Neue Tools auszuprobieren bedeutet auch, erst mal viel Dokumentation zu lesen. Im Falle von Elasticsearch ist das nicht viel anders. So liest man über Indizes und Shards, über Replika und Cluster. Die Installation ist relativ straight-forward, denn es stehen für alle großen Distributionen fertige Pakete zur Verfügung, die nur darauf warten genutzt zu werden. Doch eines fällt nach der Installation sofort auf: Man ist blind. Von den ganzen tollen Features die in der Dokumentation versprochen wurden, ist erst mal nichts zu sehen. Ich möchte heute ein paar Methoden und Plugins vorstellen, die das gesamte Konstrukt Elasticsearch durch Visualisierung etwas durchsichtiger und greifbarer machen.
API
Die API ist eine der mit am wichtigsten Bestandteile von Elasticsearch. Ohne sie würden viele Plugins wohl nicht existieren. Ich erwähne die API hier aber mit unter deswegen, um zu vermitteln was diese Plugins im Hintergrund eigentlich machen. So viel Magie steckt nämlich gar nicht dahinter. Bei dieser API handelt es sich nicht, wie oft fälschlicherweise behauptet, um eine REST API, sondern um eine CRUD API. Der kleine aber feine Unterschied besteht darin, dass die CRUD API direkt auf die Datenobjekte zugreift und nicht großartig abstrahiert. Man kann sie aber genauso über verschiedene URLs ansprechen. Ein Aufruf, um einen allgemeinen Status über einen Elasticsearch Server zu erhalten, würde zum Beispiel lauten curl localhost:9200/_status. Als Ergebnis erhält man einen guten Überblick über den aktuellen Stand, die Anzahl der Indizes und nähere Infos zu diesen. Die Ausgabe ist sogar im JSON Format, lässt sich also sehr gut verarbeiten. Solche Statusberichte gibt es auch für Cluster einen einzelnen Index.
[...]
"_shards" : {
"total" : 622,
"successful" : 462,
"failed" : 0
},
"indices" : {
"logstash-2014.06.27" : {
"index" : {
"primary_size_in_bytes" : 435,
"size_in_bytes" : 435
}
[...]
ElasticHQ
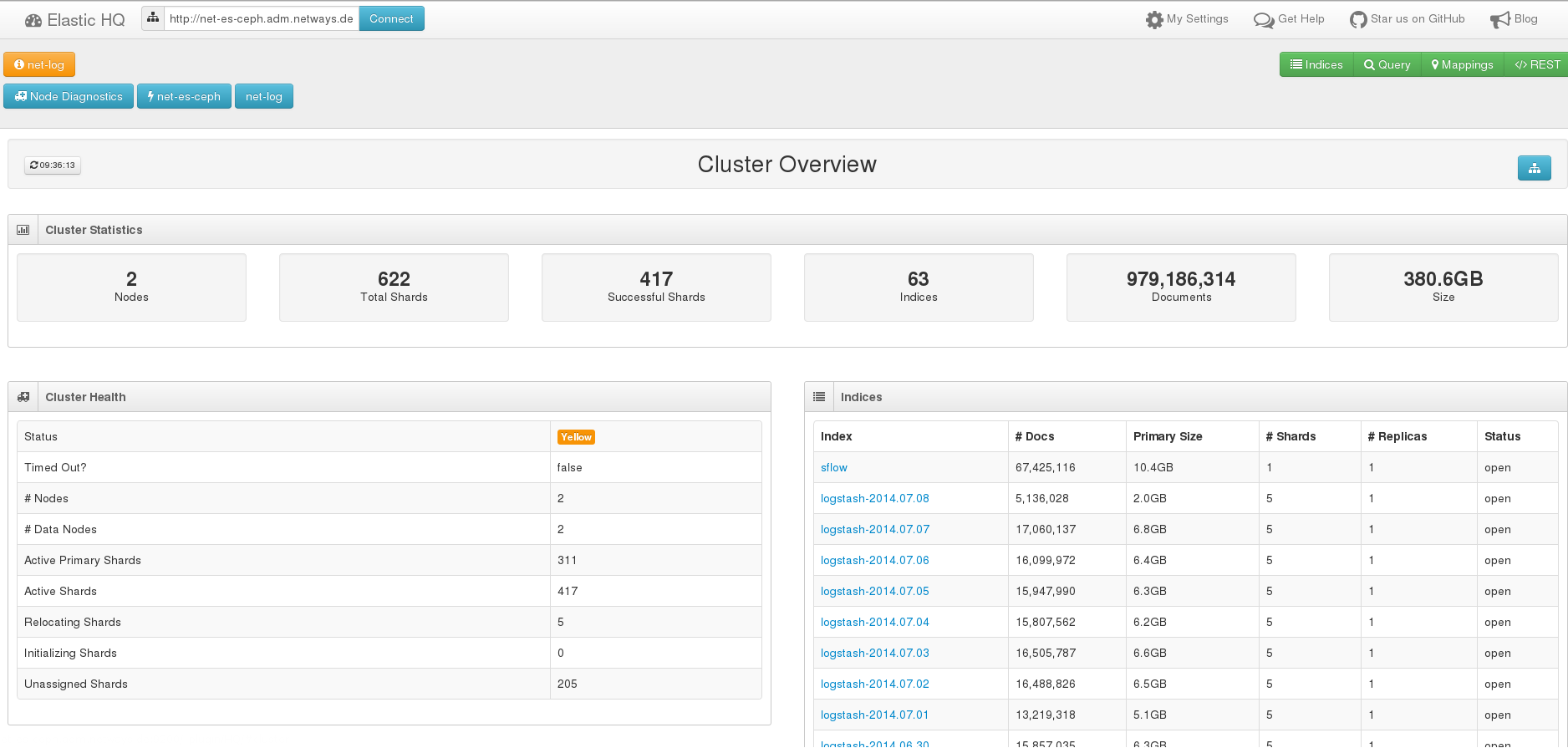
ElasticHQ Plugin – Index Übersicht
Das ElasticHQ Plugin hilft dabei, den Einstieg zu finden. In einem aufgeräumten Webinterface erhält man Informationen über die Last und den Ressourcenverbrauch der einzelnen Server. Indexe werden aufgelistet und Operationen wie “Optimize”, “Refresh” und “Delete” können auf sie angewendet werden.
Mit einem Interface für Queries kann man seine Daten durchsuchen und dabei gezielt einzelne Indexe ausschließen. Die Übersicht über Mappings hilft vor allem, wenn man für einzelne Felder das Mapping ändern muss, wie zum Beispiel im Zusammenhang mit Kibana, wo manche Operationen nur durchgeführt werden können, wenn sie numerische Felder erhalten.
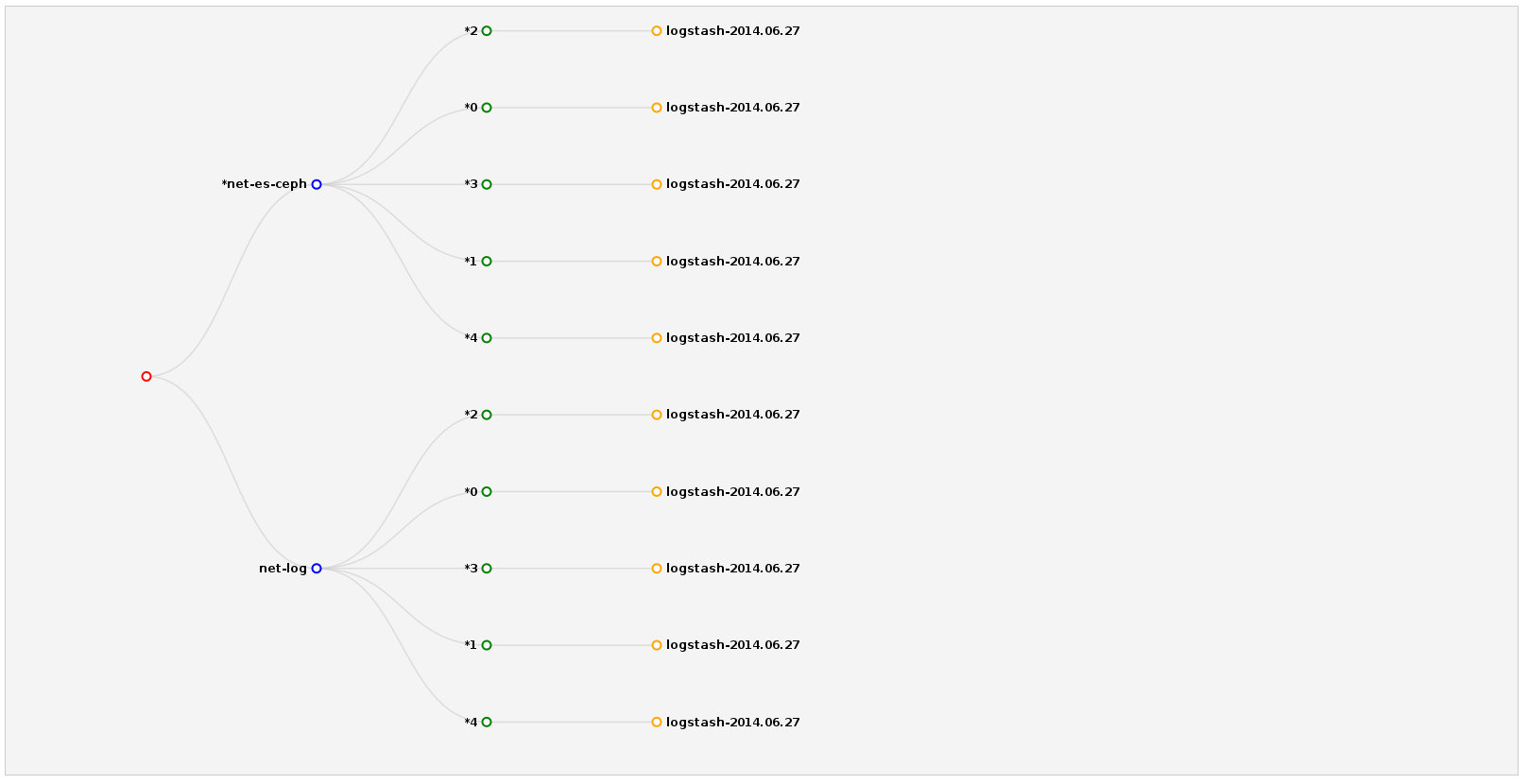
ElasticHQ Plugin – Cluster
Ein besonderes Augenmerk gilt der Cluster Ansicht. Mit vielen Indizes wird es zwar schnell unübersichtlich, einen guten Überblick bekommt man aber dennoch, wenn man sich einen Einzelnen ansieht. Die Verteilung der Shards wird schnell klar und ob wirklich Replika existieren, lässt sich auch nachvollziehen.
Head

Head Plugin
Wobei ElasticHQ seine Schwierigkeiten hat, das macht das Head Plugin umso besser. Eine Übersicht aufgeteilt auf Nodes die darstellt, wieviele Shards es pro Index gibt und wie diese aktuell verteilt sind. Die Master Node wird klar markiert und Operationen kann man auch durchführen. So lassen sich ganze Server ausschalten oder Indexe löschen, flushen, refreshen etc. Wie in ElasticHQ auch, gibt es Bereiche in denen man Queries durchführen kann und noch mal alle Indizes aufgelistet bekommt.
Bei den beiden Plugins handelt es sich um so genannte ‘site-plugins’. Das bedeutet, dass sie lediglich einen statischen Inhalt ausliefern und Elasticsearch nach der Installation nicht neu gestartet werden muss. Möglich macht das die Kommunikation über die API, die für die Plugins alle nötigen Informationen abliefert.


















0 Comments