Seit einiger Zeit bin ich großer Fan von Wireguard als VPN Lösung um meine Server und Notebooks zu verbinden. Auch Patrick hatte schon mal über DNS Privacy mit Wireguard geschrieben.
Dabei ist mir ein kleines Problem begegnet, Wireguard hat kein automatisches Handling wenn sich Endpoint Adressen über DNS ändern. In meinem Fall verbinde ich:
- Server im Rechenzentrum mit fester IP Adresse
- Notebook irgendwo unterwegs, muss sich zu allen anderen Verbinden
- Server zuhause, Verbindung nur über DynDNS möglich
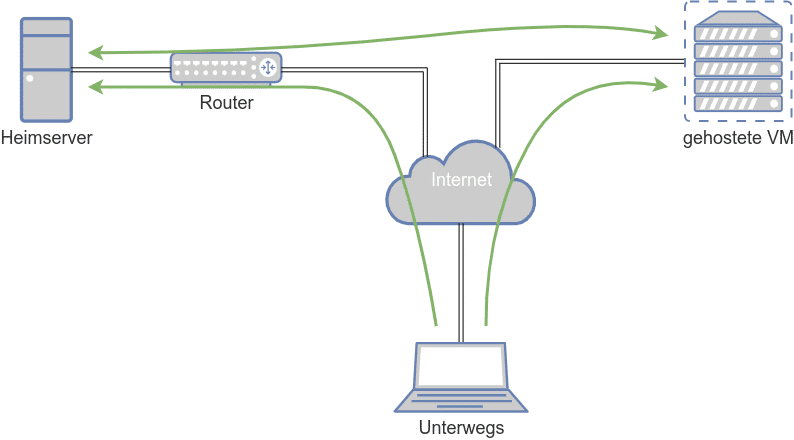
Auf dem Bild kann man in etwa die aufgebauten Verbindungen erkennen, nun besteht das Hauptproblem darin, dass der Server zuhause nur über die Auflösung des dynamischen DNS Namens erreichbar ist. Wireguard löst DNS Namen nur beim laden der Konfiguration auf. Sollte sich die IP Adresse ändern funktioniert die Verbindung nicht mehr.
Ein Beispiel meiner Konfiguration:
[Interface] # Notebook Address = 10.99.0.3/24 PrivateKey = BASE64 ListenPort = 51820 [Peer] # Server at home PublicKey = BASE64 AllowedIPs = 10.99.0.1/32 Endpoint = home.example.com:51820 [Peer] # hosted VM PublicKey = BASE64 AllowedIPs = 10.99.0.2/32 Endpoint = server.example.com:51820 #[Peer] ## Notebook Entry on other nodes #PublicKey = BASE64 #AllowedIPs = 10.99.0.3/32 ## No endpoint defined for this peer
Nachdem Wireguard noch keine eingebaute Lösung dafür hat, braucht man ein Script, welches DNS Namen neu auflöst und dann anwendet. Ich verwende das Beispielskript reresolve-dns.sh aus den contrib Skripten.
Die Installation ist relativ einfach:
curl -LsS -o /usr/local/bin/wireguard-reresolve-dns https://github.com/WireGuard/wireguard-tools/raw/master/contrib/reresolve-dns/reresolve-dns.sh chmod 0755 /usr/local/bin/wireguard-reresolve-dns
Im Anschluss kann das Skript manuell oder per Cron (als root) ausgeführt werden:
wireguard-reresolve-dns wg0
Oder was ich bevorzuge, als Systemd Service und Timer wie folgt.
/etc/systemd/system/wireguard-reresolve-dns.service
[Unit] Description=Wireguard Re-Resolve DNS of endpoints [Service] Type=oneshot ExecStart=/usr/local/bin/wireguard-reresolve-dns wg0
/etc/systemd/system/wireguard-reresolve-dns.timer
[Unit] Description=Runs Wireguard Re-Resolve DNS every 5 Minutes [Timer] OnUnitActiveSec=300s OnActiveSec=300s [Install] WantedBy=multi-user.target
Anschließend muss man den Timer nur aktivieren und kann den Status des Service jederzeit checken:
# systemctl daemon-reload # systemctl enable wireguard-reresolve-dns.timer
# systemctl status wireguard-reresolve-dns.timer * wireguard-reresolve-dns.timer - Runs Wireguard Re-Resolve DNS every 5 Minutes Loaded: loaded (/etc/systemd/system/wireguard-reresolve-dns.timer; enabled; vendor preset: enabled) Active: active (waiting) since Thu 2021-12-30 15:40:09 CET; 6 days ago Trigger: Wed 2022-01-05 15:50:48 CET; 3min 1s left Triggers: * wireguard-reresolve-dns.service Dec 30 15:40:09 notebook systemd[1]: Started Runs Wireguard Re-Resolve DNS every 5 Minutes. # systemctl status wireguard-reresolve-dns.service * wireguard-reresolve-dns.service - Wireguard Re-Resolve DNS of endpoints Loaded: loaded (/etc/systemd/system/wireguard-reresolve-dns.service; static) Active: inactive (dead) since Wed 2022-01-05 15:45:48 CET; 2min 1s ago TriggeredBy: * wireguard-reresolve-dns.timer Process: 3600033 ExecStart=/usr/local/bin/wireguard-reresolve-dns wg0 (code=exited, status=0/SUCCESS) Main PID: 3600033 (code=exited, status=0/SUCCESS) CPU: 17ms Jan 05 15:45:48 notebook systemd[1]: Starting Wireguard Re-Resolve DNS of endpoints... Jan 05 15:45:48 notebook systemd[1]: wireguard-reresolve-dns.service: Succeeded. Jan 05 15:45:48 notebook systemd[1]: Finished Wireguard Re-Resolve DNS of endpoints.
Ich wünsche viel Spaß beim Ausprobieren.
Wer gerne automatisiert, dem kann ich die Ansible Rolle von githubixx empfehlen, so spart man sich das müssige Erstellen und Verteilen von Keys. Leider habe ich noch keine fertige Rolle für reresolve DNS. 😉️
 Just about a week ago I posted a short blog post introducing a new
Just about a week ago I posted a short blog post introducing a new 















