Was sind nochmal P-States?
TLDR: P-States sind Performance-States. Wer sich mit der offiziellen Linux-Kernel Dokumentation auseinandersetzt, findet zusammengefasst das moderne Prozessoren in verschiedenen Abständen Frequenz- und Spannungskonfigurationen vornehmen, die auch ‚Operating Performance Points‘ oder auch P-States genannt werden (obwohl man hier korrekterweise eigentlich nach CPU-Architektur & Generation unterscheiden müsste), um Leistung und Stromverbrauch zu bestimmen. Im Linux Kernel findet man hierzu das CPUFreq-Subsystem das aus drei Layern besteht: Dem Kern, Scaling-Governorn und Scaling-Treibern. Während Scaling-Governer Algorithmen zur Abschätzung künftiger Leistung da sind, kommunizieren Scaling-Treiber mit der Hardware.
Vorab: Überprüfe bitte, dass Tuned & TLP nicht stören (sollten diese extra installiert worden sein). Unter Linux befindet sich das CPUFreq Verzeichnis unter /sys/devices/system/cpu und für cpu0 unter /sys/devices/system/cpu/cpu0/cpufreq/

Einfach mal ein cat auf die oben gelisteten Dateien werfen und schauen was das eigene Gerät so bietet. Zum Beispiel könnte man sich die scaling_available_governors (das braucht man für später) anschauen. Noch cooler, durch die „Everything is a file“-Philosophie bei Unix ist es jetzt direkt möglich die scaling_min_freq zu überschreiben und sofort hochzutakten! Wichtig ist nur zu wissen, dass die Werte in KHz angegeben werden.
- Beispiel: Bei mir sind in jenem scaling_min_freq 800000 KHz eingetragen was also 0.8 GHz entspräche.
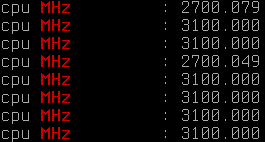
- Ich ändere mal den Wert in 2.7 GHz um nicht unter 2.7 GHz zu takten, danach lasse mir im Anschluss das Ergebnis zur Prüfung anzeigen (nur zu Demozwecken):
Als Root:
echo 2700000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq && cat /proc/cpuinfo | grep MHz
Warum manuell schalten oft besser sein kann:
Die meisten Geräte laufen meiner Erfahrung nach unter einem powersave statt einem performance-Profil was manche Desktop-Erweiterungen anzeigen.
- Das kann natürlich beim sofortigen Browseröffnen mit mehreren Tabs (plus mehreren Extensions), oder Snaps oft zum Ruckeln führen da es auch für gute Governor Profile sehr schwer ist alles mit einzubeziehen.
- Selbiges betrifft oft auch Wifi & Bluetooth-Chipsätze, die mit individuelleren Performance-Tweaks sowie dem Abschalten des Anderen (fast immer teilen sich beide den Chip) auf einmal wesentlich besser oder stromsparender laufen.
- Wenn Du auf längeren Reisen unterwegs bist drehst Du einfach die Frequenz auf ein Minimum runter (ohne irgendeine Chance auf höhere Frequenzen) um auf höhere Batterielaufzeiten zu kommen.
- Nicht jedes Gerät unterstützt CPU Governor wie ondemand oder conservative wobei ersteres aggressiver, schneller und genauer arbeitet und letzterer entspannter, langsamer und ungenauer. Willst du wirklich nur powersave ausgesetzt bleiben?
Du scheinst zu wissen worauf ich nun hinaus will, es ist gut zu wissen wie man selbst schaltet, und das am besten sicher, ohne dauernd das Root-Passwort einzugeben müssen und mit Hotkey? Hier mein Ansatz:
Der Plan:

- Teil 1: Du installierst Dir die entsprechenden Distributions-Kernel-Module.
- Teil 2: Du legst Dir als Root-Benutzer unter /usr/local/bin 6 Dateien an. Somit teilst Du deine CPU Leistung in sinnvolle Profile ein (ein Beispiel folgt), während der eigentliche Nutzer in diese Skripte nicht schreiben darf.
- Teil 3: Du gibst jenem Benutzer die Möglichkeit diese Skripte ohne Passwortabfrage auszuführen.
- Teil 4: Du legst dir 6 Hotkeys an: 4 für die Skripte sowie 2 für powersave und performance.
Teil 1
- Packte installieren:
Fedora:
sudo dnf install kernel-tools
Ubuntu:
sudo apt install linux-tools-5.8.0-63-generic #(Ubuntu will an dieser Stelle die genaue Kernelversion zum Packet wissen, und macht dir einen Vorschlag)
Testen ob es funktioniert, nun solltet du einen Frequenzwechsel der Kerne zurückbekommen:
sudo cpupower frequency-set -g powersave sudo cpupower frequency-set -g performance
Teil 2
- Ab jetzt bitte unter Root arbeiten: Hier erstellst und legst Du in einem Benutzerverzeichnis für Skripte 6 zusätzliche Performanz-Profile an (low, medium, high, max, powersave & performance) und machst diese im Anschluss ausführbar.
- In folgendem Codeabschnitt ersetzt du min und max je pro Profil also 8x: Angenommen deine CPU hätte 4,2 GHZ Maximum, eine sinnvolle Einteilung in 1 GHz Abständen könnte so aussehen. (min=Minimum ist und max=Maximum):
cd /usr/local/bin && touch cpu{low,mid,high,max,performance,powersave}.sh;
echo $'#!/bin/bash\ncpupower frequency-set --min 800000 --max 1500000' > /usr/local/bin/cpulow.sh;
echo $'#!/bin/bash\ncpupower frequency-set --min 1500000 --max 2500000' > /usr/local/bin/cpumid.sh;
echo $'#!/bin/bash\ncpupower frequency-set --min 2600000 --max 3500000' > /usr/local/bin/cpuhigh.sh;
echo $'#!/bin/bash\ncpupower frequency-set --min 3600000 --max 4200000' > /usr/local/bin/cpumax.sh;
echo $'#!/bin/bash\ncpupower frequency-set -g performance' > /usr/local/bin/cpuperformance.sh;
echo $'#!/bin/bash\ncpupower frequency-set -g powersave' > /usr/local/bin/cpupowersave.sh;
cd /usr/local/bin && chmod +x cpu{low,mid,high,max,performance,powersave}.sh
Teil 3
- Rechte setzen via: visudo
- Hier ersetzt Du folgendes: Dein_Benutzername=Deinen Benutzernamen
#Eigene CPU-Frequenz Profile für Benutzer: Dein_Benutzername
Dein_Benutzername ALL=(root) NOPASSWD: /usr/local/bin/cpulow.sh, /usr/local/bin/cpumid.sh, /usr/local/bin/cpuhigh.sh, /usr/local/bin/cpumax.sh, /usr/local/bin/cpuperformance.sh, /usr/local/bin/cpupowersave.sh
Teil 4
Hotkeys legen ist je nach Desktop-Umgebung anders, die Logik dahinter aber gleich: Immer gibt es irgendwo ein Feld oder eine Konfigurationsdatei in die man reinschreibt: Zum Beispiel unter XFCE4 via Keyboard->Application Shortcuts. Ich lege mir hier meine 6 Skripte auf die Windows/Super-Tasten {1-6}.
Super+1 = sudo -u root /usr/local/bin/cpulow.sh Super+2 = sudo -u root /usr/local/bin/cpumid.sh Super+3 = sudo -u root /usr/local/bin/cpuhigh.sh Super+4 = sudo -u root /usr/local/bin/cpumax.sh Super+5 = sudo -u root /usr/local/bin/cpuperformance.sh Super+6 = sudo -u root /usr/local/bin/cpupowersave.sh
Lust auf mehr? Meine Ausbilder bei Professional Services bringen mir später in der Ausbildung noch mehr zu Thema Performance-Tuning bei und können Dir helfen das letzte bisschen Leistung aus Deiner Open Source Infrastruktur herauszuholen.



















