Lange Zeit waren die Auftragnehmer der Raumfahrt große Rüstungskonzerne mit eingefahrenen Strukturen und dem entsprechenden Produkten. Die Raketen waren bspw. nicht gerade dazu gedacht, sie wieder zu verwenden. Wahrscheinlich konnte sich kaum einer der Auftraggeber vorstellen, dass das auch ganz anders geht. Und dann kam Elon Musk und hat “mal eben” SpaceX auf die Beine gestellt… und dann gingen viele Dinge auf einmal viel besser. So ähnlich auch in unserer Branche…
Lange Zeit gab es zwar maschinennahe Programmiersprachen, aber diese waren umständlich in der Handhabung – insbesondere im Hinblick auf die parallele Ausführung mehrerer Aufgaben. Die konstante Größe der Thread-Stacks limitierte zusätzlich die Anzahl der Threads, so dass bspw. das in C++ geschriebene Icinga 2 aktuell die E/A auf einige wenige Threads verteilen muss. Seit 2009 gibt es immerhin NodeJS, das gut und gerne viele E/A-Aufgaben parallel ausführt, aber auch nur diese – für Rechenoperationen steht nur ein Thread zur Verfügung. Zudem sind die Typen und Funktionen dynamisch und damit nicht so maschinennah und performant wie bspw. in C++. Und da saßen die Programmierer bis 2012 zwischen diesen zwei Stühlen. Und dann hat Google 2012 die erste stabile Version von Go veröffentlicht… und damit gingen viele Dinge auf einmal viel besser. So auch mittlerweile bei NETWAYS…
Und was macht dieses Go jetzt besser als alle anderen?
Wie mein Kollege Florian sagen würde: “So einiges.” Aber Scherz beiseite…
Go ist maschinennah – d.h. die Typen und Funktionen sind allesamt statisch und werden wie auch bei bspw. C++ im voraus in Maschinencode umgewandelt – mehr Performance geht nicht.
Go ist einfach (obwohl es maschinennah ist). Die Datentypen sind zwar statisch, also explizit, aber deren Angabe ist nur so explizit wie nötig:
type IcingaStatus struct {
Name, Description string
}
var IcingaStatusSet = map[uint8]IcingaStatus{
0: {"OK", "Alles im grünen Bereich"},
1: {"WARNING", "Die Ruhe vor dem Sturm"},
2: {"CRITICAL", "Sämtliche Infrastruktur im Eimer"},
3: {"UNKNOWN", "Mein Name ist Hase, ich weiß von nichts"},
}
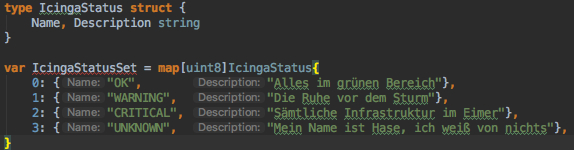
Im gerade gezeigten Beispiel muss der Datentyp der Map-Variable nur einmal angegeben werden. Weder die Typen der enthaltenen Werte, noch deren Felder müssen angegeben werden – sie werden vom Typ der Map abgeleitet. Wer befürchtet, den Überblick zu verlieren, kann auf die IDE GoLand zurückgreifen:
Go ist relativ sicher vor Unfällen (obwohl es maschinennah ist). Bei Zugriff auf eine Stelle eines Arrays, die gar nicht existiert oder unzulässiger Umwandlung von Zeiger-Datentypen wirft Go einen Fehler, um Schäden durch Programmierfehler abzuwenden:
type Laptop struct {
DvdDrive uint32
}
func (l *Laptop) DoSomethingUseful() {
}
type SmartPhone struct {
SimSlot uint16
}
func (s *SmartPhone) DoSomethingUseful() {
}
type Computer interface {
DoSomethingUseful()
}
func main() {
var computers = []Computer{&Laptop{}, &Laptop{}, &Laptop{}}
_ = computers[3]
var computer Computer = &Laptop{}
_ = computer.(*SmartPhone)
}
Go erledigt von sich aus E/A-Aufgaben effizient (obwohl es nicht NodeJS ist). Aufgaben werden in Go nicht über Threads parallelisiert, sondern über sog. Go-Routinen (das gleiche in grün). Diese werden von Go selbst auf die eigentlichen Threads verteilt. Wenn eine Go-Routine eine blockierende E/A-Operation ausführt, wird diese transparent im Hintergrund vollzogen und eine andere Go-Routine beansprucht währenddessen den Thread.
Der Himmel ist die Grenze der Parallelisierung dank Scheduler und dynamischer Stack-Größe. Die o.g. Verteilung von Go-Routinen auf Threads verantwortet der sog. Scheduler von Go. Dies führt dazu, dass “zu” viele parallele Aufgaben sich und dem Rest des Systems nicht im Weg stehen. Zudem beansprucht jede Go-Routine nur soviel RAM wie sie auch wirklich braucht, d.h. eigentlich kann ein Programmierer so viele Go-Routinen starten wie er lustig ist (Beispiel). “Eigentlich” ist genau das richtige Stichwort, denn trotzdem sollte jeder Einzelfall für sich betrachtet werden. Ansonsten macht das OS irgendwann git push --feierabend (Beispiel).
Go geht einfach (daher kommt wahrscheinlich auch der Name). Im Gegensatz zu etablierten maschinennahen Sprachen muss ich mich nicht darum kümmern, dass libfoobar23.dll an der richtigen Stelle in der korrekten Version vorliegt. Das Ergebnis eines Go-Kompiliervorgangs ist eine Binary, die nichtmal gegen libc gelinked ist:
root@576214afd7e6:/# cat example.go
package main
func main() {
}
root@576214afd7e6:/# go build -o example example.go
root@576214afd7e6:/# ./example
root@576214afd7e6:/# ldd ./example
not a dynamic executable
root@576214afd7e6:/#
Alles kann, nichts muss. Go muss ja nicht von heute auf Morgen in sämtlichen Applikationen Anwendung finden. Man kann auch mit einem einzigen Programm anfangen, das nicht heute, jetzt und eigentlich schon vorgestern fertig sein muss. Und selbst wenn nicht alles beim ersten Mal klappt, bieten wir Ihnen gerne maßgeschneidertes Consulting an.