
Während man mit Kubernetes arbeitet oder entwickelt, wird man in den seltensten Fällen alles auf einem Cluster machen. Ob man ein lokales Minikube verwendet, oder Zugriff auf verschiedene Cluster für Produktion und Testing hat, muss man die Daten ja verwalten, und auswählen in welchem Kontext man gerade arbeitet.
Struktur der Konfiguration
Die Konfiguration für kubectl und andere Kubernetes Clients findet man normalerweise in $HOME/.kube/config. Ich möchte hier ein paar Beispiele zeigen, wie man hier neue Cluster hinzufügen kann. Der Inhalt sieht im einfachsten Fall so aus. Hier sind die Daten bzw. Secrets abgekürzt.
apiVersion: v1
kind: Config
current-context: my-cluster
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://my-cluster:6443
name: my-cluster
contexts:
- context:
cluster: my-cluster
user: admin
name: my-cluster
users:
- name: admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
Hier sind nun folgende Bereiche wichtig:
- clusters definiert die bekannten Cluster mit API Endpunkt (URL) und dem passenden CA Zertifikat
- users definiert Zugangsdaten und Authentifizierungsmechanismen, meistens ein Client Zertifikat, Auth-Tokens oder SSO Daten
- contexts verbindet Cluster und Authentifizierung, und erlaubt auch das setzen des Namespaces
- current-context zeigt an welcher Context gerade benutzt wird
Die aktuell verwendete Konfiguration kann man sich bequem anzeigen lassen, und dabei werden dann auch die Detaildaten zensiert – wie oben.
kubectl config view
Andere Konfigurations Dateien
Viele Kubernetes Anbieter stellen direkt die fertige Konfigurationsdatei zur Verfügung, die speichert man entweder direkt unter $HOME/.kube/config oder spezifiziert diese explizit.
kubectl --kubeconfig /tmp/my-config config view export KUBECONFIG=/tmp/my-config kubectl config view
Dabei wird nun diese Datei alleine geladen und ist direkt benutzbar. KUBECONFIG gilt dann für alle weiteren Befehle in der Shell auch.
Verbinden der Konfiguration
Um mehrere Dateien zusammenzuführen kann man nun auch mehrere Dateien laden, und so zusammenführen.
cp ~/.kube/config ~/.kube/config.bak KUBECONFIG=~/.kube/config.bak:/tmp/my-config kubectl config view --raw >~/.kube/config
Bitte unbedingt die Datei vor dem speichern prüfen, doppelte Namen können zu Fehlern führen und der Context wird dann neu gesetzt.
Für kleinere Korrekturen kann man dann auch problemlos die Datei nachträglich von Hand editieren.
Tools und Shell Erweiterungen
Ich nutze gerne die Tools kubectx und kubens um schnell zwischen verschiedenen Kontexten umschalten zu können, bzw. zu sehen mit was ich gerade arbeite. Dazu gibt es auch die praktische Auto-Vervollständigung für die Shell.
Welchen Kontext bzw. Namespace ich gerade nutze, zeigt mir außerdem mein Bash Prompt auch an. Hier am Beispiel von powerline-shell mit meinen Modifikationen.
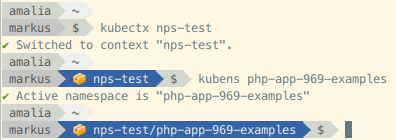
Es existieren auch einfachere Möglichkeiten, wie die kube-ps1 von jonmosco auf GitHub.
![]()
Mehr Infos
Wir bereiten gerade unsere neue Kubernetes Quick Start Schulung vor um den Teilnehmern einen schnellen Einstieg in die Benutzung von Kubernetes zu bringen. Wenn du Interesse hast mehr mit uns in Kubernetes einzusteigen, schau doch mal nach den Terminen.
Das Headerbild stammt von Loik Marras via unsplash.

















0 Kommentare