![]() To provide features like login or persistence to the user, stateless protocols like HTTP depend heavily on sessions. Almost every web application is using it.
To provide features like login or persistence to the user, stateless protocols like HTTP depend heavily on sessions. Almost every web application is using it.
An easy job you would say? Of course! But what about high availability setups with hundreds of concurrent users? And sessions need to be shared between application servers so that that users do not lose their current login session.
RT’s vanilla way is to put this in MySQL which produces queries on every request. Second bad thing is the created GET_LOCK query which slows down the environment after a while.
Better way is to use files because file sessions are extremely fast. No network overhead and not greatly influenced by differential IO. But then you have to share sessions between application servers and you should say good bye to that idea because we do not live in an ideal world and shared file systems are terribly slow.
What Next?
I opt for Redis. Meanwhile available on every system, fast as the LHC in Geneva and rock-solid like carbon. Redis is so adorable simple that you only can fall in love with this single-core-minimal-footprint-key-value-store thingy. But I’ll stop hallowing now.
RequestTracker uses Apache::Session::* default implementation and we choose the NoSQL module from there which provides access to Apache Cassandra and Redis.
Configuration Examples
[perl]# Annouce Redis to RequestTracker
Set($WebSessionClass, "Apache::Session::Redis");
# Single server
Set(%WebSessionProperties,
server => ‘127.0.0.1:6379’
);
# Sentinel
Set(%WebSessionProperties,
sentinels => [ ‘127.0.0.1:26379’ ],
service => ‘mymaster’,
sentinels_cnx_timeout => 0.1,
sentinels_read_timeout => 1,
sentinels_write_timeout => 1
);
[/perl]
You can find more information in the product documentation.
Conclusion
It’s just a glimpse, but there a lot of ways to bring RequestTracker to enterprise level with more than 300 concurrent users and millions of tickets and attachments. Of course, highly available and scaled in every direction. You only need to ask us how to do!

 Es gibt einen ganzen Haufen Müll im Weltraum den man praktischerweise nicht sieht und sich aus diesem Grund wenig Gedanken darum macht. Das Inter-Agency Space Debris Coordination Committee (IADC) überwacht im Moment ca. 80000 Objekte ab der Größe eines Fußballs. Nimmt man kleinere Teile inklusive Partikel in der Größe mehrerer Millimeter hinzu, gehen Schätzungen mittlerweile von mehreren Millionen Teilchen in verschiedenen Umlaufbahnen aus. Durch eine Art Domino Effekt (
Es gibt einen ganzen Haufen Müll im Weltraum den man praktischerweise nicht sieht und sich aus diesem Grund wenig Gedanken darum macht. Das Inter-Agency Space Debris Coordination Committee (IADC) überwacht im Moment ca. 80000 Objekte ab der Größe eines Fußballs. Nimmt man kleinere Teile inklusive Partikel in der Größe mehrerer Millimeter hinzu, gehen Schätzungen mittlerweile von mehreren Millionen Teilchen in verschiedenen Umlaufbahnen aus. Durch eine Art Domino Effekt (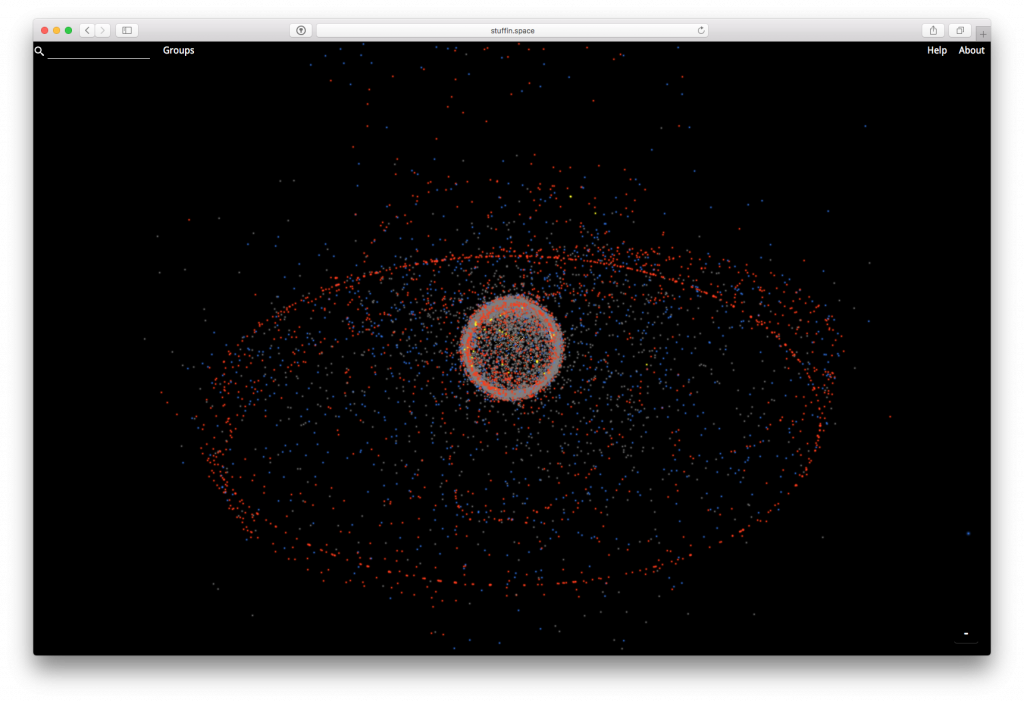
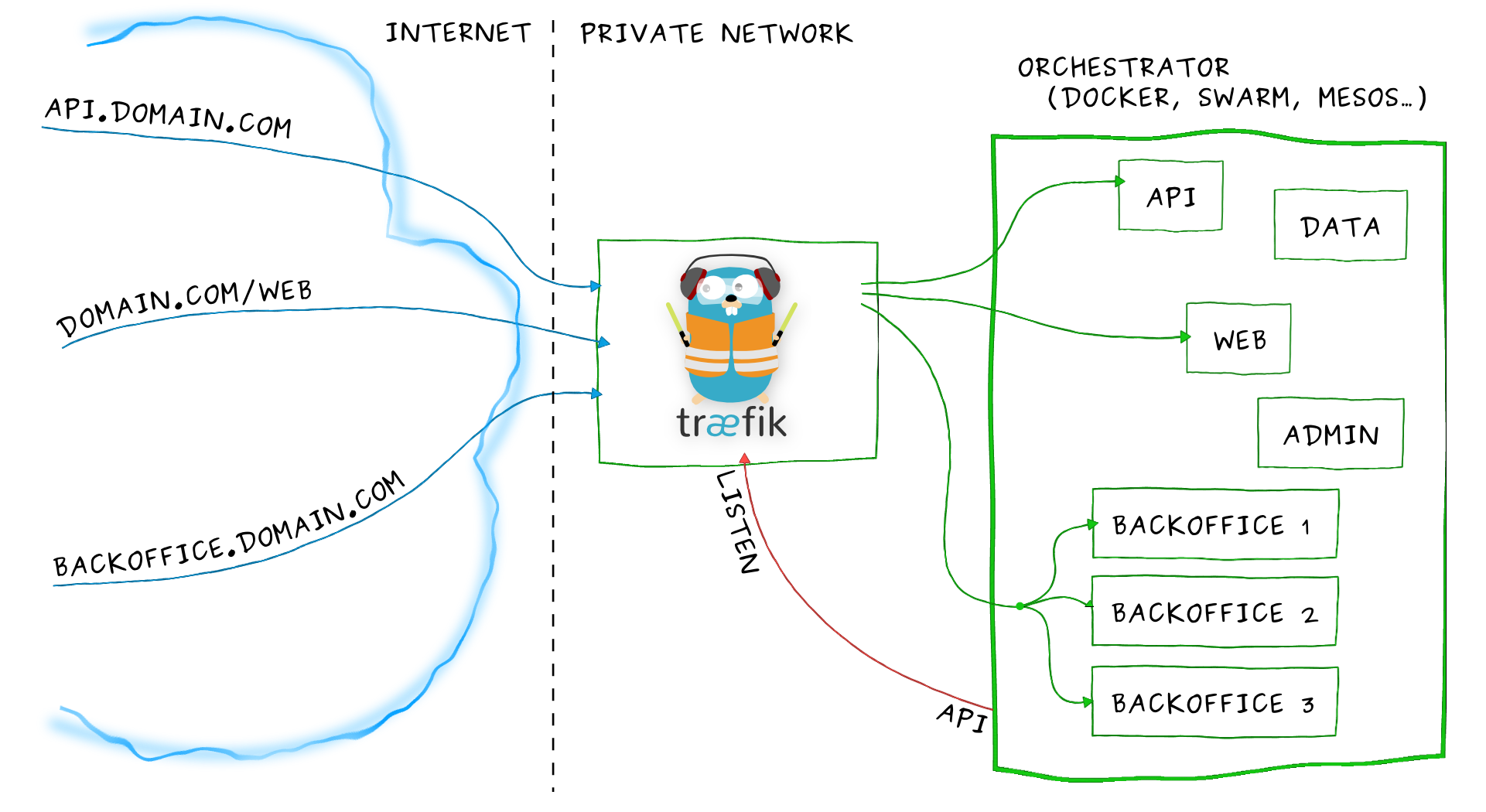
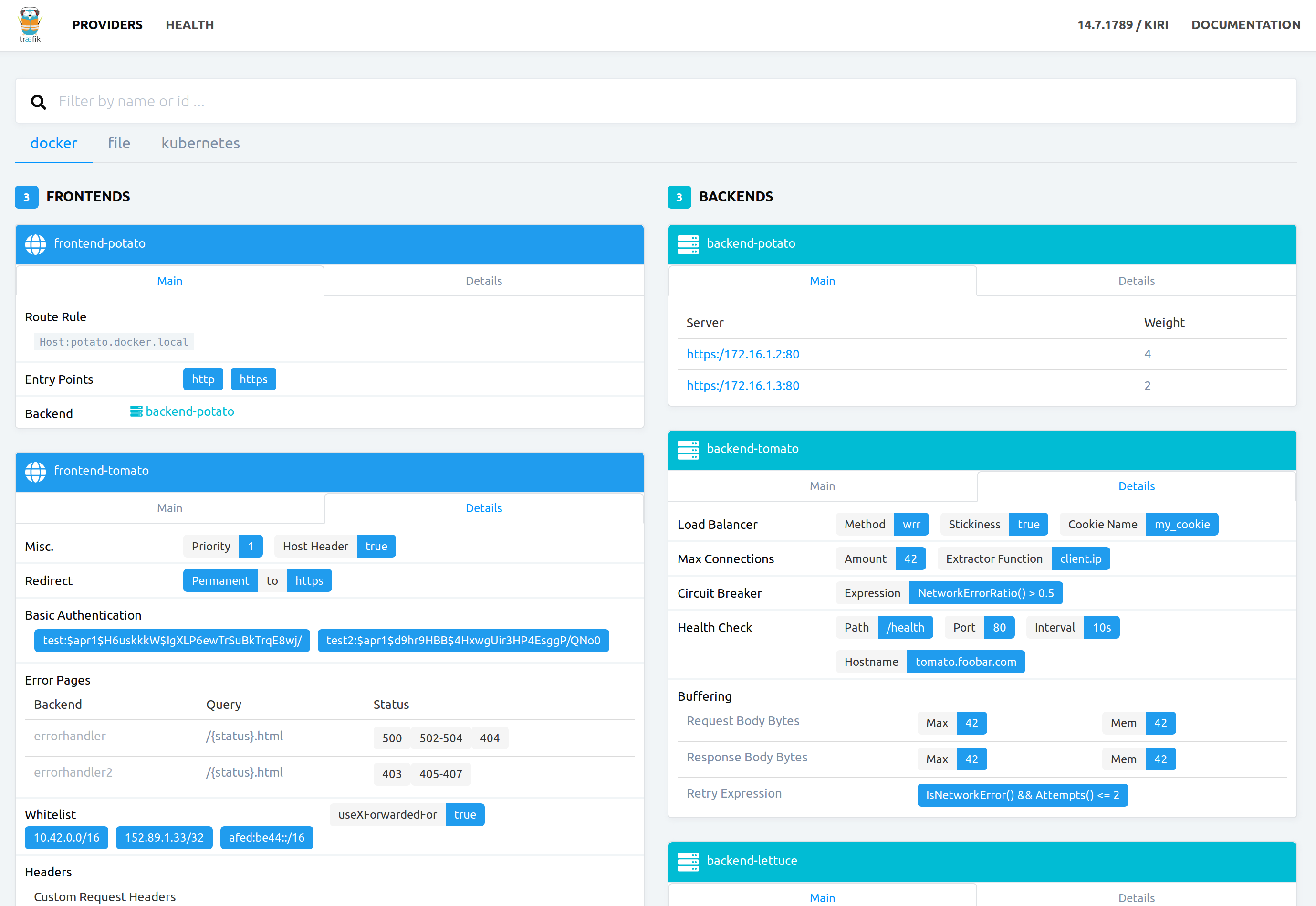
 Mal ehrlich, wer hat denn kein Facebook Profil, ist nicht bei LinkedIn, WhatsApp oder Twitter? Ich vermute: Die wenigsten! Denn ohne geht es heute kaum noch. Da werden Termine nur noch über Gruppen kommuniziert oder der Arbeitgeber macht sich ein Bild über einen potentiellen Bewerber. Man will ja dabei sein, sich gut verkaufen, nicht wahr?
Mal ehrlich, wer hat denn kein Facebook Profil, ist nicht bei LinkedIn, WhatsApp oder Twitter? Ich vermute: Die wenigsten! Denn ohne geht es heute kaum noch. Da werden Termine nur noch über Gruppen kommuniziert oder der Arbeitgeber macht sich ein Bild über einen potentiellen Bewerber. Man will ja dabei sein, sich gut verkaufen, nicht wahr?
















