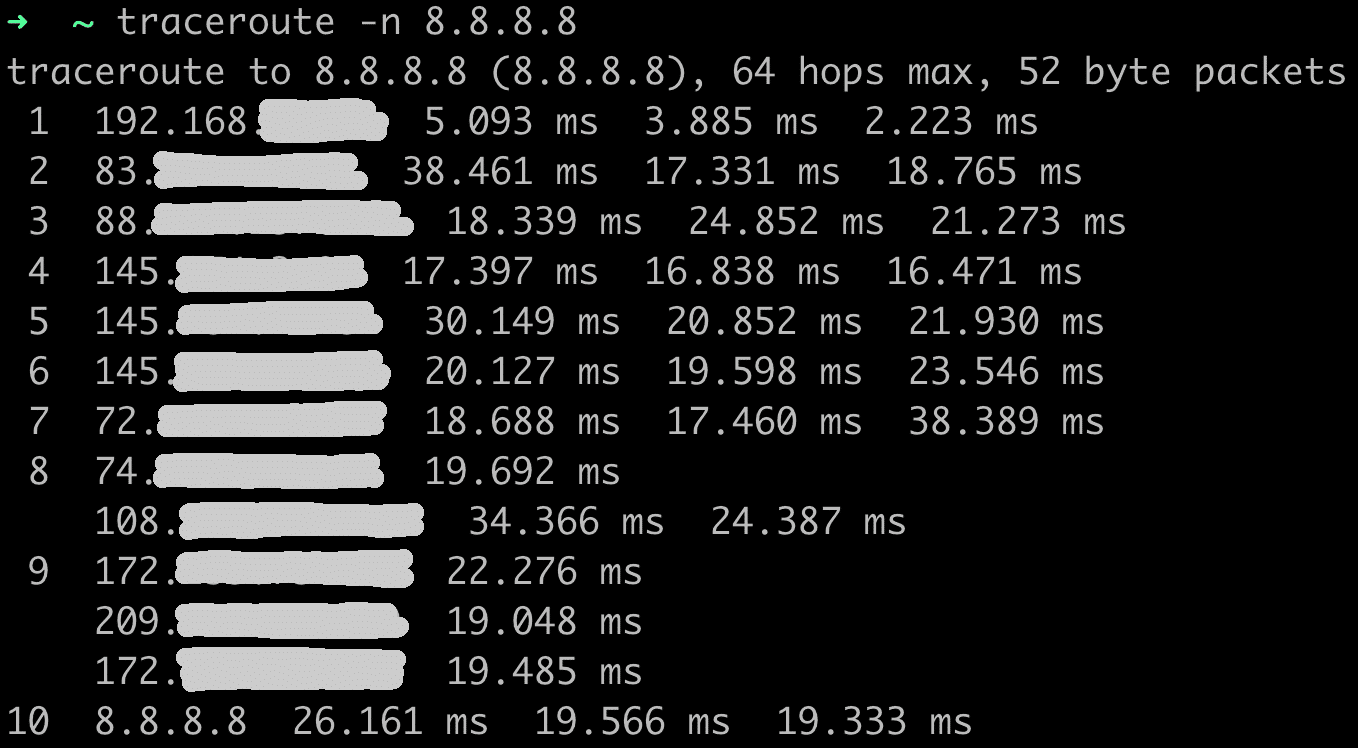
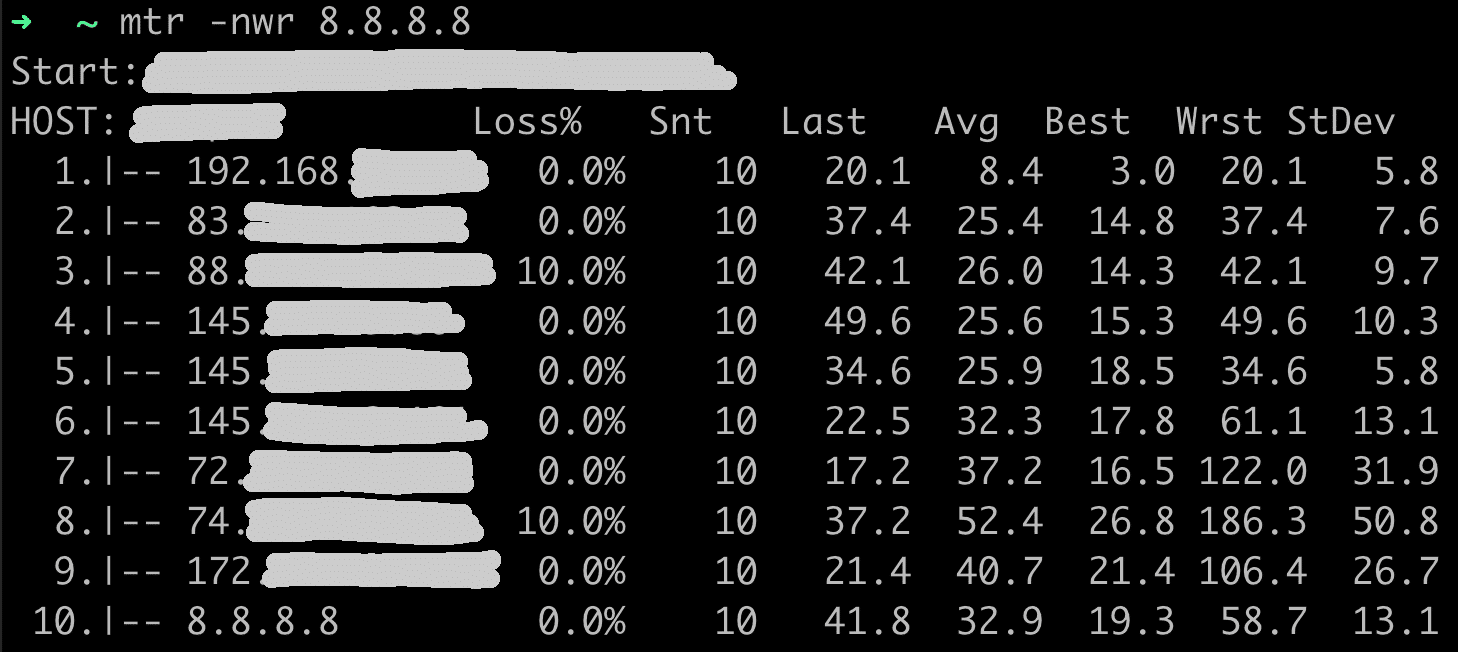
Im Rahmen meiner Ausbildung zum Fachinformatiker für Systemintegration bei NETWAYS Professional Services arbeite ich regelmäßig an neuen Projekte. Dabei steht neben dem Kennenlernen neuer Technik und Software besonders die Vertiefung von Schulungsinhalten im Fokus.
Im Rahmen des Projekts zur DNS-Schulung (Domain Name System) habe ich den DNS-basierten Werbeblocker Pi-hole aufgesetzt und konfiguriert. Pi-hole ist seit vielen Jahren die bekannteste und am weitesten verbreitete Anwendung für ein netzwerkweites Ad-Blocking. Das liegt besonders an den individuellen Konfigurationsmöglichkeiten, welche die Software anbietet sowie an der unkomplizierten Installation.
Warum ist ein DNS-Werbeblocker sinnvoll?
Viele Dienste und Websites im Internet bieten ihre Dienste für Endkunden kostenlos an. Da sich mit kostenlosen Inhalten in der Regel aber kein Geld verdienen lässt, sind Werbeanzeigen in den letzten zehn Jahren für viele Unternehmen eine, teilweise gar die wichtigste Einnahmequelle geworden.
Während der Einsatz von Werbung aus unternehmerischer Sicht sinnvoll und nachvollziehbar sind, können für die Nutzer:innen der Website / des Dienstes Probleme durch diese Werbeeinblendungen auftreten.
Teilweise sorgen Anzeigen “nur” dafür, dass Websites nicht richtig funktionieren oder sie die Ästhetik stören. Es gab jedoch schon Fälle, in denen Werbeanzeigen zum Verteilen von schädlichem Code genutzt wurden. Um das eigene Netzwerk werbefrei zu halten, gibt es verschiedene Möglichkeiten. Die bekanntesten sind Pi-hole und AdGuard Home.
Dank dieser Programme kann das Auspielen von Werbung auf allen mit dem Netzwerk verbundenen Geräten verhindert werden. Dieser Text beschäftigt sich mit der Einrichtung und Konfiguration von Pi-hole, während unser Blogartikel von letzter Woche AdGuard Home genauer unter die Lupe nimmt.
Was ist Pi-hole?
Pi-hole ist eine Open-Source-Software, die als Werbe- und Trackingblocker fungiert. Welche Inhalte dabei für welches Gerät im lokalen Netzwerk geblockt werden, lässt sich individuell konfigurieren. Die Anwendung basiert auf Linux und ist dafür optimiert, um auf Computern mit minimaler Ausstattung, etwa dem Raspberry Pi, zu funktionieren.
Damit die Blockfunktion von Pi-hole wie gewünscht funktioniert, fungiert das Programm als DNS-Server für das eigene Netzwerk, über den der komplette Netzwerkverkehr sowohl ausgehend als auch eingehend geleitet wird. Mithilfe dieser Schnittstellenfunktion bekommt Pi-hole Zugriff auf alle eingehenden IP-Adressen, die mit dem Abruf einer Homepage oder eines Dienstes verbunden sind.
Diese Funktion sorgt dafür, dass Filter angewendet werden können, die Werbe- und Tracking-IP’s herausfiltern und z. B. die Website in einer werbefreien Form anzeigen. Die Werbung wird also verhindert, bevor das Endgerät überhaupt die Chance hat, den entsprechenden Inhalt zu laden.
Die angesprochenen Filter werden in Form von Filterlisten implementiert, die verschiedene Ziele erfüllen können. Neben dem bekannten Werbe- und Trackingblocker kann auch der Zugriff auf spezielle Seiten, etwa mit Inhalten der Erwachsenenunterhaltung oder soziale Netzwerke, eingeschränkt oder komplett verhindert werden. Sollten aufgrund einer oder mehrerer angewendeter Blocklisten Seiten gesperrt werden, auf die eigentlich zugegriffen werden soll, besteht die Möglichkeit, diese über eine Whitelist explizit für die gewünschten Clients freizugeben.
Technische Voraussetzungen
Um ein eigenes funktionierendes Pi-hole zu installieren, sind nicht viele Komponenten nötig. Die technischen Voraussetzungen sind:
- Ein Raspberry Pi mit Raspberry Pi OS+ Zubehör & Netzteil
- Eine MicroSD-Karte (mindestens 8GB Speicherkapazität)
- Ethernet- oder WiFi-Verbindung (bei Raspis mit WLAN-Modul) zum Router des lokalen Netzwerks, damit Pi-hole als DNS-Server fungieren kann
- Zugang zur Command Line Interface (CLI) des Pi
Die Einrichtung des Raspberry Pi vor der Installation von Pi-hole ist simpel und unkompliziert. Es gibt ausreichend Guides, die diese Arbeit Schritt-für-Schritt erklären.
Installation von Pi-hole
-HINWEIS-
Nach der Installation von Pi-hole kann der Raspberry Pi problemlos ohne Peripheriegeräte betrieben werden. Für den Zugriff auf die Weboberfläche der Anwendung ist jedoch die statische IP-Adresse des Pi nötig, welche über das Terminal des Betriebssystems ausgelesen werden kann. Aus diesem Grund ist es sinnvoll, dass für die Dauer der Installation des Betriebssystems und des Werbeblockers Monitor und Tastatur angeschlossen sind.
Die Pi-hole Installation ist unkompliziert und wird von einem ausführlichen Installationsassistenten begleitet, der jeden Schritt mit einer kurzen Erklärung begleitet. Um das Installationsskript zu starten, muss zunächst das Pi-hole git-Repository geklont werden, in der das Skript enthalten ist. Anschließend wird das Skript ausgeführt. Die entsprechenden Befehle dafür sind:
git clone --depth 1 https://github.com/pi-hole/pi-hole.git Pi-hole cd "Pi-hole/automated install/" sudo bash basic-install.sh
Der automatisierte Pi-hole Installer konfiguriert die Punkte:
- Statische IP-Adresse
- Auswahl des von Pi-hole verwendeten Upstream DNS-Providers
- Einfügen einer ersten, von den Pi-hole-Entwickler:innen kuratierten Blockliste
- Installation des Webinterface (kann ausgeschalten werden, wenn die Konfiguration komplett über SSH und CLI gemacht werden will)
- Installation des Webservers lightttpd (Ist für die Anzeige des Webinterface unerlässlich)
- Privacy level und loggen von Anfragen
Nachdem der Installer seine Arbeit getan hat, ist die Weboberfläche erreichbar und Pi-hole ohne weitere Einstellungen direkt einsetzbar.
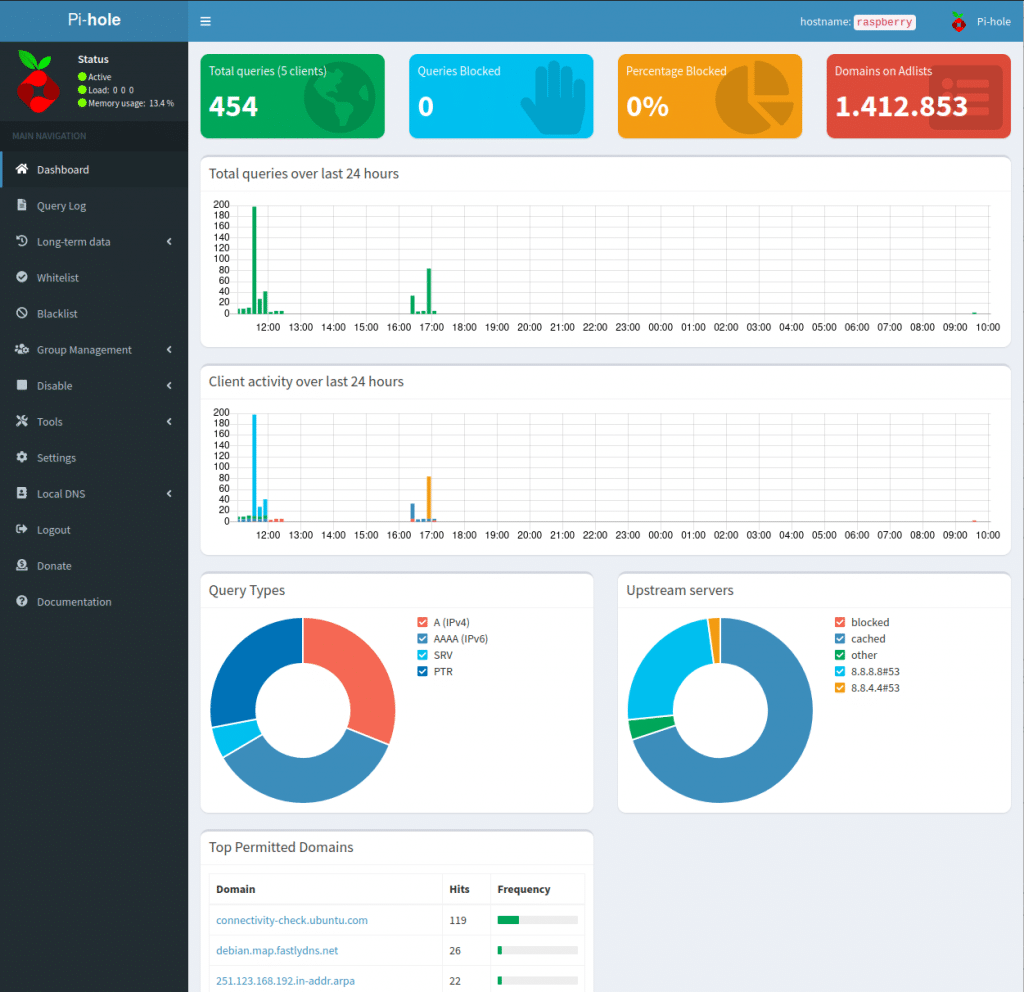
Individuelle Konfiguration von Pi-hole …
Mit der vom Installer vorgegebenen Grundkonfiguration ist der Einsatz des Werbe- und Trackingblocker Pi-hole ohne weitere Einstellungen möglich. Es wäre jedoch kein anständiges Linux- bzw. Open Source-Projekt, wenn es nicht vielfältige Konfigurationsmöglichkeiten geben würde, um Pi-hole an die eigene Umgebung und die persönlichen Präferenzen anzupassen.
Zugriff auf die verschiedenen Konfigurationsmöglichkeiten bekommt man über das Dashboard, welches im Browser über http://IP-Adresse-des-Pi/admin (z. B. 192.168.123.456/admin o. Ä.) aufgerufen werden kann. Nachfolgend werde ich einige wichtige Einstellungen vorstellen.
… als DNS-Server
Wie bereits angesprochen, agiert Pi-hole im lokalen Netzwerk als DNS-Server. Damit das funktioniert, muss im Menü unter Settings -> DNS ein Upstream DNS Server ausgewählt werden, mit dem der Pi kommunizieren kann. Zur Auswahl stehen einige vorkonfigurierte Möglichkeiten (u.A. Google, OpenDNS oder Quad9). Zudem können bis zu vier weitere DNS-Server hinzugefügt werden, indem die entsprechende IP-Adresse eingetragen wird. Somit haben Nutzer die volle Kontrolle über den genutzten Upstream DNS und können z. B. datenschutzfreundliche DNS-Anbieter verwenden.
… und Benutzer- / Gruppenmanagement
Die individuelle Konfigurierbarkeit ist einer der Gründe, warum sich Pi-hole seit Jahren großer Beliebtheit erfreut. Dazu gehört besonders das Benutzer- und Gruppenmanagement.
Du möchtest verschiedene Gruppen anlegen, um für einen oder mehrere Client(s) Content zu sperren, für die anderen aber nicht? Kein Problem!
Du willst einen Client mehreren Gruppen hinzufügen? Kein Problem!
Um individuelle Gruppen anzulegen, muss einfach Group Management -> Groups aufgerufen werden. Die Client-Verwaltung wiederum befindet sich im gleichen Menü jedoch unter dem Unterpunkt Clients.
… und Adlists
Bei der Grundkonfiguration über den Pi-hole-Installer wird eine kuratierte Adlist mitgeliefert, dass Pi-hole direkt einsatzbereit ist. Bei dieser einen Liste muss es aber nicht bleiben. Egal was geblockt werden soll, es gibt die passende Liste dafür. Die folgenden drei Links bieten eine vielfältige Auswahl an regelmäßig aktualisierten Blocklisten:
Eingefügt werden die gewünschten Listen über Group Management -> Adlists. Hier lassen sich alle Listen zentral verwalten (z. B. Kommentare zu einzelnen Listen, Zuweisung zu Nutzergruppen, u.v.m.).
Es existieren noch viele weitere Einstellungsmöglichkeiten wie DHCP, Domainmanagement oder Whitelists, aber diese vorzustellen würde den Rahmen sprengen. Deshalb nun noch ein Punkt, der nicht unerwähnt bleiben sollte.
Grenzen von Pi-hole
Wer bis hierhin gelesen hat, kann den Eindruck bekommen, dass Pi-hole eine großartige Möglichkeit ist, um Werbung und Tracking aus dem eigenen Netzwerk zu verbannen. Und das ist auch zu 95 Prozent richtig. Doch Ehrlichkeit muss sein: NICHT JEDE WERBUNG lässt sich blockieren.
Wenn sich der abgerufene Inhalt und die Werbung den Server und die IP-Adresse teilen, führt ein Blockieren der Werbung zu einem Blockieren des Inhalts. Das bekannteste Beispiel für dieses Vorgehen ist YouTube, dass damit DNS-Werbeblockern wie Pi-hole oder AdGuard Home zuvorkommen will. Um diese Inhalte abzurufen, muss man in den meisten Fällen ein wenig Werbung in Kauf nehmen.
Besonders für Nutzer von Smart-TVs oder TV-Sticks ist das eine bedauerliche Nachricht. (Während es auch hier Optionen gibt, hust SmartTube hust).
Wenn du nun auch Lust auf abwechslungsreiche Projekte in einem modernen IT-Unternehmen im wunderschönen Nürnberg hast und aktuell noch einen spannenden Ausbildungsplatz suchst, dann solltest du noch heute deine Bewerbung an NETWAYS schicken.