In diesem Jahr konnten wir endlich wieder mehr Vor-Ort Trainings durchführen als in den vergangenen Jahren und sogar vereinzelte Inhouse-Trainings bei Kunden waren möglich. Bisher haben wir bei unseren Präsenztrainings oder auch -workshops auf Notebooks mit CentOS 7 gesetzt, und zwar deshalb weil die automatische Provisionierung durch unseren sog. “Event”-Foreman in Kombination mit Puppet seit langer Zeit gut funktioniert.
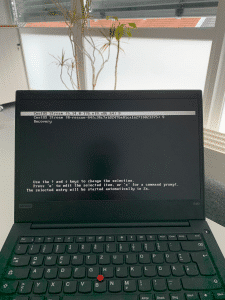
Recovery-Eintrag
Da es in der Vergangenheit für die Kollegen allerdings sehr aufwändig war die Notebooks nach jedem Training wieder ins Büro zu schleppen, sie zu verkabeln und sie dann von Grund auf neu zu installieren, haben wir uns einen Trick einfallen lassen: Nach der automatischen Grundinstallation des Betriebssystems wird ein LVM-Snapshot des Base Images erstellt. Grob gesagt heißt das der Stand des Base Images wird eingefroren und alles was neu hinzukommt bzw. verändert wird (z.B. individuelle Schulungsvorbereitungen für verschiedene Trainings) belegt zusätzlichen Plattenplatz. Damit lässt sich das ursprüngliche Base Image ohne Neuinstallation eines Notebooks schnell wieder herstellen und kann so auf das nächste Training angepasst werden.
Ein weiterer Vorteil des Ganzen ist das die Schulungsteilnehmer ihre Arbeitsumgebung so gestalten können wie sie möchten und beispielsweise auch uns nicht bekannte Passwörter setzen können, mit dem Löschen des LVM-Snapshots ist alles wieder vergessen. Um es auch technisch nicht so affinen Kollegen einfach möglich zu machen Notebooks “zurückzusetzen”, gibt es hierfür beim Booten unser Schulungsnotebooks einen “Recovery”-Eintrag im GRUB-Bootloader der den LVM-Snapshot des Base Images ohne jedes Zutun zurückspielt und das Notebook anschließend neu startet.
Wie kommen aber nun die individuellen Schulungsvorbereitungen auf die Notebooks? Ist die Frage die wir uns auch gestellt haben. Individuelle Schulungsvorbereitungen können z.B. die virtuelle Maschine(n) für das Training sein, meistens auf Basis von Virtual Box, SSH Keys, Hosteinträge, bestimmte Browser oder andere Applikationen um den Schulungsteilnehmern die praktischen Übungen überhaupt möglich bzw. so einfach wie nur denkbar zu machen. Sie in den Provisionierungsprozess einzubauen scheidet ja aus, da die Notebooks wenn überhaupt nur unregelmäßig neu installiert werden sollen.
Also haben wir uns auch hier etwas überlegt: Wir haben im allgemeinem Base Image ein Bash-Skript mit einem statischen Link zur Nextcloud abgelegt. Dort findet sich ein weiteres Skript das auf die aktuell angebotenen Trainings und die jeweils dafür benötigten Schulungsvorbereitungen verweist. D.h. hier liegen beispielsweise dann auch die aktuellen virtuellen Maschinen. Um das Ganze auf den Notebooks umzusetzen verwenden wir wieder Puppet, hier war die Transition leichter da wir das in der Vergangenheit so ähnlich eh schon im Foreman hatten. Damit auch jeder der Kollegen ein Notebook individualisieren kann, gibt’s hierfür natürlich auch einfache Auswahldialoge. Wurde ein Notebook für ein bestimmtes Training vorbereitet, so löscht sich das Skript zur Vorbereitung und kann erst nach dem Recovery wieder ausgeführt werden.
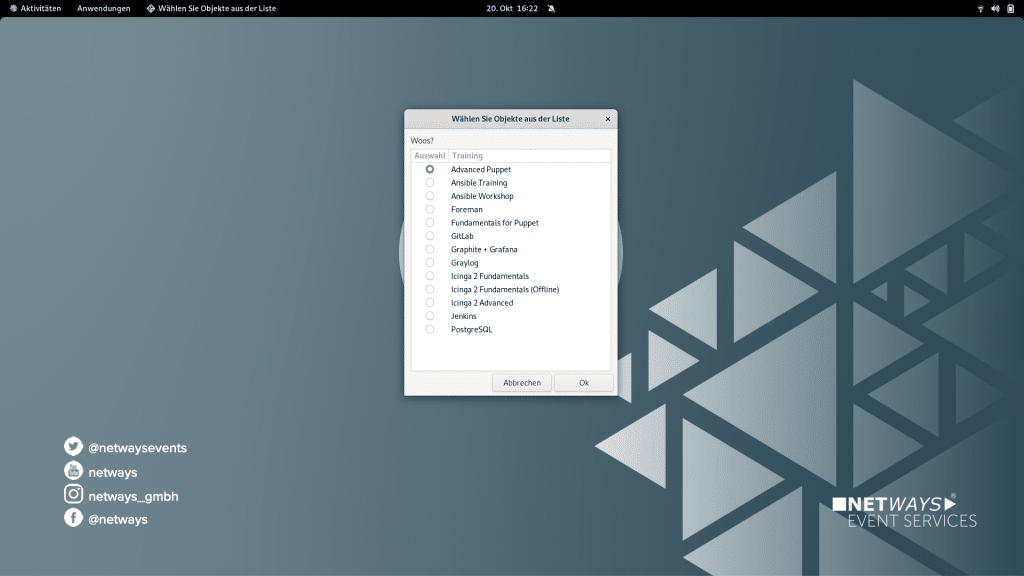
Beispielhafter Auswahldialog für individuelle Schulungsvorbereitung (teils mit historischen Trainings)
Das alles sollte nun natürlich auch weiterhin funktionieren. Da CentOS 7 ab 2024 keine Maintenance Updates mehr bekommt und wir bei manchen Schulungen die nativ auf den Notebooks durchgeführt werden auch etwas mit den veralteten Versionsständen zu kämpfen haben, fiel unsere Entscheidung auf CentOS Stream 9 als neues Betriebssystem für unsere Schulungsnotebooks. Damit wir überhaupt dran denken konnten CentOS Stream zu provisionieren musste erstmal das Debian auf unserem “Event”-Foreman angehoben werden, danach folgten viele kleine Updates von Foreman 1.22 bis zum aktuellen Release 3.4.0 und auch Puppet bzw. die Puppetmodule mussten aktualisiert werden. Im Foreman selbst waren die Mirrors für CentOS Stream einzurichten, Bereitstellungsvorlagen anzupassen und auch die Partitionierung haben wir aufgrund der gestiegenen Plattenkapazität der Notebooks adaptiert. Für einen automatischen Ablauf der Provisionierung nutzen wir das Foreman Discovery Plugin.
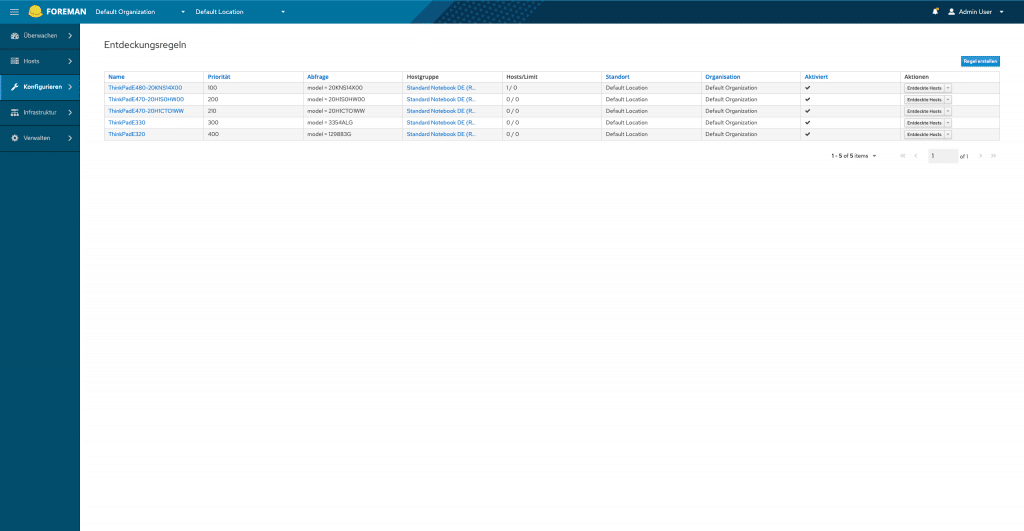
Foreman Discovery der Schulungsnotebooks
Wer sich nun selbst ein Bild von unseren Schulungsnotebooks machen möchte, dem kann ich natürlich auch nicht nur deswegen eines unserer Trainings oder einen unserer angebotenen Workshops ans Herz legen. Vielleicht auch im Zuge der diesjährigen OSMC (Open Source Monitoring Conference).




















