
OpenSearch bringt von Haus aus die Möglichkeit mit, Machine Learning zu nutzen und hierfür pre-trained aber auch untrained Modelle zu nutzen. Den Status deiner Modelle kannst du bequem in OpenSearch Dashboards sehen.
Wie du OpenSearch Machine Learning zum Laufen bringst, zeige ich dir in diesem Blogbeitrag. Wie bei vielen neuen und sich schnell weiterentwickelnden Projekten kann es jedoch sein, dass bis zum Release dieses Blogposts der ganze Prozess noch einmal einfacher geworden ist.
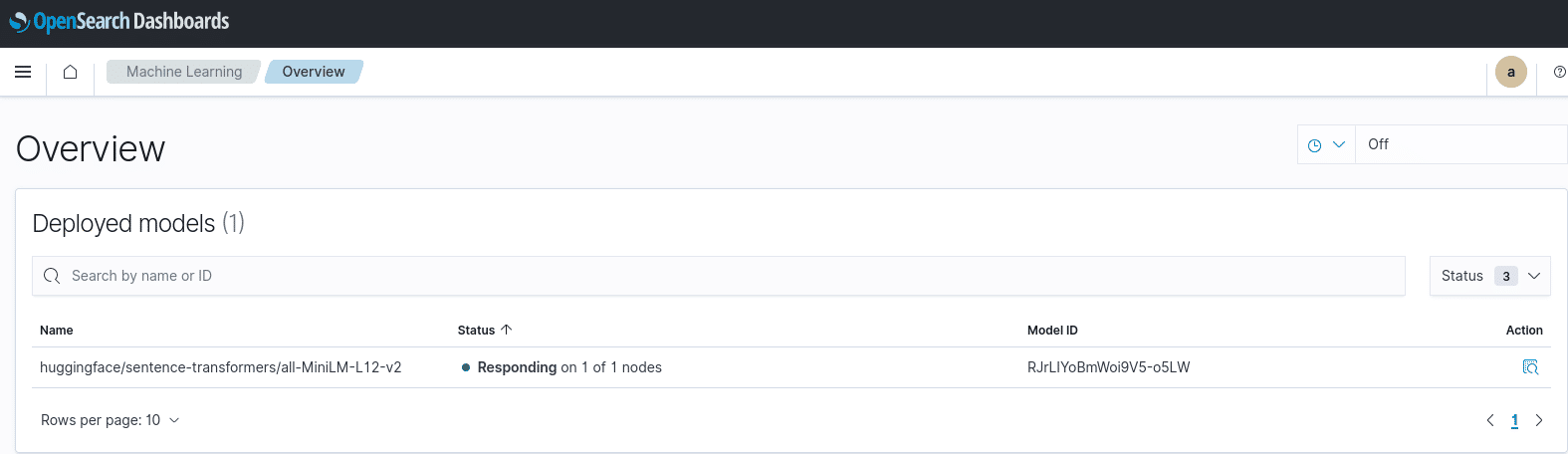
Der Prozess, um OpenSearch für Machine Learning vorzubereiten, besteht aus diesen Bausteinen:
- Vorbereitung
- Upload des Modells
- Modell-Gruppe erstellen
- Model auf die Gruppe registrieren
- Deployment
- Machine Learning nutzen.
Ursprünglich bin ich dieser Anleitung gefolgt. Du arbeitest am bequemsten direkt unter den Developer Tools (Management-> Dev Tools), kannst deine Befehle aber wie immer auch einfach via curl gegen die API senden:
Vorbereitung von Open Search auf Machine Learning
Zunächst habe ich für alle in meinem Beispiel genutzten Modelle URL-Registrierung zugelassen:
PUT _cluster/settings
{
"persistent" : {
"plugins.ml_commons.allow_registering_model_via_url" : true
}
}
Außerdem habe ich das Zeitintervall der Synchronisation erhöht.
Denn “ML Commons will run a regular sync up job to sync up newly loaded or unloaded models on each node”:
PUT /_cluster/settings
{
"persistent": {
"plugins.ml_commons.sync_up_job_interval_in_seconds": 600
}
}
Ab hier musst du einige Python-Libraries laden. Viele Modelle basieren auf der Pytorch-Library. So auch Sentence-Transformers, welches für einige der OpenSearch Modelle benötigt wird.
pip install -U sentence-transformers
Prinzipiell werden ML-Tasks nur auf den eigens dafür zugewiesenen OpenSearch Knoten ausgeführt und hierfür habe ich in meiner opensearch.yml folgende Einträge gesetzt:
node.roles: [ data, cluster_manager, ml ] plugins.security.restapi.roles_enabled: ["all_access","ml", "security_rest_api_access"]
Machine Learning Modell bereitstellen
Vorab: Über Task-IDs checkt man, ob die vorherigen Schritte durchgingen und besorgt sich notwendige Informationen zum weiter zuordnen.
Um Machine Learning Modelle in OpenSearch bereitzustellen, legt man einfach eine Gruppe an. Anschließend lädt man das Modell, fügt das Modell der Gruppe hinzu, deployt es über die Modell-ID an die gewünschten Knoten und hat anschließend die Möglichkeit, Machine Learning zu nutzen. Diese einzelnen Schritte zeige ich dir jetzt aber noch einmal detailliert.
Schritt 1: Modell Gruppe hinzufügen.
Bevor Modelle einer Gruppe hinzugefügt werden können, muss eine solche Gruppe angelegt werden. In meinem Beispiel habe ich sie “my-ml-group” genannt. Am einfachsten werden die Gruppen per API-Call hinzugefügt:
POST /_plugins/_ml/model_groups/_register
{
"name": "my-ml-group",
"description": "This is a public model group"
}
Es wird Success/Fail-Status sowie Gruppen-ID zurückgegeben, die benötigt wird: z.B. gprKIYoBmWoi9V5-T2Pb
Schritt 2: Das Modell wird von Huggingface geladen. (In meinem Beispiel verwende ich das Modell “all-MiniLM-L12-v2”)
POST /_plugins/_ml/models/_upload
{
"name": "huggingface/sentence-transformers/all-MiniLM-L12-v2",
"version": "1.0.1",
"model_format": "TORCH_SCRIPT"
}
Schritt 3: Das all-MiniLM-L12-v2 Modell wird auf die vorherige Gruppen-ID meiner my-ml-group registriert:
POST /_plugins/_ml/models/_register
{
"name": "huggingface/sentence-transformers/all-MiniLM-L12-v2",
"version": "1.0.1",
"model_format": "TORCH_SCRIPT",
"model_group_id": "gprKIYoBmWoi9V5-T2Pb"
}
Hier bekommt man wieder den Success/Error-State, sowie eine Task ID zurück. In meinem Beispiel ist das die MprLIYoBmWoi9V5-o5Ix.
Schritt 4: Model-ID besorgen
Nutzt man die Task-ID vom registrierten Modell, sieht man Modell ID sowie Error-State:
GET /_plugins/_ml/tasks/MprLIYoBmWoi9V5-o5Ix
{
"model_id": "RJrLIYoBmWoi9V5-o5LW",
"task_type": "REGISTER_MODEL",
"function_name": "TEXT_EMBEDDING",
"state": "COMPLETED",
"worker_node": [
"KmfjhwWjS7eepv4PnUMKWw"
],
"create_time": 1692784108336,
"last_update_time": 1692784119285,
"is_async": true
}
Die Modell-ID wird nun für das nachfolgende Deployment benötigt.
Schritt 5: Auf den Model-Nodes deployen
Zum eigentlichen Deployment braucht es Modell-ID und Knoten. Damit kann ich es auf all meinem Machine Learning-Knoten ausrollen:
POST /_plugins/_ml/models/RJrLIYoBmWoi9V5-o5LW/_load
Als Antwort bekommen ich den Task-Type: “Deploy“, sowie den State: “Completed”
{
"model_id": "RJrLIYoBmWoi9V5-o5LW",
"task_type": "DEPLOY_MODEL",
"function_name": "TEXT_EMBEDDING",
"state": "COMPLETED",
"worker_node": [
"KmfjhwWjS7eepv4PnUMKWw"
],
"create_time": 1692785563893,
"last_update_time": 1692785582120,
"is_async": true
}
Schritt 6: Prediction testen
Hierzu braucht es die Modell ID aus Schritt 5 des Deployments. Mit folgendem Call kannst du die Prediction testen:
POST /_plugins/_ml/_predict/text_embedding/RJrLIYoBmWoi9V5-o5LW
{
"text_docs": [ "today is sunny" ],
"return_number": true,
"target_response": [ "sentence_embedding" ]
}
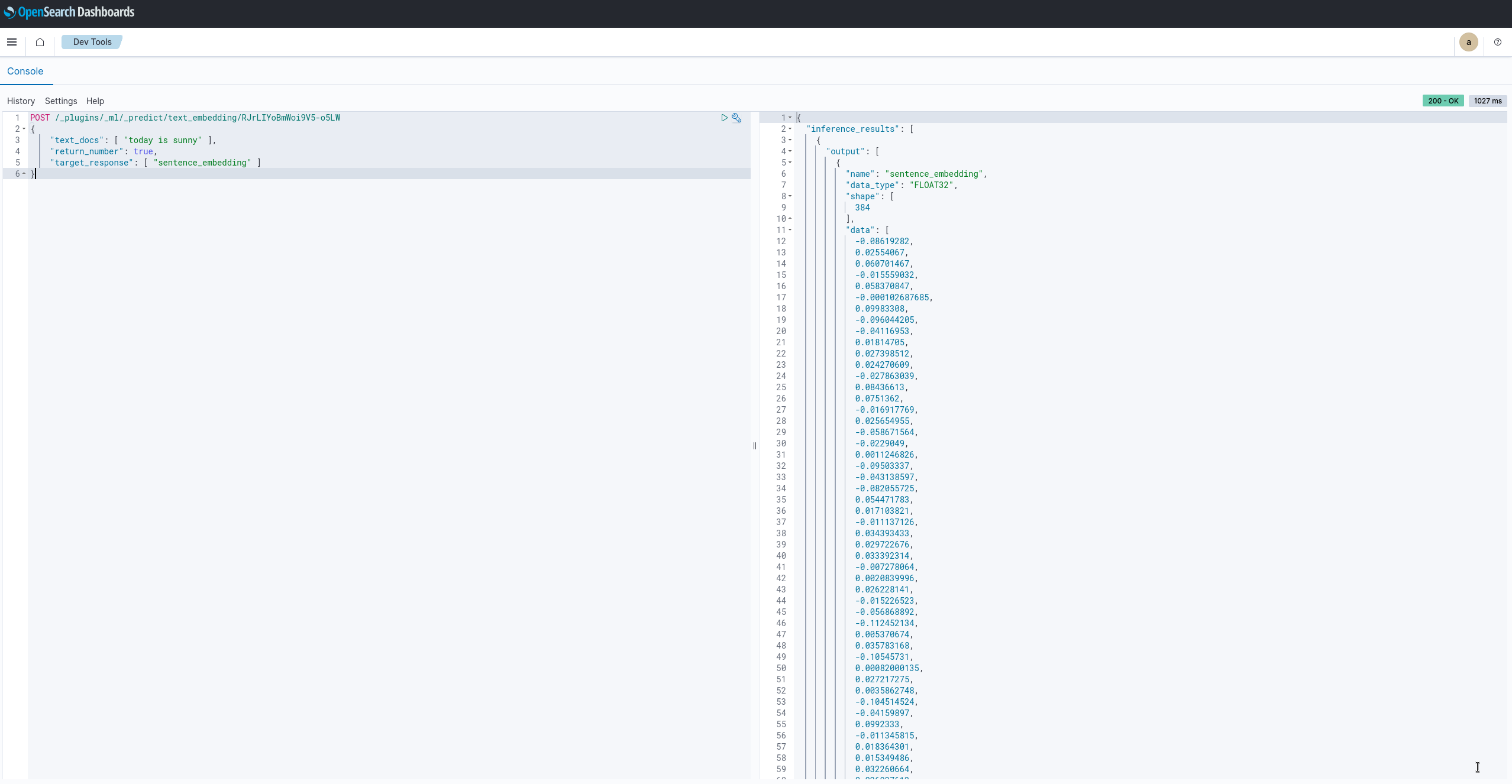
Ab hier wird es spannend, denn hat man mehrere OpenSearch Cluster läuft das Ganze direkt verteilt und auch alle Logs wie z.B. die von Icinga, Graylog uvm. sind im selben Backend. Dadurch wäre es möglich, mit allen vorhandenen Logs gleichzeitig zu trainieren!
Kannst du dir schon vorstellen, was du damit alles machen möchtest und vor allem da alles lokal bei dir stattfinden kann, was es bedeutet, dass du die volle Kontrolle über Datensicherheit hast?

















0 Kommentare