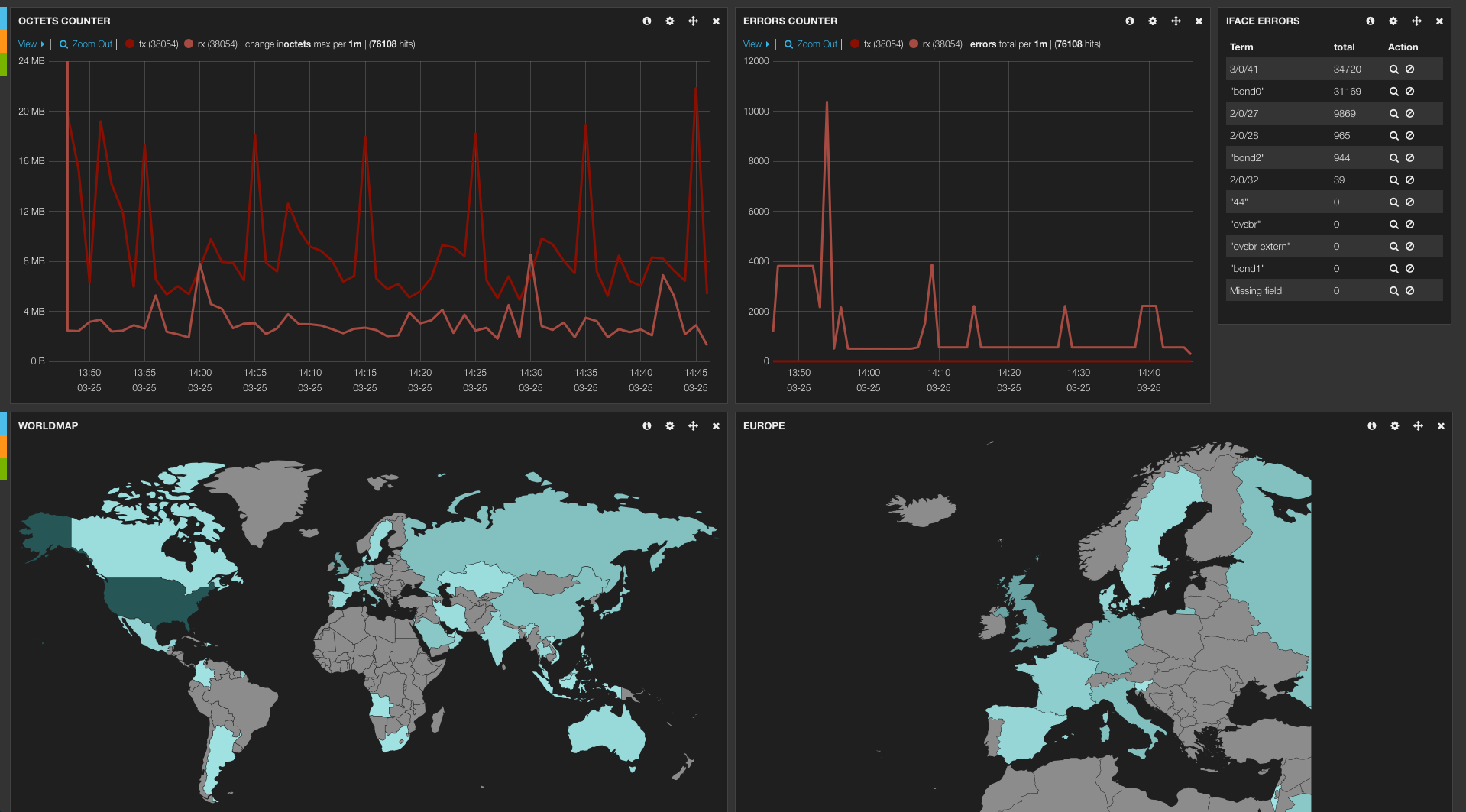
Das Webinterface zu Elasticsearch “Kibana” wurde vor kurzem in der Version 3.0.0. GA released auch Elasticsearch selbst steht im neuen Glanz mit vielen neuen und nützlichen Features. Viele kennen bereits diese zwei Komponenten vermutlich unter anderem durch den Einsatz von Logstash. Dass man diese zwei Komponenten auch ohne Logstash für diverse Anwendungsfälle gut verwenden kann steht außer Frage.
Wir entwickeln aktuell an einer Ruby-Anwendung, die Sflow Daten empfängt, verarbeitet und an Elasticsearch sendet bzw. dort ablegt. Mit dem Kibana Webinterface lassen sich dann leicht Graphen über die gesammelten Daten auswerten und darstellen. Sflow ist ein Netzwerkprotokoll, dass u.a. Stichproben aus dem fließenden Traffic pickt und diese dann als sogenannte Samples an einen Collector sendet. Die Liste der Collectoren ist lang besteht allerdings meist aus kommerziellen closed-source Produkten.
Generell lassen sich daraus Informationen aufbereiten und ableiten, die zum Beispiel die Top 10 der IP-Adressen auf einem Switch, die den meisten Traffic verursachen oder VLANs die besonders viel Traffic verbrauchen und viele mehr.
Die Anwendung werden wir in den nächsten Wochen auf Github zur Verfügung stellen und in einem weiteren Blogpost darauf aufmerksam machen. Solange gibt es schon mal ein Sneak-Preview in Form von Screenshots 🙂