Gerade im Umfeld von Logstash-Pipelines steht man oft vor dem Problem, wie die einzelnen Code Teile zusammenhängen. Dafür hat sich für mich Mermaid bewährt.
Was mir an Mermaid besonders gefällt ist, dass man mit einer relativ einfachen Syntax Graphen definieren kann, die dann in verschiedenen Systemen gerendert werden können. Das kommt meiner Arbeitsweise beim Schreiben von Doku entgegen. Bietet aber auch die Möglichkeit, Konfiguration einfacher automatisch generieren zu lassen. Die Erstellung solcher Abhängigkeiten gestaltet sich damit einfacher als z.B. mit Graphviz. Klar sind die Möglichkeiten etwas eingeschränkt, aber wenn sie genau das bieten, was man braucht, dann stört das auch gar nicht.
Ich nutze den Mermaid Live Editor mittlerweile auch gern während unserer Elastic Stack Logmanagement Schulungen um interaktiv zu zeigen, wie sich eine Pipelinekonstruktion entwickeln kann. Natürlich kann man damit auch den Zusammenhang zwischen Komponenten eines Elastic Stack oder ähnliches wunderbar visualisieren.
Als einfaches Beispiel sei hier ein Setup gezeigt, das in einer Pipeline sowohl syslog als auch journald Events annimmt. Der Header und das Format unterscheiden sich, aber der eigentliche Inhalt ist gleich. Ausserdem sind hier noch zwei Pipelines, die Secure-Log und Cron Lognachrichten weiter zerlegen. Alle anderen Nachrichten werden nur vom Header befreit und gehen vorerst direkt weiter an Elasticsearch.
graph TD
A[shipper] -->|syslog| B[syslog]
A --> C[journald]
B --> D[secure]
C --> D
D --> E[forwarder]
A --> E
B --> E
C --> E
B --> F[Cron]
C --> F
F --> E
Direkt gerendert sieht das dann so aus:
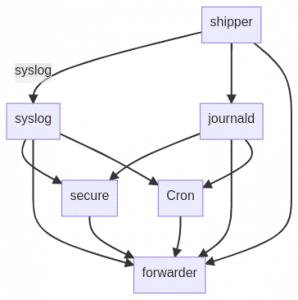
Für die ganz Neugierigen sei noch gesagt, dass die Pfeile hier jeweils eine Übergabe per Redis-Key symbolisieren sollen. Der Übersicht halber wurde hier nur der syslog Key beschriftet. Man kann sich aber vorstellen, dass das entsprechend einfach auch mit den anderen funktionieren würde. Mermaid kümmert sich dann dabei darum, dass der Graph immer wieder so umgebogen wird, dass alles schön lesbar ist.
Die Namen der einzelnen Pipelines, bzw. deren Beschriftung, muss nur einmal angegeben werden. Der Mermaid-interne Name, hier immer nur ein Buchstabe, kann dann immer wieder verwendet werden, ohne den Namen jedesmal wieder anzugeben. Natürlich kann man sich auch die Zeit nehmen, die internen Namen sprechender zu gestalten, was durchaus für Übersicht sorgt.
Mermaid ist ein JS Projekt, das sich auch in andere Tools wie Wikisoftware integrieren lässt.
Und, Spoiler Alert!, Pipelines, die hier dargestellt werden, befinden sich auch recht aktiv in Entwicklung und sind für die Veröffentlichung geplant. Es gibt jetzt mit dem Elastic Common Schema endlich eine Nomenklatur für Felder, die es erlaubt, wiederverwendbare Pipelines zu bauen. Bei früheren Versionen war ja immer das das große Problem. Wenn jedes Setup ein Feld für den selben Inhalt beliebig benennen kann, wird’s schwierig mit dem wiederverwenden von Code. Das ist jetzt vorbei und wir versuchen, entsprechend Code zu produzieren.