In den letzten Monaten gab es zwischenzeitlich wegen allgemein erhöhtem Datenvolumen im Internet ja immer wieder ein mal Probleme mit diversen Providern bezüglich langsamer oder nur sporadisch oder tagelang nicht richtig funktionierender Internet Verbindungen.
Gerade die zunehmende Verbreitung von Videokonferenzen in Unternehmen durch Homeoffice und parallel ein immenser Zuwachs der Kunden von Streaming Plattformen hat dazu sicher massgeblich beigetragen.
Nun ist es auf den ersten Blick auch nicht immer so einfach zu erkennen, welche Ursachen z.B. Probleme bei einer Videokonferenz haben können.
Wenn alle anderen Dienste wie E-Mail, normale Webseiten, oder auch das Arbeiten auf der Kommandozeile trotzdem irgendwie funktionieren, denkt man nicht immer gleich daran, dass es trotzdem ein Problem im lokalen Netzwerk oder auf der Strecke zum entsprechenden Server geben könnte.
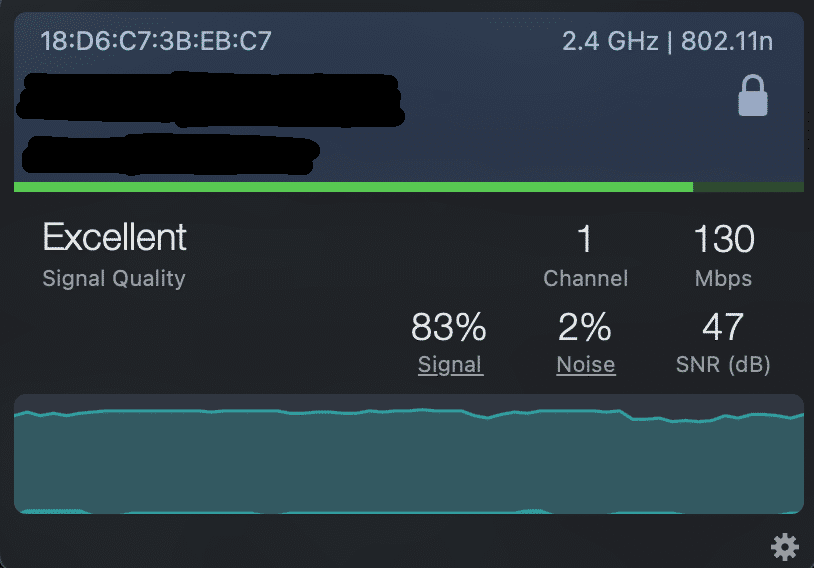
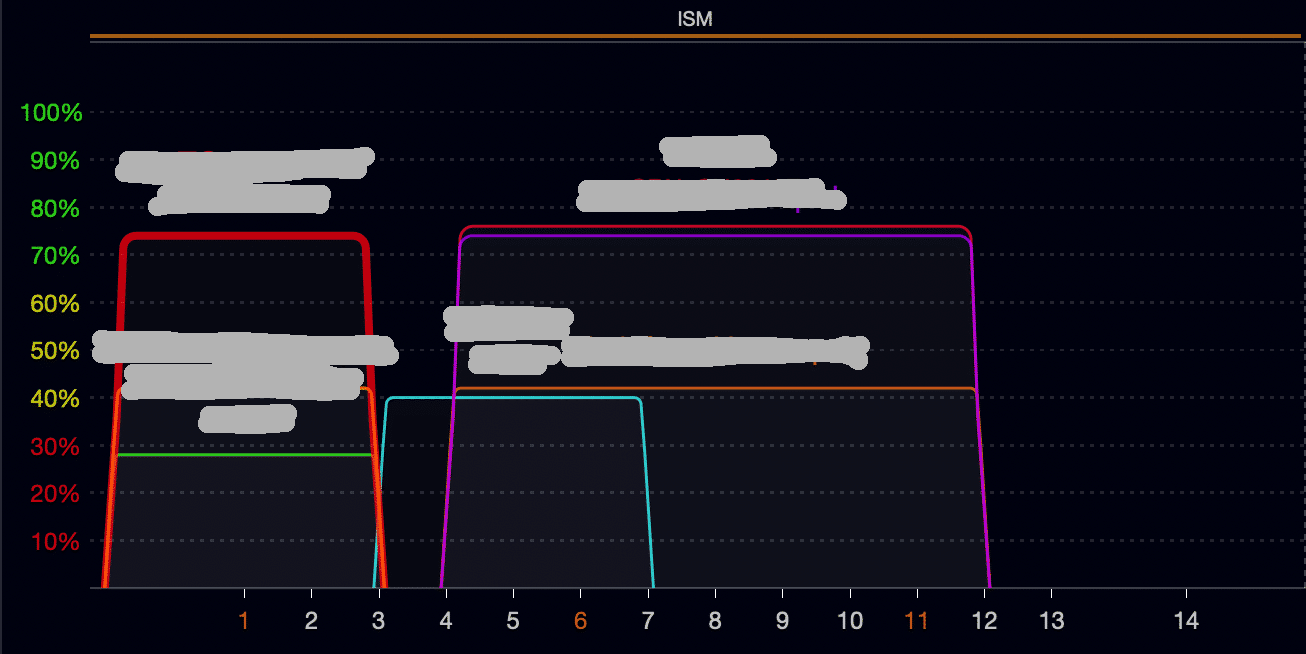
Zunächst ist es natürlich sinnvoll erst ein mal zu schauen, ob man nicht grundsätzliche Probleme im lokalen Netzwerk hat, z.B. bei Mehrfamilien Häusern oder Wohnblöcken ein überlastetes 2,4 GHz WLAN.
Dabei ist es sehr hilfreich, wenn man entsprechende Tools für sein Betriebssystem nutzt, die die Auslastung und die Verbindungsqualität der aktuellen WLAN Verbindung anzeigen können.
(Beispiel siehe unten)
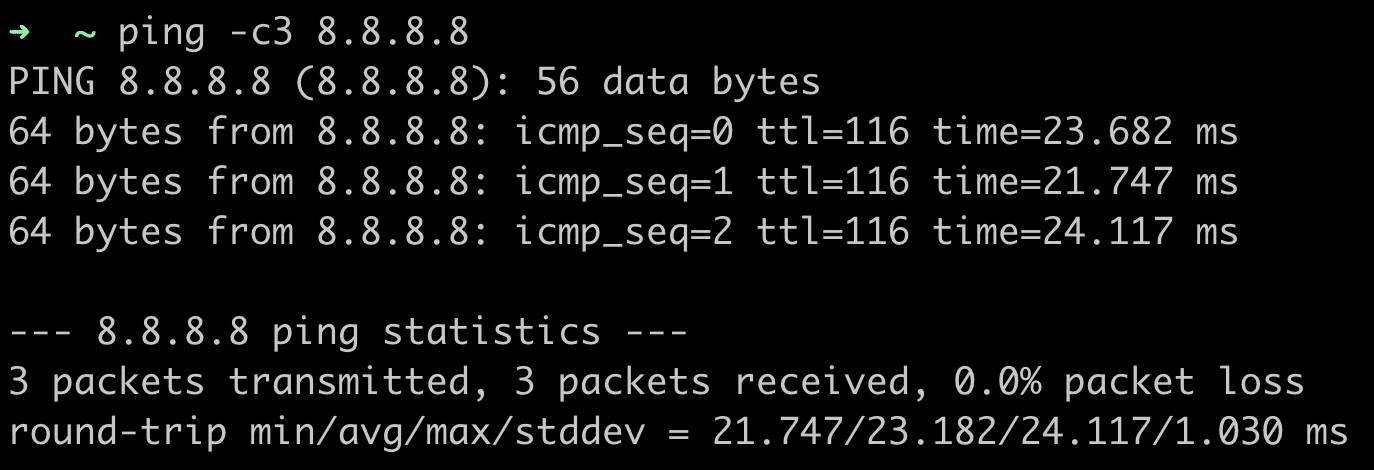
Falls dort alles o.k. ist, es aber trotzdem noch Probleme gibt, helfen altbekannte Tools, die es auch für alle gängigen Betriebssysteme gibt, bei der Eingrenzung weiter.
Einige im Beispiel mit der IP des Google DNS als Ziel:
(Syntax kann von System zu System unterschiedlich sein)
1. Ein simpler Ping
(die Antwortzeiten sollten nicht zu hoch sein, das Beispiel unten ist in dem Fall i.O.)
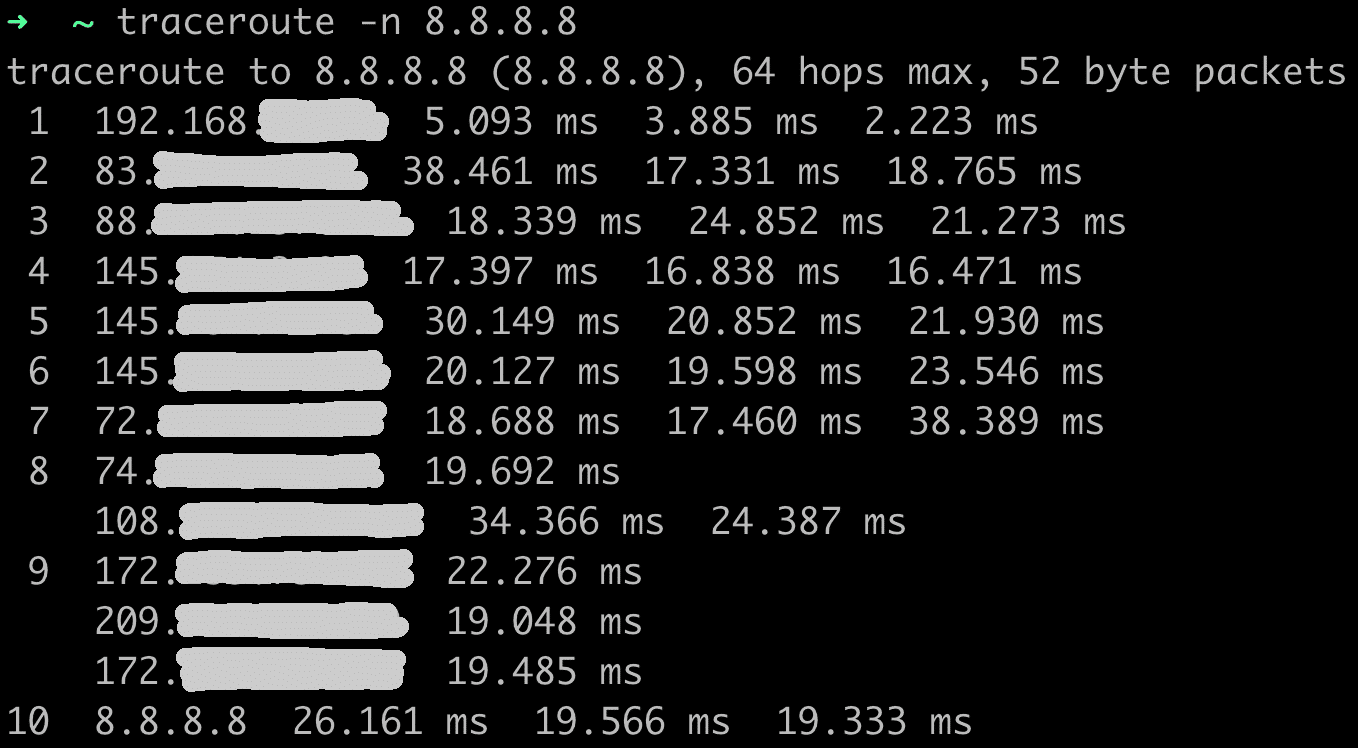
2. Traceroute
(man sieht die Antwortzeiten für alle Hops auf dem Weg zum Ziel)
3. MTR (mytraceroute)
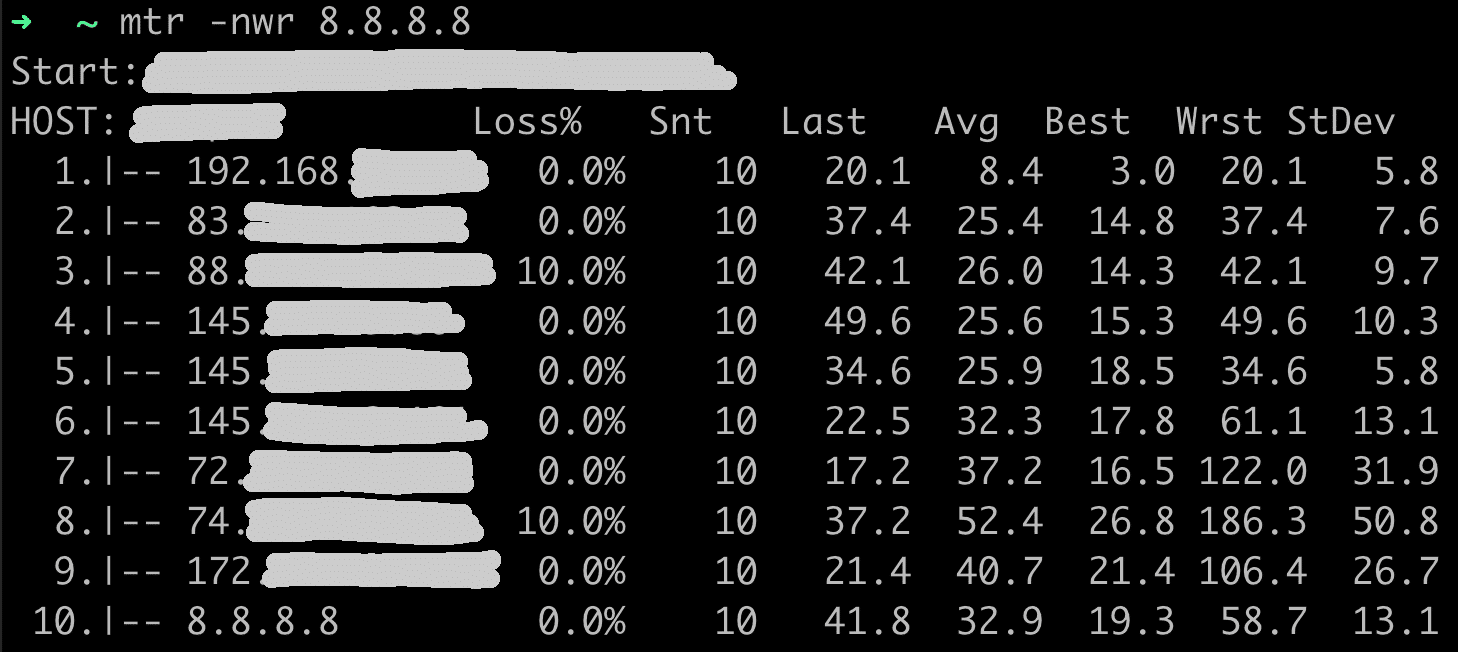
MTR finde ich persönlich am besten, da es eine Kombination von Ping und Traceroute ist und man für jeden einzelnen Hop die Paket Verluste sieht und dadurch ziemlich gut einschätzen kann, ob die Probleme z.B. eher im lokalen Netz, auf dem Weg zum Ziel, oder direkt nur am Ziel liegen (oder an allem gleichzeitig).
Leider blocken immer mehr Service Anbieter und Provider, oder auch Cloud Software Lösungen ICMP Pakete, so dass diese Tools nicht immer funktionieren, bzw. dann an bestimmten Stellen nur drei ??? eingeblendet werden.
Am Beispiel oben zum Google DNS war das zum Glück nicht der Fall.