
Observability and monitoring of resources are growing every day and it is inevitable to analyse all the data points to arrive at a solution. At Mercedes-Benz they have developed an Open Source data metric analyzer and drive it with data science to identify anomalies. At OSMC 2022, Satish Karunakaran, a data scientist with 19 years of experience in the field, presented how they established the entire data processing ecosystem based on Open Source.
In the beginning of his talk, Satish immediately questioned how much value can be generated manually out of Big Data, since metrics, logs and traces all provide intelligence. His point was not about scalability, management (manual patching) versus unmanaged (self-healing) here, but how to optimize for prediction and detection of failures.
Following up, the question arose what is normal, and how to determine normality versus abnormality.
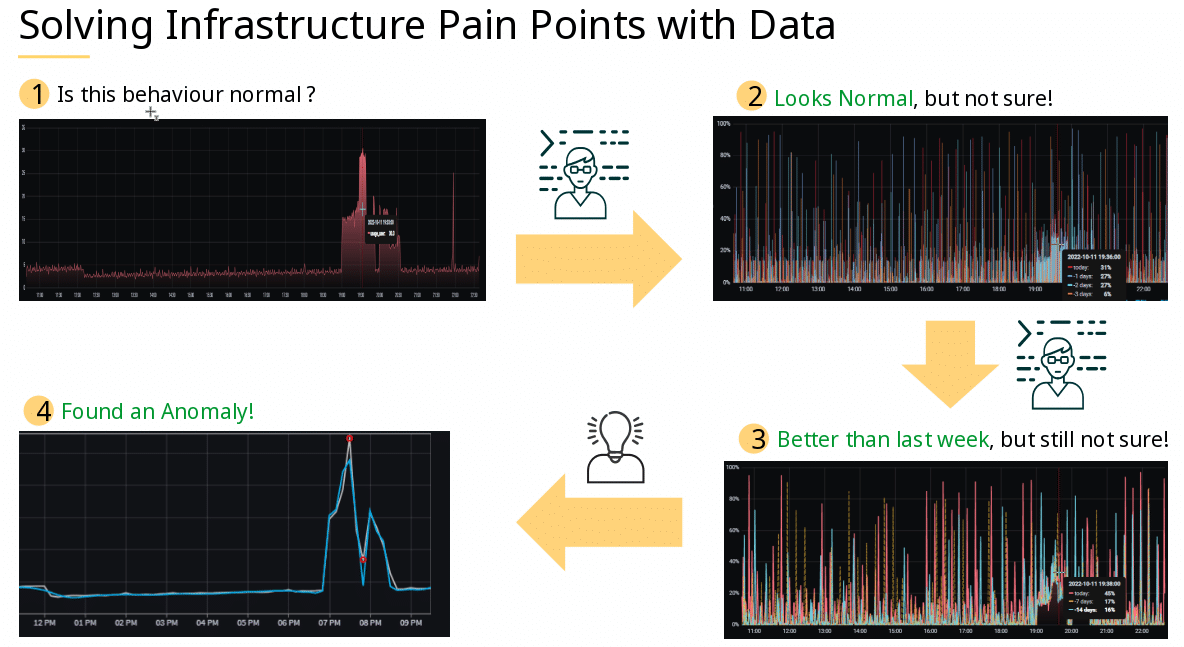
Especially cases of “looks normal, but not sure” or “better than last week, but something is wrong” could be optimized with a data driven approach.
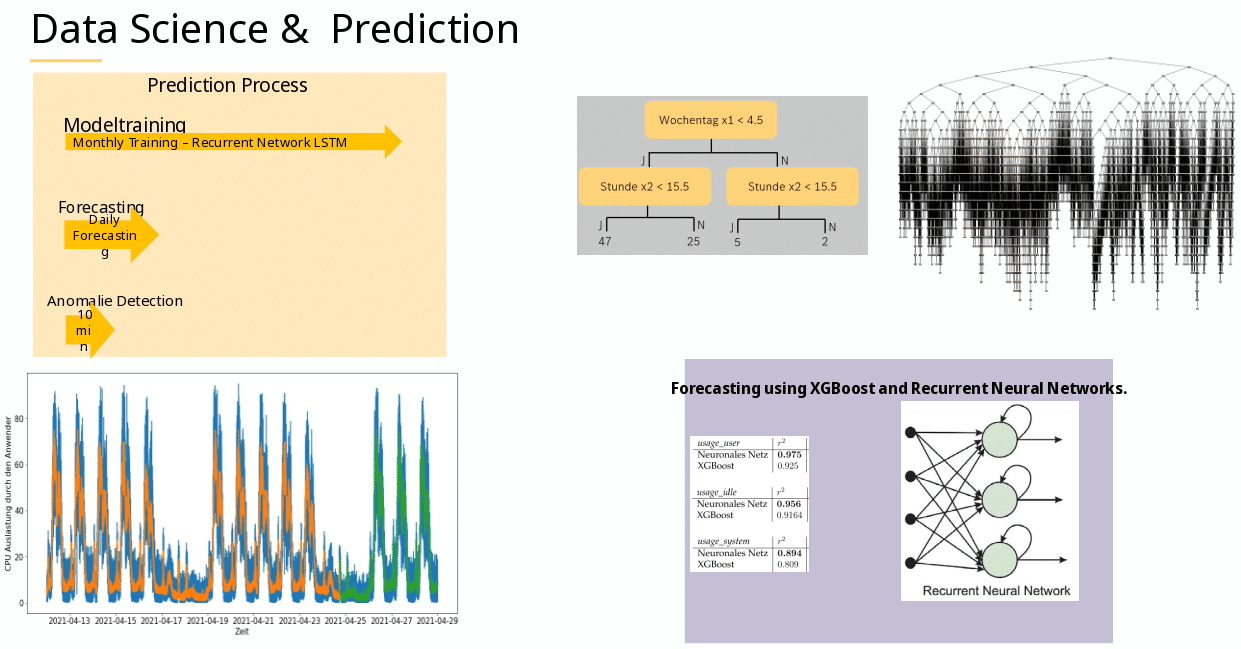
The idea is the following: 1) Collect lots of functional & correct data (as much as possible, as long as possible). 2a) Use lots of nested if conditions: Check if a value / limit ( 3 < 5 = yes ) has been reached, and if so, get more and more granular ( 3 < 4 =yes ) and split up based on previous choices (3 < 3 = false). This is also called a decision-tree. 2b ) Create labelling tags. 2c) Make this process highly parallel via scalable, distributed, gradient-boosted decision trees (XGBoost).
Boosting comes from the idea of improving single weak models by combining them with other weak models, in order to generate a strong model! Gradient boosting is an improved supervised learning variant if this, which takes labeled training data as input, and tries to correctly predict each training example – to label future data.
TLDR: If we know what is healthy, because if we have lots of healthy data, and are able to label / predict each next data point to the real world (not necessarily watching what is happening, but predicting what will happen), and suddenly our predictions do not match, then we have an abnormality and should call an alert! Or, if you prefer to watch an AI explain XGBoost:
This morning I came across a cool demo by @LinusEkenstam about creating animated AI-generated characters. I decided to give it a try, and, with slight modifications, this is what I ended up with. pic.twitter.com/e2vx9OP0Ls
— Bojan Tunguz (@tunguz) January 18, 2023
Unfortunately compared to Neural Nets, XGBoost appears slow and memory intense with many decision-branches, wheares Neural Nets allow scalability and optimization – due to being able to optimize and drop for hidden functions. Additionally, one tries to converge for the maximum (XGBoost), and the other tries to converge for the minimum (Neural Nets). So combining both and getting the best possible tag tag-prediction is the art of someone who does this for quite a long time, like Satish!
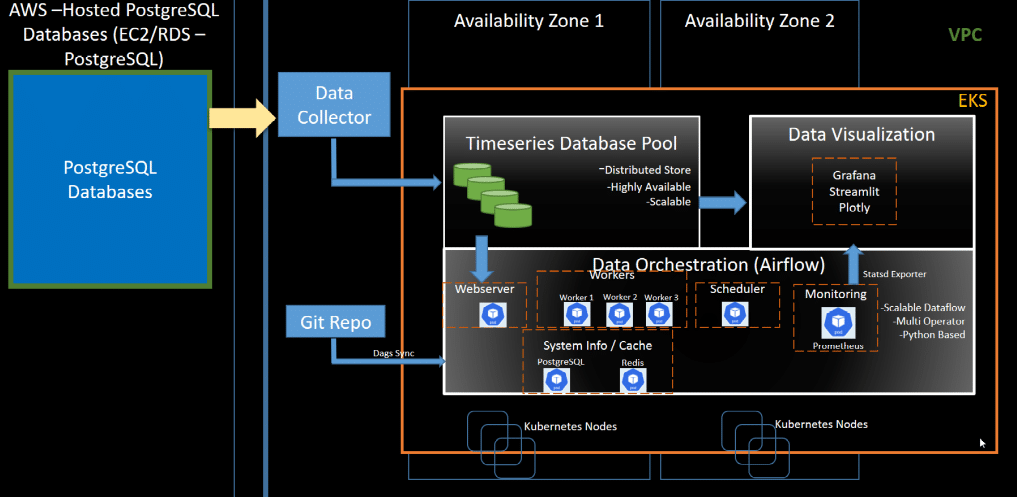
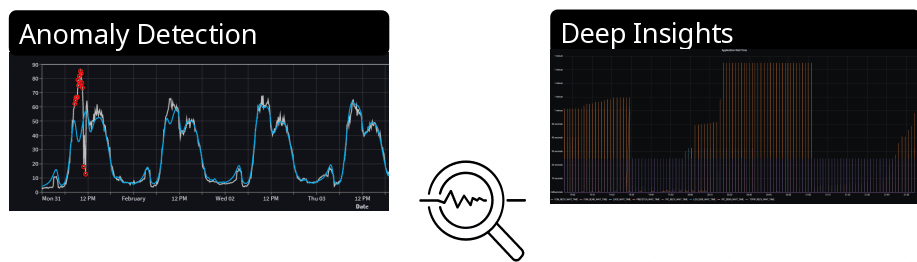
An example of how Satish and his team implemented this can be seen in this picture, which displays the path of data flow, data orchestration and visualization.
Do you think all monitoring should follow an AI based anomaly approach?
Would you find it cool if all monitoring solutions one day would have predictive models? And how would they deal with statistical outliers? Maybe lots of human time wasted could be saved, if we could focus on “the essentials”? Would you like to hear more about about data science & AI at further NETWAYS Events or like to talk to Icinga developers about this fascinating topic? Please feel free to contact us!
The recording and slides of this talk and all other OSMC talks can be found in our Archives. Check it out! We hope to see you around at OSMC 2023! Stay in touch and subscribe to our Newsletter!

















0 Comments