Das folgende Setup hat sich als Entwurf bei einem Kundenprojekt ergeben. Es ist noch nicht in die Realität umgesetzt, aber ich fand es interessant genug, um es hier teilen zu wollen.

Aufgabe
Hier kurz die Ausganslage, für die das Konzept erstellt wurde.
- Mehrere Teams wollen Logs über den Elastic Stack verarbeiten
- Die Logs sind teilweise Debuglogs aus Eigenentwicklungen. (Erfahrene Logmanagement-Admins lesen hier “sich häufig ändernde und nicht immer klar strukturierte Logformate”)
- Die Logmanagement-Admins haben nicht die Kapazität, Logstash-Regeln für alle verwalteten Applikationen zu schreiben und vor allem nicht ständig anzupassen
- Das zentrale Logmanagement ist sehr wichtig und soll durch unerfahrene Anwender nicht gefährdet werden
Lösungsansatz
Im Gespräch hat sich dann ein Setup ergeben, das ungefähr so aussehen soll:
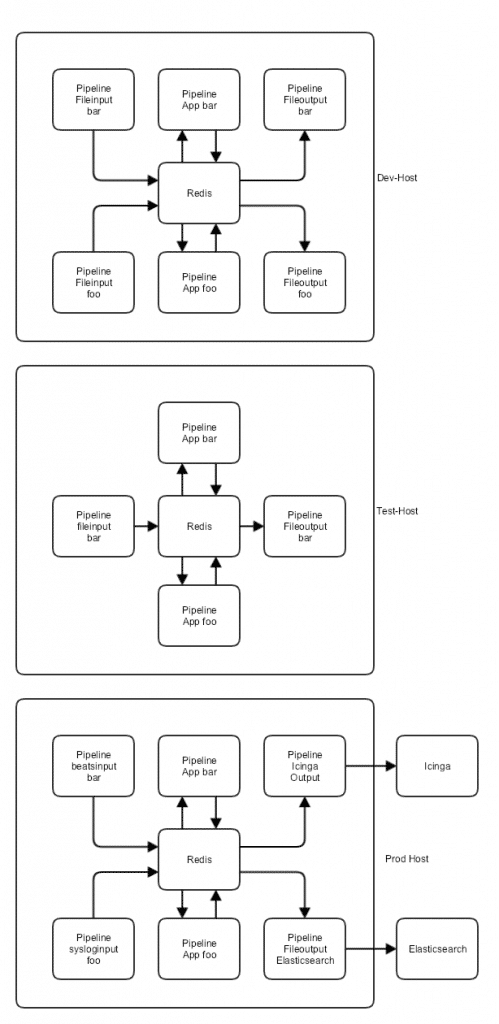
- Es wird eine Entwicklungsmaschine geschaffen, auf der die einzelnen Teammitglieder ssh-Logins bekommen. Auf dieser Maschine ist Logstash installiert, wird aber nicht ausgeführt
- Jedes Team bekommt ein Repository in der zentralen Versionsverwaltung (z.B. GitLab ) und kann das auf der Entwicklungsmaschine auschecken. In diesem Repository befindet sich die gesamte Logstash-Konfiguration einer Pipeline und ggf. Testdaten (siehe weiter unten)
- Die Mitglieder des Teams entwickeln ihre Pipeline und nutzen den lokalen Logstash zum Testen auf syntaktische Richtigkeit.
- Optional können zusätzliche Pipelines zur Verfügung gestellt werden, die Beispieldaten einlesen und wieder in Dateien rausschreiben. Diese beiden Dateien können mit eingecheckt werden, man muss nur darauf achten, sie nicht so zu benennen, dass Logstash sie als Konfiguration ansieht. Es empfiehlt sich, die Beispieldaten aus allen möglichen Logzeilen der Applikation zusammenzusetzen. Bei Änderungen sollten auch alte Zeilen belassen werden, um Logs aller möglichen Versionen einlesen zu können. Sollen die Daten mit Elasticsearch und Kibana veranschaulicht werden, kann in den Beispieldaten ein Platzhalter für den Zeitstempel verwendet werden, der vor dem Einlesen durch die aktuelle Zeit ersetzt wird. Die Pipelines werden einmal eingerichtet und bleiben dann statisch, sie werden nicht von den Teams bearbeitet und befinden sich nicht in zugänglichen Repositories
- Beim Commit der Konfiguration in Git wird ein pre-commit-hook ausgeführt, der nochmal mit Logstash testet, ob die Konfiguration fehlerfrei ist. (Vertrauen ist gut, etc.)
- Ist der Commit gut verlaufen, wird nach dem Push ein CI Tool wie Jenkins benutzt, um die aktuellen Stände sämtlicher Pipelines auf einer Testmaschine auszurollen. Dort wird Logstash dann kurz gestartet, mit fest konfigurierten Pipelines, die Daten einlesen und ausgeben. Statt wie auf einem Produktionssystem Ports zu öffnen und an Elasticsearch oder Icinga zu schreiben, werden die Logdaten aus den eingecheckten Dateien mit Beispieldaten gelesen und in Dateien geschrieben. Dabei ist es wichtig, dass alle Daten von allen Teams in die selbe Instanz gelesen werden. Nur so kann verhindert werden, dass sich die Teams gegenseitig “dreinpfuschen”
- Die ausgegebene Dateien werden auf ihre Richtigkeit geprüft. Das klingt aufwändiger als es ist. Es reicht eigentlich, eine funktionierende Konfiguration mit den oben genannten in- und outputs laufen zu lassen und das Ergebnis als Vorlage zu verwenden. Diese Vorlage wird dann mit dem tatsächlichen Ergebnis verglichen. Arbeiten die Teams schon im ersten Schritt mit den optionalen In- und Outputdateien, kann dieser Punkt stark vereinfacht werden, da man davon ausgehen kann, dass jeder seine eigenen Outputdateien schon berichtigt hat und sie nur mehr geprüft werden müssen
- Abweichungen von der Vorlage werden überprüft und danach entweder die Logstash-Konfiguration erneut angepasst oder die Vorlage angepasst, sodass weitere Tests erfolgreich sind
- War der Test erfolgreich, kann die Konfiguration getagged und auf den Produktionsservern ausgerollt werden
Weitere wichtige Punkte
Hier noch ein paar Punkte, die beim Umsetzen helfen sollen.
- Logstash kann mit der Option -t auf der Shell gestartet werden. Dann prüft er nur die Konfiguration und beendet sich gleich wieder. Das kann auch in der logstash.yml hinterlegt werden
- Um letztendlich zu verhindern, dass zwei Teams das selbe Feld mit unterschiedlichem Typ schreiben muss extra Aufwand betrieben werden. Entweder muss sich jeder an eine bestimmte Nomenklatur halten, oder jedes Team bekommt ein eigenes Feld und darf nur Unterfelder davon anlegen oder jedes Team schreibt in einen eigenen Index
- Wenn jedes Team eine eigene Pipeline mit eigenem Input und Output bekommt, kann die Gefahr einer gegenseitigen Beeinflussung minimiert werden. Das ist aber nicht immer möglich oder sinnvoll. Oft schreibt ein Beat Logs von verschiedenen Applikationen oder es gibt nur einen gemeinsamen UDP/TCP input für syslog.
- Jedes Team kann sich nach wie vor die eigene Konfig zerstören, aber mit dem oben geschilderten Setup kann man ziemlich umfassend sicherstellen, dass auch wirklich jeder nur seine eigene Konfig zerlegt und nicht alle anderen in den Tod reisst.
- Die von den Teams verwalteten Pipelines haben jeweils nur einen Input aus einem Messagebroker (z.B. Redis) und einen Output ebenfalls in einen Messagebroker. Das kann der selbe sein, wobei dann darauf zu achten ist, dass der verwendete key ein anderer ist. So kann auf den verschiedenen Maschinen jeweils eine völlig andere Pipeline in den Broker schreiben oder raus lesen. Auf den Entwicklungsmaschinen wären es Pipelines, die mit Dateien interagieren, auf der Produktion dagegen z.B. ein beats input und ein elasticsearch output. Diese ändern sich ja nicht und können weitgehend statisch bleiben.
- Das ganze ist momentan ein Konzept. Es kann natürlich sein, dass in der Umsetzung noch das eine oder andere Problem auftaucht, das bisher nicht bedacht wurde. Über Feedback würde ich mich auf jeden Fall freuen.

Thomas Widhalm
Manager Operations
Pronomina: er/ihm. Anrede: "Hey, Du" oder wenn's ganz förmlich sein muss "Herr". Thomas war Systemadministrator an einer österreichischen Universität und da besonders für Linux und Unix zuständig. Seit 2013 ist er bei der NETWAYS. Zuerst als Consultant, jetzt als Leiter vom Operations Team der NETWAYS Professional Services, das unter anderem zuständig ist für Support und Betriebsunterstützung. Nebenbei hat er sich noch auf alles mögliche rund um den Elastic Stack spezialisiert, schreibt und hält Schulungen und macht auch noch das eine oder andere Consulting zum Thema. Privat begeistert er sich für Outdoorausrüstung und Tarnmuster, was ihm schon mal schiefe Blicke einbringt...

















0 Comments