At the Open Source Monitoring Conference (OSMC) 2019 in Nuremberg, Francesco Cina and Patrick Zambelli whirled up a „Tornado – Extend Icinga 2 for active and passive Monitoring of complex heterogeneous IT Environments”. If you missed their presentation: See the video of their introduction to Tornado and its use cases, and read a summary (below).
The OSMC is the annual meeting of international monitoring experts, where future trends and objectives are set. Since 2006 the event takes place every autumn in Nuremberg, Germany. Leading specialists present the full scope of Open Source monitoring and be ready to answer your hardest questions. Learn new techniques, exchange knowledge and discuss with top developers.
In-depth workshops the day prior to the conference and a Hackathon provide further possibilities to extend your skills and deepen your knowledge in IT monitoring and management.
The next OSMC takes place in 2021 in Nuremberg.
More information at osmc.de.
Tornado – Extend Icinga 2 for Active and passive Monitoring of complex heterogeneous IT Environments
Monitoring Challenges: Pool vs. Event.
First of all we have to explain the difference between Pool and Event approach. Icinga and nagios use the polling approach, which is scheduling monitoring or checks in a static time interval to get a specific state. You can derive from this state if the status from monitored device or service is critical or ok. That means, we know not only the results of monitoring but also the monitored systems. By Polling we have centralized configuration and control. This will be performed either agentless e.g. SHH, SNMP or through an agent for example Icinga, NSClient++.
Contrarily to this historical approach is the event based approach. On the one side we accept the matrix all the time from the remote system and we don’t know exactly what will come, but on another side we have to understand the incoming protocol and derive if there is a problem or not.
Advantages and disadvantages of polling and event:
Polling Pros
- Control when a check should be executed
- Get only the data which you are interested in
- Knowing the context from the system you are interacting with (context = host, service, performance data)
Polling Cons
- Static configuration for monitored architecture (not good for a changeable one e.g. micro services)
- Continuously usage of resources day and night
- Not all data is retrievable via polling
Event Pros
- No delay to react when event happens
- No need to know what to receive but understand it
- Dynamic on fast changing architecture
- Listen to channel => new added hosts are integrated
Event Cons
- Need to face large amount of data (peaks)
- Lack for filtering at source. We can lose information specially when the protocol is not reliable e.g. UDP or SNMP
- Risk to lose information
- Not the right approach for host alive and service availability
Combination of both Polling (Icinga 2) and event (Tornado) will definitive a winning:
With Icinga 2 we have the advantage to start a project very quickly and easily. We have a wide range of checks in the community. Through Templates we can create a reusable monitoring. We can adapt to changes in the architecture by interacting with CMDB or domain controller for example.
With Tornado we listen on the monitored host to the output of a service on a specific channel then we convert this output via collector to Json, which is the only recognized language by Tornado. After that we compare the flow with by regular expression created rules. In the end we forward an action to Icinga 2 – “Critical” for example.
That means, when our infrastructure grows with new hosts we can monitor the availability from these hosts and their services with Icinga 2. We can control the output from services with Tornado.
How to handle the increased load?
01. Scale the monitoring system horizontally
When our servers and services grow, we can increase the number of monitoring instances. This is not good because it doesn’t work out of the box and too many problems will appear. Moreover the throughput does not go linearly. At a number of scaled nodes the overhead of communication and sycronization between them will take more time than analyzing the traffic itself.
02. Use a big data system
We put a big data system between events and the monitoring system, for example kafka, spark, cassandra. The idea is, we reprocess the messages or the events and send only the important ones to the monitoring system. In this way we will reduce the flow against our monitoring system. This will definitely lead to reduce the load as well. It is a real solution but terribly expensive and needs a lot of knowledge with the used data system.
03. Tornado
Why is Tornado the solution?
- Can handle millions of events per second per CPU
- Stateless: the nodes don’t need to communicate to each other
- Cloud-ready
- Has collectors which translate events from format X to Tornado format (Json)
- Take decision based on the event content
- Cheap because it doesn’t need too much resources
Tornado decides to pass the events to Icinga when they match the pipelines and the rules we defined in Tornado. Not suitable events will be dropped.
You liked this blog post and want to read more about different monitoring solutions? Then browse through our blog series, visit our YouTube channel or just contact us.

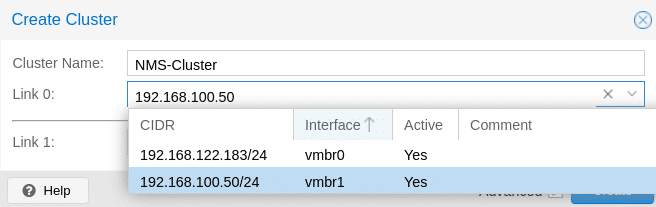
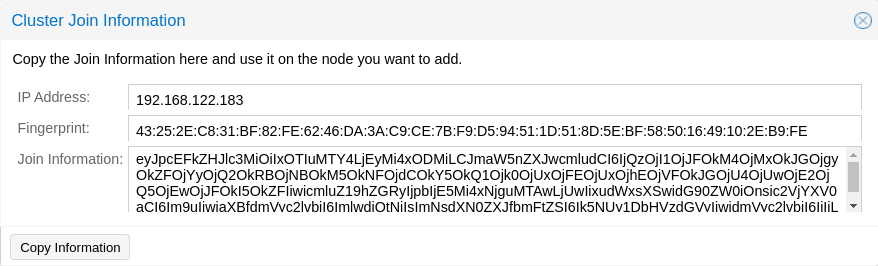
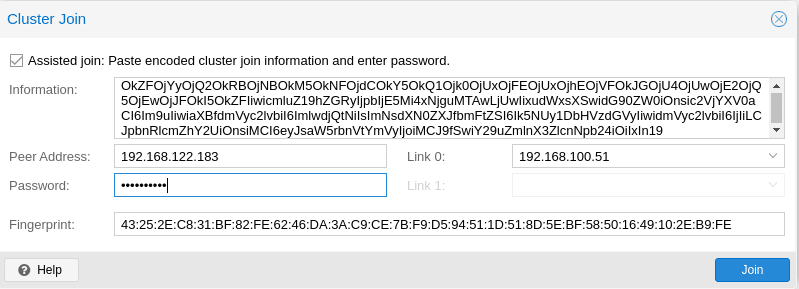
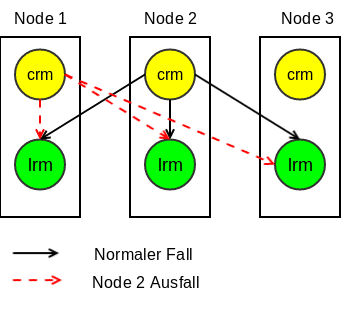 Man kann aus verschiedenen Nodes ein Cluster aufbauen, so dass die Hochverfügbarkeit der Gäste und Lastverteilung gesichert ist (mindestens 3 Nodes werden empfohlen). Pve-cluster ist der wichtigste Service im
Man kann aus verschiedenen Nodes ein Cluster aufbauen, so dass die Hochverfügbarkeit der Gäste und Lastverteilung gesichert ist (mindestens 3 Nodes werden empfohlen). Pve-cluster ist der wichtigste Service im