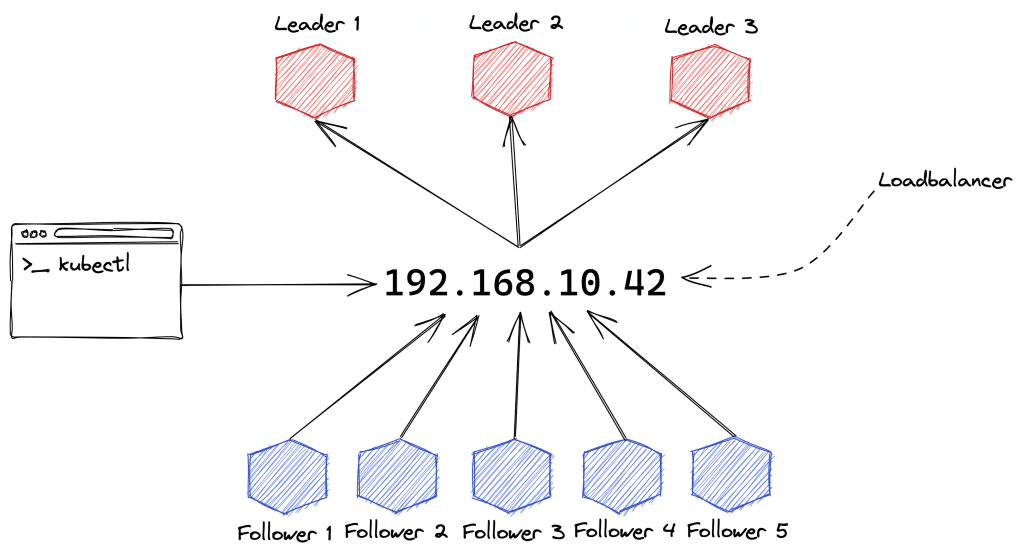
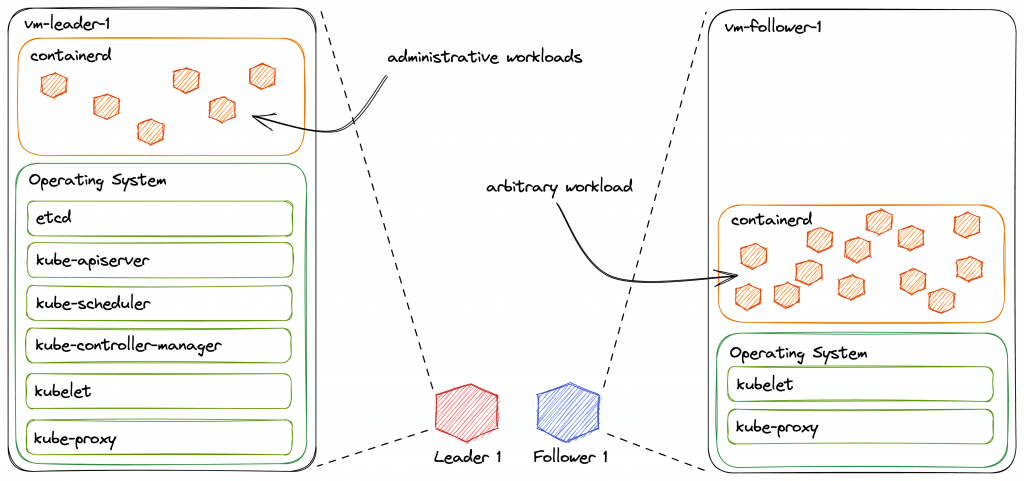
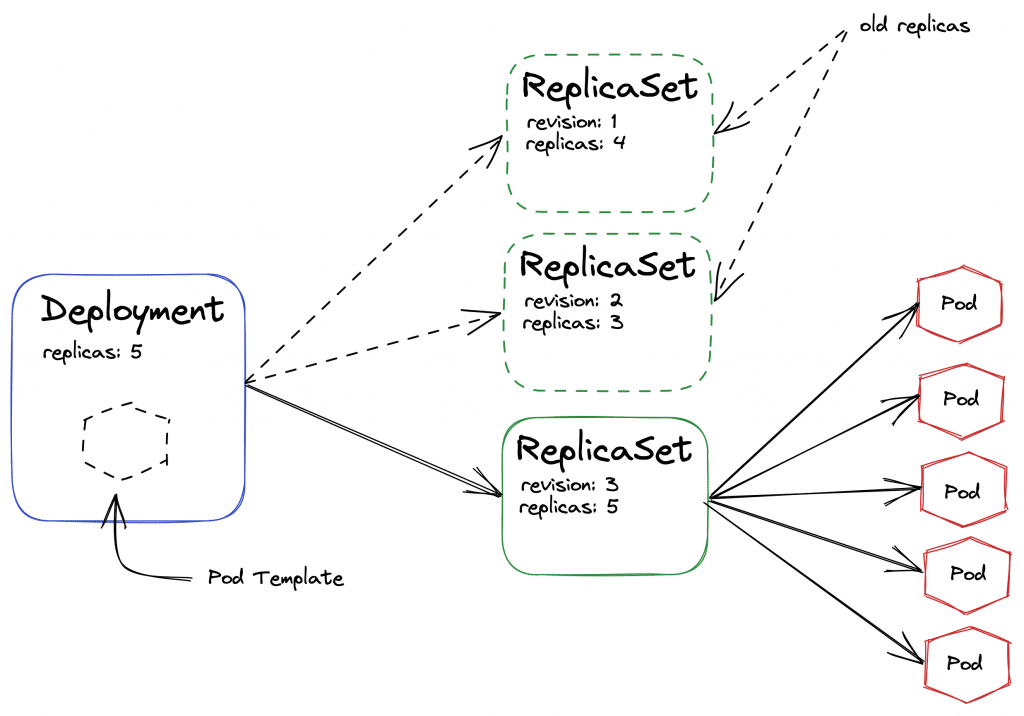
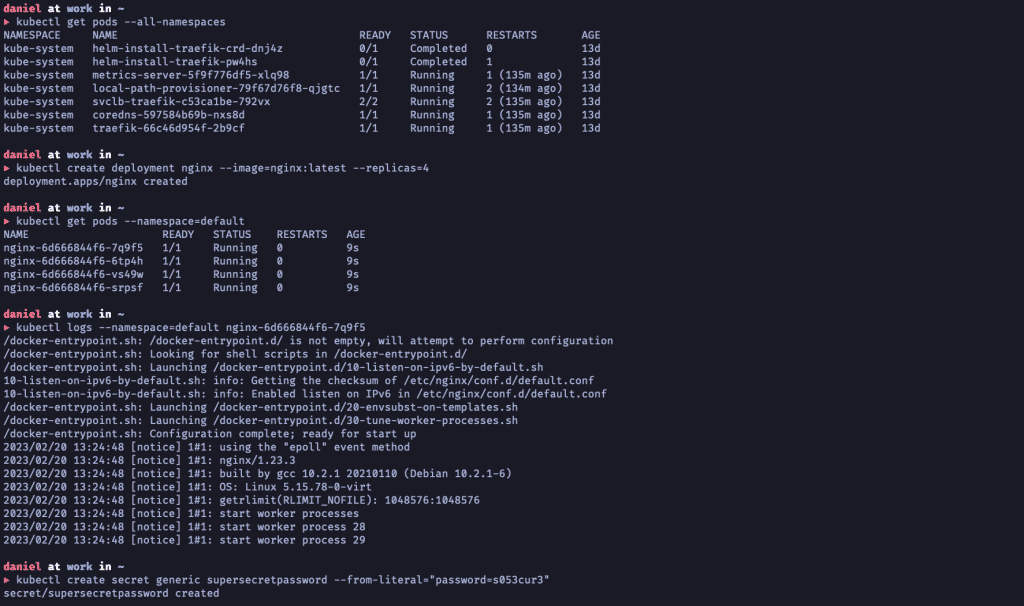
Im Laufe des letzten Jahres haben wir uns in dieser Blogserie ausführlich mit Kubernetes beschäftigt. Von leicht verständlichen Erklärungen zu Design und Funktionsweise über den Aufbau eines ersten (lokalen) Clusters bis hin zur Inbetriebnahme und Absicherung haben wir viele Aspekte behandelt.
Im besten Fall konntest du erste Erfahrungen zu sammeln und vielleicht schon die eine oder andere Anwendung eigenständig bereitstellen. Die naheliegende Frage ist nun, “wohin” geht die Reise von hier aus?
In diesem letzten Artikel unserer Serie werde ich daher einige Ausblicke geben. Was ist im täglichen Betrieb zu beachten? Wie wird das System heute noch genutzt? Und welche neuen Einsatzmöglichkeiten zeichnen sich gerade ab? Vielleicht ist ja der eine oder andere Anwendungsfall auch für dich interessant!
Kubernetes im Alltagsbetrieb
Nachdem du dein(e) Cluster eingerichtet hast, beginnt der Alltagsbetrieb in der schicken, neuen Cloud-nativen Umgebung. Und hier kann es (ungewollt) spannend werden! Die verteilte Architektur und das generelles Design erfordern eine andere Herangehensweise als in traditionellen IT-Umgebungen. Insbesondere beim Monitoring bzw. Observability oder beim Backup-Management.
Werden Anwendungen auf Kubernetes betrieben, reicht es nicht aus, nur die laufenden Anwendungen zu sichern und in das Monitoring einzubinden. Man muss sich auch um die zugrundeliegende Infrastruktur kümmern! Die Gründe hierfür sollten klar sein: Verliert man die Zustandsinformationen der Kubernetes-API in etcd, ist ein Betrieb nicht mehr möglich. Ist der Cluster selbst kompromittiert, sind auch die darauf laufenden Applikationen in Gefahr. Es gilt also, aufzupassen und vorzusorgen.
Zum Thema Sicherheit auf gibt es in dieser Blogserie bereits einen eigenen Beitrag, die wichtigsten Punkte möchte ich aber noch einmal zusammenfassen:
Anwendungen auf Kubernetes werden in der Regel als containerisierte Microservices betrieben, die über das clusterinterne Netzwerk miteinander kommunizieren. Eine entsprechende Absicherung der verwendeten Netzwerke, sowohl an den Clustergrenzen als innerhalb des Clusters, ist daher zwingend erforderlich. Hierzu gibt es die Möglichkeit der nativen Fähigkeiten von Kubernetes selbst (Stichwort NetworkPolicies) oder man greift auf externe Tools zurück, die in ihrem Funktionsumfang weniger eingeschränkt sind (z.B. CNIs wie Cilium oder Calico).
Darüber hinaus sollten auch die betriebenen Container selbst unter die Lupe genommen werden: Nutzen sie vulnerable Abhängigkeiten, benötigen sie alle zugewiesenen Privilegien, und wie sieht es mit der Aktualität der Images selbst aus? Für all diese Fragen gibt es Tools, die die Umsetzung erleichtern – von Imagescannern wie Trivyoder Docker Scoutbis zur Echtzeiterkennung von Sicherheitsproblemen mit NeuVector von unserem Partner SUSE.
Das Ökosystem bietet auch Lösungen für das Backup-Management: Angefangen bei Kasten, einer Enterprise-Backuplösung von Veeam, über Velero, einer FOSS-Lösung für Backups von Clusterzustand und PersistentVolumes, bis hin zu Kanister (ebenfalls von Veeam), das Backup-Management auf Anwendungsebene ermöglichen soll.
Je nach Anwendungsfall und Clusterspezifikationen (Anzahl an Nodes, onPrem vs. Cloud, etc.) wirst du dich wahrscheinlich für eine bestimmte Backup-Lösung und einen speziellen Ansatz für das Backup-Management wählen.
Mit den genannten Lösungen kannst du aber definitiv deine ersten Schritte gehen.
Kubernetes als Infrastruktur-Plattform
Ein stetig wachsender Anwendungsfall ist der Einsatz als zentrale Infrastruktur-Management-Plattform. Dank zahlreicher (Open-Source-) Projekte im Cloud-nativen Ökosystem ist Crossplane heute in der Lage, Ressourcen wie S3-Buckets, Cloud-VMs oder gemanagte Datenbanken in verschiedenen Public Clouds zu provisionieren und zu verwalten.
Du kannst das System auch als Hypervisor für deine VM-Flotte verwenden Möglich macht dies das Projekt kubeVirt, das KVM-VIrtualisierung auf Kubernetes bringt – alles unter einem Dach, quasi! kubeVirt selbst ist ein Projekt innerhalb der CNCF, das unter Anderem von namhaften Firmen wie SUSE, RedHat oder ARM unterstützt wird.
Kubernetes als Management-Plattform
Doch nicht nur für Infrastruktur kann Kubernetes als Plattform herhalten. Es bietet auch die Möglichkeit, dass andere Benutzer in der Organisation die zentrale Schnittstelle für Ihre tägliche Interaktion mit eurer IT-Landschaft werden. Das Schlagwort für diese Art der Nutzung lautet Internal Development Platform (IDP) und ist eines der Themen, die derzeit stark im Kommen sind:
Vorgelebt von Spotify und seiner modularen Plattform Backstage gibt es mittlerweile eine ganze Reihe von kommerziellen und nicht-kommerziellen Lösungen, die Entwicklern in Zeiten von SaaS-Lösungen und immer komplexeren Entwicklungsumgebungen helfen können, den Überblick zu behalten.
Ziel von IDPs ist es, verschiedene Informationen rund um den Entwicklungszyklus zusammenzuführen, Prozesse zu vereinheitlichen und “Golden Paths” zu etablieren. Mit seiner mächtigen API und seinen Orchestrierungsmöglichkeiten bietet sich Kubernetes für so ein Vorhaben an. Schließlich sollen verschiedenste Drittanwendungen mit der Plattform interagieren, Informationen bereitstellen und im Gegenzug Anweisungen von der Plattform erhalten. Nicht umsonst ist das Thema “Kubernetes als IDP” also eines der derzeit “heißesten” Themen auf Konferenzen wie z.B. der KubeCon.
Fazit
Kubernetes wird nicht langweilig und bietet viele Möglichkeiten zur Erweiterung und zum Ausbau. Das ist ein bisschen Fluch und Segen zugleich. Denn mit den Vorteilen entstehen auch neue Risiken. Es kann sinnvoll sein klein anzufangen, sein(e) Cluster nach und nach zu erweitern und an neue Anwendungsfälle anzupassen.
Eine der wichtigsten Regeln ist, von der ersten Minute an Sicherheit und Observability zu bedenken. Das Risiko einer unentdeckten Schwachstelle ist ansonsten aufgrund der verteilten Architektur und den darauf laufenden Anwendungen schwer zu überblicken.
Wenn du nach der Lektüre dieser Serie Lust bekommen hast loszulegen, du dich aber noch nicht zu 100% bereit fühlst direkt loszulegen, ist vielleicht unser Kubernetes Training etwas für dich!
Ansonsten kannst du jederzeit unser Sales Team kontaktieren, und mit einem unsere Kubernetes-Spezialisten über deine Fragen sprechen.