da die meisten User sich zwar mit MySQL oder MariaDB auskennen, werde ich heute mal auf PostgreSQL eingehen, wie man dieses Paket installiert und ein paar Kommandos zur Verwaltung einer Datenbank.
PostgeSQL ist von den Kommandos ähnlich wie zum Beispiel MariaDB. Sie wird auch als ein freies, objektrelationales Datenbankmanagementsystem (ORDBMS) betitelt, somit auch Opensource ist.
Installation unter openSUSE-Leap 15.2:
Pakete sind in den offiziellen Repositories zu finden, die bei dem Setup von openSUSE-Leap gesetzt werden.
# sudo zypper in postgresql postgresql-server
Da da der Dienst von PostgreSQL nicht automatisch gestartet wird, wie z.B bei Debian basierten Linux-Distributionen muß dieser noch gestartet werden
# sudo systemctl start postgresql
Am besten prüft man nochmal ob der Dienst auch fehlerfrei läuft
# sudo systemctl status postgresql
● postgresql.service - PostgreSQL database server Loaded: loaded (/usr/lib/systemd/system/postgresql.service; disabled; vendor preset: disabled) Active: active (running) since Tue 2020-11-03 08:31:17 UTC; 4h 23min ago Main PID: 1460 (postgres) Tasks: 8 CGroup: /system.slice/postgresql.service ├─1460 /usr/lib/postgresql12/bin/postgres -D /var/lib/pgsql/data ├─1461 postgres: logger ├─1463 postgres: checkpointer ├─1464 postgres: background writer ├─1465 postgres: walwriter ├─1466 postgres: autovacuum launcher ├─1467 postgres: stats collector └─1468 postgres: logical replication launcher Nov 03 08:31:15 opensuse-leap systemd[1]: Starting PostgreSQL database server... Nov 03 08:31:15 opensuse-leap postgresql-script[1437]: Initializing PostgreSQL 12.4 at location /var/lib/pgsql/data Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.186 UTC [1460]LOG: starting PostgreSQL 12.4 on x86_64-suse-linux-gnu, compiled by gcc (SUSE L> Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.187 UTC [1460]LOG: listening on IPv6 address "::1", port 5432 Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.187 UTC [1460]LOG: listening on IPv4 address "127.0.0.1", port 5432 Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.193 UTC [1460]LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432" Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.204 UTC [1460]LOG: listening on Unix socket "/tmp/.s.PGSQL.5432" Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.221 UTC [1460]LOG: redirecting log output to logging collector process Nov 03 08:31:17 opensuse-leap postgresql-script[1437]: 2020-11-03 08:31:17.221 UTC [1460]HINT: Future log output will appear in directory "log". Nov 03 08:31:17 opensuse-leap systemd[1]: Started PostgreSQL database server.
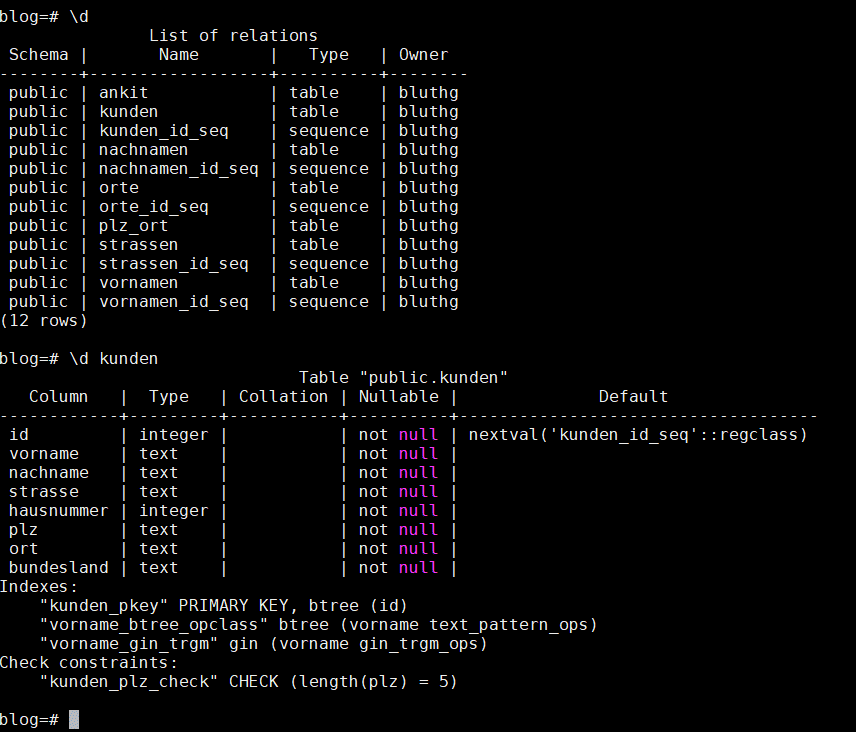
Da wir jetzt wissen, das der Dienst ordnungsgemäß läuft, können wir loslegen, mit dem anlegen von der Datenbank und Tabellen.
PostgreSQL wird vom System-User postgres verwaltet, der alle Rechte hat, um z.B. Datenbanken oder auch Datenbankbenutzer anzulegen. Da dieser User ohne Passwort konfiguriert ist, was unter MariaDB oder MySQL teilweise auch so ist, sollte man dem User sicherheitstechnisch ein Passwort konfigurieren.
# sudo passwd postgres
Passwort nach Aufforderung eingeben und erneut wiederholen.
Unter PostgreSQL gibt es genauso ein Shell wie bei z.B. MySQL und in diese kommt man wie folgt:
# sudo -u postgres psql
Um diese Shell wieder zu verlassen
\q
eingeben
Anlegen vom User der Datenbanken verwalten darf
# sudo sudo -u postgres createuser -P -d NUTZERNAME
Der Schalter -P <password> -d <create databases>
Anlegen von einer Datenbank
# sudo -u postgres createdb -O username DATABASENAME
Löschen einer Datenbank
# sudo -u postgress dropdb DATABASE In der postgresql Shell sieht das anders aus postgres=# CREATE DATABASE my_music;
Wechseln zwischen den Datenbanken
\c DATENBANK
Ein Tabelle mit den Spalten anlegen
postgres=# CREATE TABLE cds ( id int, interpreter varchar(100), album varchar(100), release date );
Daten in die Tabelle der Datenbank schreiben
INSERT INTO cds VALUES ( 1, 'Pretty Maids', 'Future World', '1987-04-12' );
Ausgeben der Daten
my_music=# select * from cds; id | interpreter | album | release ----+--------------+--------------------+------------ 1 | Pretty Maids | Future World | 1987-04-12 2 | Metallica | Ride the Lightning | 1984-04-12 (2 rows)
Als kleine Einführung in PostgreSQL sollte das erst mal ausreichen, für mehr Wissen darüber bieten wir von NETWAYS auch eine PostgreSQL Schulung an.
Dann viel Spaß bei ausprobieren von PostgreSQL auf openSUSE.