erreichen, und da kommt ein vi. Der ist ja bekanntlich minimalistisch, aber… 😉
Und ob man DDL jetzt per GUI erzeugen sollte, darüber scheiden sich ja auch die Geister… IMHO eher nicht.
Fazit:
“I never leave the house without it!”
psql ist der vi(m) der PostgreSQL-Welt. Unfassbar flexibel und leistungsfähig, immer verfügbar und dadurch absolutes “Pflichtprogramm”.
P.S.
Ich habe mal jemanden kennengelernt, der eine U\*\*X-Consulting-Firma betrieb und lt. eigener Aussage nur Menschen anstellte, die den ed beherrschen. So weit würde ich dann auch nicht gehen… 😉
P.P.S.
Vielleicht hat die Abneigung gegen TUIs was mit Oracles SQL*Plus (TM) zu tun? Wäre absolut nachvollziehbar, das fasse ich auch nur mit der Kneifzange an…